Modeling readability to improve unit tests 🔗
🧪 Tests
📚 Nous savons depuis Buse&Weimer que la lisibilité d’un code dépend de facteurs quasi-universels et qu’une métrique de lisibilité peut être calculée. Vaut-elle pour les tests ? Oui. Peut-elle être améliorée en y ajoutant des règles de lisibilité spécifiques ? Certainement.
🧪 Une équipe de chercheurs a vérifié l’influence de paramètres propres aux tests sur la lisibilité de ceux-ci par des humains : nombre d’assertions, gestion des exceptions, types de données des paramètres, etc. Pour cela, ils ont généré des jeux de tests, que des humains ont du comparer. Chaque évaluateur a indiqué sa préférence et a été chronométré alors qu’il devait expliquer ce que faisait le test.
🏷️ Sans aucune surprise, la qualité du nommage est le facteur le plus important. Attention cependant : un test lisible (readable) n’est pas toujours un test compréhensible (understandable), mais c’est une première étape.
SOURCE
Ermira Daka, José Campos, Gordon Fraser, Jonathan Dorn, and Westley Weimer. 2015. Modeling readability to improve unit tests. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015). Association for Computing Machinery, New York, NY, USA, 107–118. DOI:10.1145/2786805.2786838
📄 Lien public
DOIs:
10.1145/2786805.2786838
An empirical investigation on the readability of manual and generated test cases 🔗
🧪 Tests
🧌 Sur un échantillon de projets open source, le score de lisibilité des tests est toujours plus bas que celui du code. Ce score est calculé à l’aide des indicateurs de Buse&Weimer, standards dans la recherche.
🤷 Est-ce un problème de patterns ? De culture ? De désintérêt ? Les chercheurs ne peuvent qu’émettre des hypothèses. C’est dommage quant on sait l’importance des tests : sans eux impossible de sécuriser un refactoring du code pour en augmenter la lisibilité.
SOURCE
Giovanni Grano, Simone Scalabrino, Harald C. Gall, and Rocco Oliveto. 2018. An empirical investigation on the readability of manual and generated test cases. In Proceedings of the 26th Conference on Program Comprehension (ICPC ‘18). Association for Computing Machinery, New York, NY, USA, 348–351. DOI:10.1145/3196321.3196363
📄 Lien public
DOIs:
10.1145/3196321.3196363
Software Testing With Large Language Models: Survey, Landscape, and Vision 🔗
🧮 Méthodes de développement
📚 En 2024, une équipe internationale a produit une revue de littérature sur l’usage des LLM dans les tests. Voici leurs conclusions :
- La génération de tests complets par des LLM n’est pas satisfaisante en l’état. Les résultats oscillent entre des tests plausibles mais incorrects et une couverture de code très faible.
- La génération d’assertions seules, dans des tests existants, donne des résultats comparables à ceux d’un développeur humain. Autrement dit, les LLM sont efficaces pour vérifier la validité de la sortie d’un morceau de code.
- Les LLM peuvent compléter les fuzzers pour générer des variantes de tests existants. Ils détectent des bugs que les fuzzers traditionnels ne couvrent pas, en particulier lorsqu’ils sont alimentés par les résultats d’outils de mutation testing.
- Les LLM peuvent dédoublonner des bugs et effectuer un triage sommaire, facilitant la vie des mainteneurs.
- Les LLM identifient relativement bien la cause des bugs, mais ne parviennent à en corriger qu’une faible proportion, et ce au prix d’un coût computationnel élevé.
🎯 Les auteurs notent d’importants biais dans certains résultats. Le plus problématique est la fuite de données de benchmark : les LLM ont probablement été entraînées sur des jeux de données contenant les cas de test utilisés pour les évaluer. C’est comparable à un étudiant ayant accès au sujet d’examen à l’avance.
🌉 Le passage du laboratoire à la réalité est difficile : les modèles deviennent rapidement obsolètes, et l’infinité des prompts possibles rend les résultats peu reproductibles pour un praticien. Cette difficulté est accentuée par le fait que la recherche se concentre surtout sur les tests end-to-end et unitaires, en délaissant les tests d’intégration et d’acceptation, pourtant souvent les plus utiles. Les tests de performance ou d’accessibilité sont quasiment absents de la littérature.
🧾 Le papier est difficile à lire, car les auteurs ne distinguent pas clairement les études solides des simples tentatives. J’ai écarté les passages qui ne présentaient pas de résultats clairs. Il n’est pas improbable que les études mentionnées dans cette revue de littérature soient recensées ici à l’avenir.
SOURCE
Wang, Junjie, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang and Qing Wang. “Software Testing With Large Language Models: Survey, Landscape, and Vision.” IEEE Transactions on Software Engineering 50 (2023): 911-936. DOI:10.1109/TSE.2024.3368208
📄 Lien public
DOIs:
10.1109/TSE.2024.3368208
Finding errors in .net with feedback-directed random testing 🔗
🧪 Tests
🎲 Le random testing est-il capable de trouver des bugs sur un composant déjà extrêmement bien testé ? Pour le savoir, un chercheur du MIT a collaboré avec Microsoft, pour avoir accès à l’un des composants les mieux testés de l’environnement .NET. 40 ingénieurs ont déjà qualifié ce composant, jugé extrêmement robuste.
🔎 L’usage de tests générés aléatoirement à partir du code ont permis de trouver 30 erreurs classées comme sérieuses en moins de 15h de travail. Mieux, des erreurs ont été détectées dans l’outillage de test lui-même, qui était incapable de vérifier certains scénarios correctement. La random testing est un excellent oracle permettant d’évaluer la qualité d’une démarche de test, pour un coût modique.
SOURCE
Pacheco, Carlos, S. Lahiri and Thomas Ball. “Finding errors in .net with feedback-directed random testing.” International Symposium on Software Testing and Analysis (2008). DOI:10.1145/1390630.1390643
📄 Lien public
DOIs:
10.1145/1390630.1390643
Test Code Quality and Its Relation to Issue Handling Performance 🔗
🧪 Tests
🤔 La qualité des tests n’a pas d’influence sur le temps passé à résoudre des issues. Ce résultat peut sembler surprenant, mais il s’explique à la lecture d’une étude approfondie sur le sujet.
📊 D’abord, les chercheurs ont construit un indicateur de qualité des tests en agrégeant plusieurs métriques existantes. Ils ont ensuite comparé ce modèle à des évaluations manuelles réalisées par des experts recrutés pour l’occasion. Le risque de biais méthodologique semble donc limité.
🧩 Les travaux antérieurs montrent que la maintenabilité d’un logiciel est fortement corrélée au temps nécessaire pour résoudre ses issues. Rien d’étonnant : à complexité égale, corriger un code clair est plus simple que naviguer dans un bourbier. Nous savons également qu’une meilleure qualité des tests permet d’identifier plus rapidement l’origine d’un problème.
🐛 Si les développeurs identifient plus rapidement la cause d’un problème, pourquoi les issues ne sont-elles pas résolues plus vite ? Selon les chercheurs, les projets bien testés éliminent déjà la plupart des bugs simples. Les issues qui subsistent sont donc plus complexes et demandent davantage de temps pour être corrigées.
SOURCE
Athanasiou, Dimitrios & Nugroho, Arifin & Visser, Joost & Zaidman, Andy. (2014). Test Code Quality and Its Relation to Issue Handling Performance. Software Engineering, IEEE Transactions on. 40. 1100-1125. DOI:10.1109/TSE.2014.2342227.
📄 Lien public
DOIs:
10.1109/TSE.2014.2342227
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? 🔗
🧮 Méthodes de développement
🧪 Les LLM les plus avancés pourraient-elles résoudre des issues sur GitHub, en remplacement des contributeurs ? Avant de vous présenter les résultats obtenus par des chercheurs de Princeton, parlons de la manière dont ils ont construit un benchmark pertinent.
🧰 Les chercheurs ont choisi des projets Python populaires, ce qui introduit déjà un biais de sélection. Les PR tendent à être bien plus claires et complètes que sur des repos plus petits et obscurs. L’ensemble des PR de ces repos sont scannées et filtrées pour ne retenir que celles dont la solution acceptée contient de nouveaux tests.
🧷 Les tests de la solution sont extraits, ils serviront à valider le travail du LLM. LLama, ChatGPT 3.5 et 4 et Claude 2 sont comparés sur cette tâche.
📉 Les résultats sont décevants : le meilleur modèle, Claude 2, ne parvient pas à dépasser les 1.97% d’issues résolues correctement. Une réplication ultérieure avec Claude 3 Opus obtient 3.79%.
🖼️ Une partie de l’explication est contextuelle : beaucoup d’issues comportent des images, que l’outil de benchmark ne parvient pas à faire lire au modèle. Ce n’est que 2% des issues.
🧵 La taille du contexte des LLM est également une barrière, sur des gros repos, les modèles de l’époque étaient bien incapables de localiser correctement le code problématique. En ne leur donnant que les fichiers édités par la véritable P.R, le score de résolution passe à 5.93% sur Claude 2.
🛂 Même en prenant en compte ces facteurs, le score reste faible, d’autant que la résolution d’une issue engage le contributeur : sans une fiabilité proche de la perfection, utiliser un LLM ne peut servir qu’à débroussailler un problème, la validation manuelle reste toujours nécessaire.
SOURCE
Jimenez, Carlos E., et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv, 2024, DOI:10.48550/arXiv.2310.06770
📄 Lien public
DOIs:
10.48550/arXiv.2310.06770
An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation 🔗
🧪 Tests
🧪 Si l’on demande à des LLM de générer des tests unitaires couvrant un programme, le résultat ressemble peu ou prou à ce qu’un développeur moyen ferait : un statement coverage médian de 70%, un branch coverage médian de 53%.
📊 Ce score seul ne nous apprend rien, il est connu depuis des décennies qu’un bon coverage n’est pas un indicateur fiable de la qualité des tests. Aussi les chercheurs ont calculé une deuxième métrique : le pourcentage d’assertions triviales. Sur l’ensemble des projets, la médiane est de 39% de tests générés qui ne vérifient rien d’utile. C’est énorme.
⚠️ Le verdict s’alourdit lorsque l’on considère les tests non-passants, une métrique discrètement écartée par les chercheurs : seuls 44% des tests sont à la fois passants et non-triviaux. C’est un score décevant.
🧠 Les LLM sont capables de générer des tests donnant l’illusion de fonctionner, c’est bien plus dangereux que si les tests étaient manifestement mauvais. Des développeurs n’y prenant pas garde pourraient condamner leur projet en vérolant sa base de tests. Les auteurs semblent très optimistes quant à la capacité des LLM à générer de tests. Ils repoussent l’évaluation de la qualité de ceux-ci à un article ultérieur.
SOURCE
Schäfer, M., Nadi, S., Eghbali, A., and Tip, F. 2023. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation. arXiv preprint arXiv:2302.06527. DOI:10.48550/arXiv.2302.06527.
📄 Lien public
DOIs:
10.48550/arXiv.2302.06527
Specification Engineering: Foundations for the Future of Software Development (Dagstuhl Seminar 25392) 🔗
🧮 Méthodes de développement
·
👌 Qualité logicielle
🧭 En septembre 2025 le célèbre Dagstuhl a initié un séminaire sur le thème des spécifications à l’ère de l’IA. Ce n’est un secret pour personne : le monde des spécifications est une jungle, personne ne s’accorde sur la définition de ce terme, encore moins sur un format unifié. Le code est-il une spécification ? Lâchez cette question dans une réunion de développeurs, les débats seront vifs.
🧠 L’état actuel des LLM ne permet pas de traduire le langage naturel en spécifications formelles. Les spécifications ainsi générées seront syntactiquement valides, mais sémantiquement défaillantes. L’IA ne comprend pas l’abstraction, tout simplement. Je vois les thomistes du fond ricaner.
🗿 Enseigner les spécifications formelles aux étudiants ne donne pas grand-chose, tant ces langages sont abscons et plus proches des mathématiques que la plupart des profils ne peuvent le supporter. Une bonne spécification est utilisable et même si les développeurs pouvaient percer les cryptogrammes de la logique formelle, les experts métiers, ultimes sources de vérité, ne le pourraient pas. Peut-être existe-t-il des progrès à faire pour améliorer ces langages formels, afin de les rendre human-friendly. Peut-être finiraient-ils alors par ressembler … à des langages de programmation de haut-niveau.
🎛️ Le métier de développeur tire sa valeur de l’orchestration de nombreuses tâches. Certaines sont bêtes, facilement vérifiables, donc automatisables, d’autres sont l’essence même du métier de développeur : s’assurer, quitte à y risquer sa peau, que les spécifications sont correctement comprises et implémentées par la machine, à l’aide d’un langage symbolique semi-formel, mémorisable, facile à apprendre et à relire, capable de rendre les erreurs évidentes et plaisant à utiliser.
🔁 Comment s’en assure-t-on ? Un participant ressort l’idée du WYSIWYG, soit une boucle de rétroaction très courte entre le recueil du besoin et la présentation au client. Les esprits taquins appelleraient cela de l’eXtreme Programming. L’histoire bégaie et les révolutions sont étymologiquement un retour au point de départ.
🧪 Mon principal regret par rapport à ce séminaire, est que les tests de haut niveau n’aient pas été pris comme une hypothèse de spécification valable.
🩻 Le principal apport de l’IA pointé par le séminaire est sa capacité à lire le code et à pointer les incohérences et les contradictions laissées par le développeur. Cela semble peu, mais c’est un game-changer.
SOURCE
Marsha Chechik, Eunsuk Kang, Shahar Maoz, Jan Oliver Ringert, and Allison Sullivan. Specification Engineering: Foundations for the Future of Software Development (Dagstuhl Seminar 25392). In Dagstuhl Reports, Volume 15, Issue 9, pp. 160-182, Schloss Dagstuhl – Leibniz-Zentrum für Informatik (2026) DOI:10.4230/DagRep.15.9.160
📄 Lien public
DOIs:
10.4230/DagRep.15.9.160
Human-Agent versus Human Pull Requests: A Testing-Focused Characterization and Comparison 🔗
🧪 Tests
🧬 Les Pull Requests assistées par IA contiennent plus de tests que les P.R manuelles, révèle une analyse portant sur 10 000 P.R. Plusieurs langages sont représentés dans le corpus étudié, de même que plusieurs modèles d’agents différents. Mieux, la quantité de test smells ne varie pas entre les P.R manuelles et les P.R assistées par IA. Aurait-on trouvé un moyen de libérer les développeurs d’une tâche à laquelle ils répugnent souvent ? Pas si vite.
📏 Premier biais : l’étude est purement quantitative. Or, une testbase peut être verbeuse, tout en ne testant pas grand-chose. Les chercheurs n’ont pas évalué le score de mutation obtenu, c’est bien dommage.
🪵 Second biais : les chercheurs notent que les humains tendent à remanier les tests, ce que ne fait jamais l’IA. Elle se contente d’empiler de nouveaux test cases, sans chercher à clarifier ou élaguer l’existant. Or, si les tests sont une spécification, l’IA ne rend pas un grand service en augmentant le volume brut.
🧯 Je suis d’avis de ne pas laisser une chose aussi importante que les tests à l’IA. Elle est bien meilleure lorsqu’on lui demande de générer un code passant des tests que l’inverse.
SOURCE
Milanese, R., Salzano, F., Spina, A., Vitale, A., Pareschi, R., Fasano, F., & Fazzini, M. (2026). Human-agent versus human pull requests: A testing-focused characterization and comparison. arXiv. DOI:10.48550/arXiv.2601.21194
📄 Lien public
DOIs:
10.48550/arXiv.2601.21194
Chaos Engineering 🔗
🧪 Tests
🐒 Si vous voulez prouver qu’un système distribué est tolérant aux pannes, vous devrez essayer de le mettre en panne, en production. Que se passe-t-il si le reverse proxy tombe ? Si une région AWS entière est indisponible ? Les humains ont tendance à esquiver inconsciemment les véritables scénarios problématiques, il faut donc permettre à un robot, le Chaos Monkey, de provoquer des pannes aléatoires en injectant des données erronnées, en ajoutant de la latence ou en coupant des machines. Complétement idiot ? Non, cette technique que l’on appelle Chaos Engineering est utilisée par toutes les organisations qui se préparent sérieusement à l’inattendu. Shit happens.
📝 La manière de mener de telles campagnes de test est assez cadrée. Le papier qui en parle est assez court, je ne ferai que de le paraphraser en le résumant.
SOURCE
A. Basiri et al., “Chaos Engineering,” in IEEE Software, vol. 33, no. 3, pp. 35-41, May-June 2016, DOI:10.1109/MS.2016.60.
📄 Lien public
DOIs:
10.48550/arXiv.1702.05843
STADS: Software Testing as Species Discovery 🔗
🧪 Tests
🕵️ Comment savoir si la recherche de bugs sur un système touche à sa fin ? Avec des entrées complexes, il est manifestement impossible de tout essayer par bruteforce. Le fuzzing consiste à envoyer des données ayant un maximum de chances de provoquer une erreur dans un système. C’est une branche du random testing. Cependant même avec un bon fuzzer, les test peuvent être longs, voire infiniment longs.
🪹 On sait depuis plusieurs décennies qu’un fuzzer remontera des bugs selon un courbe logarithmique : plus le temps passe, moins il y aura de bugs découverts. Comment savoir quand l’énergie consommée par le fuzzer sera plus coûteuse que le retour sur investissement potentiel ?
🦋 Un réponse prometteuse vient de la zoologie, qui a le même genre de problèmes : comment savoir combien d’espèces restent à découvrir sur une zone donnée ? Une formule mathématique permet d’extrapoler le nombre d’espèces restant à découvrir (vues 0 fois) à partir de celles vues une fois et de celles vues deux fois.
🪲 Est-ce applicable aux bugs et autres vulnérabilités ? Oui, mais avec prudence car s’il est facile de savoir si l’on a 2 occurrence du même animal, il est compliqué de dire si deux bugs sont du même type ou non. Cependant la méthode offre des résultats intéressants.
SOURCE
Marcel Böhme. 2018. STADS: Software Testing as Species Discovery. ACM Trans. Softw. Eng. Methodol. 27, 2, Article 7 (April 2018), 52 pages. DOI:10.1145/3210309
📄 Lien public
DOIs:
10.48550/arXiv.1803.02130
On the notion of object 🔗
🔣 Science des Langages
📦 Le concept d’objet dans les langages orientés-objet est difficile à définir. Les divergences entre les différentes “saveurs” d’orienté-objet et le drama entre auteurs explique en partie le problème. Les américains tendent à y voir seulement un mécanisme de modélisation efficace, tandis que les européens tendent à rechercher une certaine esthétique philosophique dépassant la stricte nécessité technique.
🏺 Pour comprendre ce qu’est un objet, il faut étudier la notion sous plusieurs angles, n’ayant pas tous un rapport direct à l’informatique, nous serions même parfois plus proches des mathématiques, de la psychologie et de la philosophie.
😶🌫️ Un objet peut être vu comme une substance attachée à une identité permettant de le distinguer des autres. Toujours dans la même veine ontologique, un objet peut aussi être défini comme l’inverse d’une valeur. Cette dernière est éternelle, immuable, universelle et sans identité. Hélas la plupart des langages ne l’entendent pas ainsi et la moindre valeur, même une primitive, est alors un objet comme un autre. En informatique, “Objet” est un terme équivoque, zut.
🛡️ L’objet peut aussi être défini comme l’inverse des fonctions. La fonction n’a aucune mémoire, elle est pure et sans effet de bord. L’objet stocke un état. Mais ce serait insuffisant car les objets exposent des opérations qui protègent l’état qu’ils contiennent contre l’écriture de valeurs invalides. Parce qu’il n’est pas référentiellement transparent, l’objet est une abstraction, masquant une partie de la complexité qu’il contient derrière une façade : son interface. Hélas encore une fois, le concepte d’abstraction de données et celui d’objet ne sont pas identiques et ne se recouvrent pas complètement. Caramba, encore raté !
🔢 Essayons alors la définition purement technique : un objet est un dictionnaire de propriétés, chacune étant un tableau d’octets que l’on regarde à travers des lunettes qui permettent de l’interpréter. Ce point de vue est probablement le plus exact, mais aussi le plus insatisfaisant, sauf peut-être pour un développeur Javascript.
➗ Essayons alors les mathématiques. Un objet est alors une machine à états finis, possédant des fonctions transformant un état en un autre. L’objet peut être décrit comme un tuple à 4 éléments : son identité, son type, son état actuel et l’ensemble des identifiants y faisant référence. L’identité est immuable, le type l’est souvent, l’état peut varier selon les règles qu’impose le type. Le type peut parfaitement imposer à l’état d’un objet une totale immutabilité, ce qui le rend référentiellement transparent. Les identifiants quant à eux sont un tableau associant des noms à un objet donné.
🧑🏫 Pris isolément, aucun de ces points de vue n’a la moindre utilité pratique au développeur. Tous ces points de vue sont complémentaires et offrent un éclairage complet sur un phénomène bien plus complexe qu’il n’y paraît. L’auteur cite Marvin Minsky : nous ne comprenons rien tant que nous ne l’avons pas appris de plusieurs manières.
SOURCE
Antero Taivalsaari. 1993. On the notion of object. J. Syst. Softw. 21, 1 (April 1993), 3–16. DOI:10.1016/0164-1212(93)90013-N
DOIs:
10.1016/0164-1212(93)90013-N
Microservices tenets: Agile approach to service development and deployment 🔗
🥸 Les microservices ne sont qu’une variante du style Service-Oriented Architecture (SOA). Ils n’ont rien de révolutionnaire. Les technologies ont changé, il est plus “cool” de dire qu’on fait du microservices, mais les contraintes architecturales sont rigoureusement les mêmes.
☁️ La plupart des principes qui gouvernent les microservices sont des reformulations des principes SOA. Le papier argumente fortement dans ce sens. Les microservices n’ont comme vraie nouveauté que les exigences propres à l’environnement cloud-native.
🪤 L’auteur n’évoque pas les pièges mortels du préfixe “micro”, qui n’agrémente pas de manière heureuse le mot de “service”, largement suffisant et ayant fait ses preuves.
SOURCE
Zimmermann, Olaf. (2016). Microservices tenets: Agile approach to service development and deployment. Computer Science - Research and Development. 32. DOI:10.1007/s00450-016-0337-0.
📄 Lien public
DOIs:
10.1007/s00450-016-0337-0
Extending ordinary inheritance schemes to include generalization 🔗
🔣 Science des Langages
🧠 Le mécanisme cognitif que l’on nomme spécialisation nous est familier en programmation. Si un canard est un animal, alors la plupart des langages permettent de dériver un classe canard de la super-classe animal. Le chemin inverse se nomme la généralisation. Aucun langage courant ne propose de mécanisme permettant de créer une super-classe en masquant des propriétés d’une ou plusieurs sous-classes.
🌱 L’auteur propose de créer un tel mécanisme. Sa réfléxion est restée purement théorique, cependant il s’agit probablement de la graine qui donnera ultérieurement le mécanisme d’interface explicite, présent notamment en C# ou en PHP. Une interface explicite peut être déclarée après les classes qu’elle doit unir.
SOURCE
Pedersen, Claus. (1989). Extending ordinary inheritance schemes to include generalization. ACM SIGPLAN Notices. 24. 407-417. DOI:10.1145/74878.74920.
📄 Lien public
DOIs:
10.1145/74878.74920
Looking for a place to hide: a study of social loafing in agile teams 🔗
🧠 Psychologie
😴 Les projets étudiants sont une répétition générale du monde du travail : plus le groupe est nombreux, plus les passagers clandestins pourront délibérément exploiter les autres sans se faire prendre. Le phénomène que je décris ne doit pas être confondu avec l’organisation sous-optimale d’une équipe ou les différences de niveau entre ses membres, qui ne sont pas des pertes de productivité intentionnelles mais accidentelles. Ce phénomène est appelé flânerie sociale, social loafing dans la langue de Chesterton.
😶🌫️ Les méthodes agiles interdisent de mesurer les performances individuelles ou d’affecter des tâches à quiconque. L’équipe est un atome (Whole Team & Collective Ownership en eXtreme Programming). On pourrait s’attendre à voir les parasites se greffer aux équipes agiles comme la misère sur le monde. Les deux cas étudiés par les chercheurs semblent montrer qu’il n’en est rien. Au contraire, les indicateurs individuels semblent plus faciles à “hacker” par les paresseux que les relations humaines d’une équipe agile.
⚠️ L’échantillon est plus que maigre, nous connaissons probablement tous des contre-exemples de cela, aussi ce résultat doit être pris avec prudence.
SOURCE
McAvoy, John and Tom Butler. “Looking for a place to hide: a study of social loafing in agile teams.” European Conference on Information Systems (2006).
📄 Lien public
Better, Not More Expensive, Faster? The Perceived Effects of Pair Programming in Survey Data 🔗
#️⃣ Façonnage de code
🎓 Le Pair Programming divise. Il fallait donc une revue de littérature pour trancher. Sa première conclusion est que nous manquons de données sur des vraies équipes, la plupart des études étant réalisées sur des étudiants. L’hypothèse d’une augmentation massive des coûts, abondamment soutenue par les managers, semble réfutée, même si des études de cas montrent que certaines équipes n’arrivent pas à être efficaces en pair programming. Le pair programming coûte en productivité, mais de manière modérée, ce qui est compensé par les bénéfices de la pratique.
💎 Quels sont ces bénéfices ? L’augmentation de la qualité est réelle, même si les développeurs la perçoivent bien supérieure à ce qu’elle est réellement dans les mesures. La satisfaction des développeurs augmente significativement, ce qui pourrait expliquer une si faible baisse de productivité. Un développeur motivé “glande” moins. Les bénéfices du pair programming semblent amplifiés par les autres pratiques d’XP, mais avec un faible niveau de preuves.
SOURCE
Parsons, D., Hokyoung Ryu and Ramesh Lal. “Better, Not More Expensive, Faster? The Perceived Effects of Pair Programming in Survey Data.” ACIS (2008).
📄 Lien public
A systematic literature review of literature reviews in software testing 🔗
🧪 Tests
🗜️ La littérature sur les tests est abondante, tant en matière d’études primaires que secondaires. Aucune étude tertiaire, effectuant la revue de littérature des revues de littératures, n’existait encore à propos des tests. C’est chose faite et les enseignements sont intéressants.
1️⃣ Première leçon : à l’exception du marronnier MBSE, aucun sujet populaire sur Google n’a fait l’objet de beaucoup d’études secondaires, et inversement. On retrouve ici le vieux sujet du décalage entre praticiens et chercheurs.
2️⃣ Seconde leçon : les études secondaires sur les tests foisonnent à partir de 2009. Cela montre un véritable intérêt de la communauté de recherche pour le sujet, qui est corrélé avec l’intérêt du public pour le sujet.
🎓 Les trouvailles de ce papier gagneraient à inspirer l’ISTQB. Son syllabus brille rarement par la variété et la quantité de ses sources académiques, bien qu’il en possède ce qui est rare dans notre secteur. Même commentaire pour le SWEBOK.
SOURCE
Garousi, Vahid and Mika Mäntylä. “A systematic literature review of literature reviews in software testing.” Inf. Softw. Technol. 80 (2016): 195-216.
📄 Lien public
DOIs:
10.1016/J.INFSOF.2016.09.002
Testing, abstraction, theorem proving: better together ! 🔗
🧪 Tests
🔎 L’analyse dynamique (les tests) ne pourra jamais valider tous les comportements possibles d’un programme : elle sous-approxime. A l’inverse, l’analyse statique tend à sur-approximer et à produire un grand nombre de faux-positifs. Est-il possible de prendre le meilleur des deux mondes ? Des chercheurs proposent un moyen d’y parvenir.
🤖 Les tests sont d’abord exécutés afin d’obtenir un jeu d’états concrets du programme. Ce jeu d’états est généralisé en un jeu d’états abstraits, représentant l’ensemble des états dans lequel le programme peut potentiellement se trouver. Un démonstrateur de théorème automatisé va ensuite vérifier que ce jeu d’états abstrait vérifie certaines propriétés désirables et passe lui-même une version généralisée des tests. Si ça n’est pas le cas, le démonstrateur va générer des contre-exemples permettant au développeur d’augmenter la couverture.
🔧 Je n’ai pas trouvé d’outil appliquant ce principe. Les tests de mutation ont mis 25 ans à passer du laboratoire aux IDE, je pense que les prochaines années verront ce type d’outils venir renforcer nos pratiques.
SOURCE
Greta Yorsh, Thomas Ball, and Mooly Sagiv. 2006. Testing, abstraction, theorem proving: better together! In Proceedings of the 2006 international symposium on Software testing and analysis (ISSTA ‘06). Association for Computing Machinery, New York, NY, USA, 145–156. DOI:10.1145/1146238.1146255
📄 Lien public
DOIs:
10.1145/1146238.1146255
Agility From First Principles: Reconstructing the Concept of Agility in Information Systems Development 🔗
🧮 Méthodes de développement
😶🌫️ L’agilité est au départ un pur label : c’est la mise en commun de la visibilité de plusieurs méthodes autour d’un manifeste flou. Le temps n’a pas aidé à trouver une définition stable, tant le mot est revendiqué par des courants différents. Pire : le mot est antérieur à son usage dans le monde du logiciel. Un consensus se dégage autour de 2 notions : flexibilité et maigreur (leanness). Être Agile serait donc posséder ces deux traits.
🤸 La flexibilité est la capacité à changer de manière réactive ou proactive. Est-ce suffisant pour être agile ? Certainement pas. Une organisation lentement flexible ne sera pas perçue comme agile. L’agilité est également une ouverture au changement : une organisation résiliente, capable de changer au besoin, sans que le changement ne soit accueilli favorablement n’est pas agile.
⚙️ La maigreur est une emphase sur l’économie, la qualité et la simplicité dans la contribution à la valeur perçue par le client. L’inclusion de lean dans l’agilité est problématique : une organisation maigre sacrifie de la résilience pour être la plus efficiente possible. Elle n’est donc pas conçue pour changer, bien au contraire. L’agilité tord quelque peut la définition toyotiste d’origine en cherchant la manière la plus efficiente de produire dans des environnements en perpétuel changement. C’est surtout possible grâce à la nature immatérielle du code.
SOURCE
Conboy, Kieran. (2009). Agility From First Principles: Reconstructing the Concept of Agility in Information Systems Development. Information Systems Research. 20. DOI:10.1287/isre.1090.0236
📄 Lien public
DOIs:
10.1287/isre.1090.0236
Value Creation by Agile Projects: Methodology or Mystery? 🔗
🧮 Méthodes de développement
💵 L’agilité est une chose étrange. Tout le monde parle de “Business Value” mais aucun auteur ne la définit sérieusement. Pour les développeurs, c’est sans doute mieux, car ils peuvent estimer leurs tâches sans retomber dans un culte du mois-homme. Pour le management, c’est bien plus problématique, car ils n’ont qu’un indicateur qualitatif, subjectif et mélangeant la valeur apportée par le logiciel avec celle apportée par le reste des fonctions de l’entreprise.
🤞 Pire, cet indicateur doit être mesuré en se mettant dans la peau du client, mais dans les faits, ce sont toujours des acteurs internes à l’entreprise qui ont ce rôle, avec tout les risques de décalage que cela produit. Une équipe de développement rusée est ainsi poussée à faire plaisir au management, non à un client réel. Formulé en termes économiques, la Business Value n’est pas directement une Dollar Value et la traduction de l’un en l’autre est tout sauf évidente.
🔀 La Business Value est floue, mais est-ce un problème ? Le but de l’agilité est de toujours sortir la tâche la plus prioritaire pour le client à un instant T, rien de plus. Elle n’a pas pour but de compter en valeur absolue, mais d’ordonner en valeur relative. Tout management fait des paris sur ce qu’il comprend du besoin de son client, l’adéquation entre Business Value et Dollar Value, calculée a posteriori, est surtout un bon moyen pour le management de savoir s’il a réussi.
SOURCE
Racheva, Z., Daneva, M., Sikkel, K. (2009). Value Creation by Agile Projects: Methodology or Mystery?. In: Bomarius, F., Oivo, M., Jaring, P., Abrahamsson, P. (eds) Product-Focused Software Process Improvement. PROFES 2009. Lecture Notes in Business Information Processing, vol 32. Springer, Berlin, Heidelberg. DOI:10.1007/978-3-642-02152-7_12
📄 Lien public
DOIs:
10.1007/978-3-642-02152-7_12
Surviving software dependencies 🔗
📐 Architecture
🕵️ Aucune entreprise n’embauche de développeur sans de couteux tests, fréquemment hors-sujet d’ailleurs. Vérification du CV, évaluation du niveau technique, voire véritable enquête de détective pour les plus anxieux. Pourtant, une fois dans l’entreprise, le développeur est parfaitement libre de taper ‘npm install’ ou autre commande similaire. Il fait entrer du code arbitraire comme dépendance du SI, sans que personne ne vienne l’embêter. Le geste est devenu naturel pour les développeurs tant il est facile. Jamais les écoles d’informatique n’abordent le sujet de la gestion irresponsable des dépendances dans notre profession.
😱 Se plaindre de l’irruption de l’IA dans le monde du développement est une panique morale tant que les entreprises ne considéreront pas sérieusement la gestion des dépendances externes de leurs logiciels. Ce papier est un condensé, le minimum vital à connaître pour ne pas mettre en danger son entreprise.
SOURCE
Russ Cox. 2019. Surviving software dependencies. Commun. ACM 62, 9 (September 2019), 36–43. DOI:10.1145/3347446A
📄 Lien public
DOIs:
10.1145/3347446
Historical Roots of Agile Methods: Where Did “Agile Thinking” Come From ? 🔗
🧮 Méthodes de développement
🔎 D’où viennent l’agilité et la mentalité agile ? Les chercheurs ont bien du mal à répondre à cette question, tant le légendaire, l’informel et la reconstruction a priori divergent d’avec les sources authentifiées.
🌀 Beaucoup d’idées viennent évidemment des méthodes “pré-agiles” des années 80-90 comme EVO de Tom Glib ou RAD : le concept de livraison continue à partir d’un MVP et l’objectif ultime de livrer un maximum de valeur au client tirent leur origine de ces méthodes. Il n’est pas impossible que les travaux de Lehman et de Boehm soient indirectement derrière.
📜 Dijkstra et son “Humble Programmer” semble un ouvrage fondateur, au même titre que “Death March” de Yourdon et “The Cathedral and the Bazaar” de Raymond. Rien de scientifique, mais ce sont des ouvrages sapientiaux encore recommandés aujourd’hui.
🧟 Le reste n’a soit aucune origine connue, soit manque de preuves et relève de la légende plus que de l’histoire du logiciel, comme l’origine de Crystal selon Cockburn ou celle d’XP selon Beck.
SOURCE
Abbas, N., Gravell, A.M., Wills, G.B. (2008). Historical Roots of Agile Methods: Where Did “Agile Thinking” Come From?. In: Abrahamsson, P., Baskerville, R., Conboy, K., Fitzgerald, B., Morgan, L., Wang, X. (eds) Agile Processes in Software Engineering and Extreme Programming. XP 2008. Lecture Notes in Business Information Processing, vol 9. Springer, Berlin, Heidelberg. DOI:10.1007/978-3-540-68255-4_10
DOIs:
10.1007/978-3-540-68255-4_10
Exploring the duality between product and organizational architectures: A test of the “mirroring” hypothesis 🔗
🪞 « Toute organisation qui conçoit un système, au sens large, concevra une structure qui sera la copie de la structure de communication de l’organisation. ». Tout le monde connaît la Loi de Conway, que les chercheurs appellent “hypothèse miroir”. Trop peu sont au courant qu’il s’agit d’une hypothèse validée par la recherche en sociologie du logiciel.
🪢 Prenez plusieurs logiciels réalisant une fonction similaire, comparez leurs architectures à la structure des organisation qui les ont développés. Une correlation va se retrouver entre le couplage de l’organisation et la modularité du projet. Les chercheurs avancent des hypothèses pour expliquer cela, mais aucune n’est testée.
SOURCE
Alan MacCormack, Carliss Baldwin, John Rusnak, Exploring the duality between product and organizational architectures: A test of the “mirroring” hypothesis, Research Policy, Volume 41, Issue 8, 2012, Pages 1309-1324, ISSN 0048-7333, DOI:10.1016/j.respol.2012.04.011.
📄 Lien public
DOIs:
10.1016/j.respol.2012.04.011
Exploiting style in architectural design environments 🔗
📐 Architecture
🖌️ Les styles sont au coeur de l’architecture logicielle. Ce sont eux qui définissent les typologies concrètes de connecteurs et de composants, ainsi l’interprétation sémantique à donner aux compositions d’éléments contraints par les règles qu’ils édictent.
🌅 Les styles les plus courants de cette époque n’ont rien de suranné pour le praticien de 2025 :
- Pipes&Filters a retrouvé une jeunesse avec les ETL et les outils Low-Code.
- Le style appelé Real-Time ressemble furieusement à nos architectures réactives.
- Le syle Event-Based, aussi appelé Pub-Sub est simplement partout à l’heure des microservices, pas toujours pour le meilleur.
🔧 Ce papier visait à créer un outil générique permettant de représenter les styles architecturaux, s’il n’a pas survécu, la synthèse de ce concept peut encore nous apprendre beaucoup aujourd’hui.
SOURCE
David Garlan, Robert Allen, and John Ockerbloom. 1994. Exploiting style in architectural design environments. In Proceedings of the 2nd ACM SIGSOFT symposium on Foundations of software engineering (SIGSOFT ‘94). Association for Computing Machinery, New York, NY, USA, 175–188. DOI:10.1145/193173.195404
📄 Lien public
DOIs:
10.1145/193173.195404
Software Architecture 🔗
📐 Architecture
🔬 L’architecture fut d’abord un artisanat, transmis d’architecte en architecte. Les nouveaux styles étaient des variations de styles existants. Les chercheurs vinrent identifier des patterns, afin de théoriser et de rationnaliser cette discipline au cours des années 1990. Le but était d’identifier des styles courants, afin de permettre leur réemploi. Les design patterns devaient bien avoir leur équivalent en architecture.
👓 Des langages descriptifs sont nés, chacun supportant une vue précise de l’architecture. Un même système n’est pas représenté de la même manière par les développeurs, les ingénieurs réseaux et aujourd’hui par les DevOps et les gens du Cloud. Tous sont au moins d’accord sur l’existence de deux choses : des composants et des connecteurs qui les relient.
🏢 L’architecture fut d’abord un artisanat et peut-être aurait-elle dû en rester là, co-évoluant avec les chercheurs. Les années 2000 l’ont vue s’industrialiser. Les styles se sont calcifiés en frameworks, les environnements se sont fermés. L’architecture est passée du jeu de Lego au lit de Procuste. L’autorité normative n’est plus le chercheur, mais celui qui vend son framework au plus d’entreprises possible. Un vaste marché de l’édition et de la formation a terminé de fragmenter la discipline en chapelles. Ce papier date seulement de 2001 et il le déplore déjà.
SOURCE
D. Garlan, “Software Architecture”, Carnegie Mellon University, 2001, doi:10.1002/9780470050118.ecse375
📄 Lien public
DOIs:
10.1002/9780470050118.ecse375
A field guide to boxology: preliminary classification of architectural styles for software systems 🔗
📐 Architecture
📋 Peut-on classer les styles architecturaux comme les design patterns l’ont été dans les années 1990 ? Le travail de Shaw et Clements s’est voulu une première pierre à un tel édifice. 2 familles ont été analysées : Pipes&Filters et Cooperative Message-Passing Processes. Chacune compte plusieurs styles, classés sur 11 critères et brièvement décrits.
🌱 Les auteurs donnent un arbre de décision permettant de choisir le bon style selon les exigences du projet, esquissant un lien qu’approfondira Roy Fielding quelques années plus tard.
🫢 Hélas ce travail reste aujourd’hui sans suite, 30 ans plus tard. Le praticien doit se débrouiller avec des billets de blog approximatifs pour sélectionner un style architectural convenant aux exigences de son projet. Le choix d’un style architectural obéit bien plus aux modes du moment qu’à des critères de décision rationnels.
SOURCE
Shaw, Mary and Paul C. Clements. “A field guide to boxology: preliminary classification of architectural styles for software systems.” Proceedings Twenty-First Annual International Computer Software and Applications Conference (COMPSAC’97) (1997): 6-13. DOI:10.1109/CMPSAC.1997.624691
📄 Lien public
DOIs:
10.1109/CMPSAC.1997.624691
Reconciling the Needs of Architectural Description with Object-Modeling Notations 🔗
📐 Architecture
🙅 UML est-il un bon langage pour représenter l’architecture ? Non, pour deux raisons principales. La première est qu’il n’offre aucune manière meilleure que les autres de représenter les composants, les connecteurs et les notions associées en UML. La seconde est que parmi toutes les manières de faire, aucune ne permet de restituer fidèlement ces concepts dans leur intégralité.
😶🌫️ Il n’est pas interdit d’utiliser UML, le monde de l’architecture est une jungle sans standards véritables, mais il vaut mieux être conscient de ses limites et définir d’entrée de jeu une manière non-ambigüe de représenter les éléments de l’architecture.
SOURCE
Garlan, David & Cheng, Shang-Wen & Kompanek, Andrew. (2002). Reconciling the needs of architectural description with object-modeling notations. Sci. Comput. Program.. 44. 23-. DOI:10.1016/S0167-6423(02)00031-X.
📄 Lien public
DOIs:
10.1016/S0167-6423(02)00031-X
The golden age of software architecture 🔗
📐 Architecture
·
👔 Avis d'expert
🔎 L’architecture logicielle est née dans la seconde moitié des années 80. Il s’agissait pour les chercheurs d’identifier les solutions que les praticiens avaient imaginées pour orchestrer des systèmes logiciels comportant de nombreux modules. La théorisation, d’abord balbutiante, s’est faite dans les années 1990. Le fouillis qu’est encore aujourd’hui l’architecture, où cohabite bullshit et pépites, vient de cette théorisation parcellaire et a posteriori.
🌟 Les années 2000 sont qualifiées d’âge d’or de l’architecture par les auteurs de cet article de synthèse. Les premiers standards sont établis, les premières formations sont dispensées et les éditeurs vomissent des dizaines de livres plus ou moins inspirés. Il aura fallu 20 ans. Quiconque connaît la manière dont les technologies maturent ne sera pas surpris.
🚀 Notre papier du jour a été publié en 2006. Ses auteurs n’ont pas connu le désamour des développeurs pour l’architecture dans les années 2010, ni sa réappropriation actuelle, sous l’impulsion du mouvement craft. Quelle sera la suite de l’histoire ? A nous de l’écrire, en espérant qu’elle se fasse sans UML, déjà qualifié d’erreur dans ce papier.
SOURCE
M. Shaw and P. Clements, “The golden age of software architecture,” in IEEE Software, vol. 23, no. 2, pp. 31-39, March-April 2006, DOI:10.1109/MS.2006.58
📄 Lien public
DOIs:
10.1109/MS.2006.58
Classes versus prototypes in object-oriented languages 🔗
🔣 Science des Langages
🤯 L’idée de baser l’orienté objet sur des prototypes plutôt que sur des classes date de 1986. C’est une réaction à l’introduction des métaclasses en Smalltalk, concept jugé très peu intuitif (les pythonistes modernes témoigneront). Borning affirme que les classes des langages orientés-objet portent bien trop de responsabilités : générateurs d’instances, descripteurs de protocoles, descripteurs de représentation, etc.
📑 La solution proposée est d’abolir les classes. Tout nouvel objet est la copie d’un ancien, qui peut ensuite être modifié à loisir. Cette copie peut être indépendante de la source, ou lui être liée par des contraintes. Ces contraintes peuvent lier ensemble les champs, le comportement ou le protocole des deux objets. Une copie contrainte sur les trois se nomme un descendant.
🚫 Aucune étude, même sur des étudiants, n’a été effectuée avant d’affirmer que ce modèle est plus clair que la POO “vanilla” ou les métaclasses. Pourtant l’auteur affirme qu’ayant moins de concepts à apprendre, le débutant sera moins perdu. Celui-ci est pourtant clairvoyant sur les défauts de sa proposition : elle n’est pas naturelle pour les pures abstractions comme les nombres. Quel est l’entier prototypal ? 0 ou 1 ? Un prototype de Stack ou de Queue fait-il sens ? Enfin, à l’époque, le copy-on-write n’existait pas et les performances d’un langage à prototype n’auraient pas été flamboyantes.
🏛️ La philosophie aristotélico-thomiste est gravée dans nos têtes d’occidentaux, pour le meilleur et pour le pire. Sortir de cette dualité objet/concept est une impasse en programmation, car cette dualité nous est enseignée depuis notre enfance. Qu’elle soit naturelle ou culturelle importe peu à ce stade.
SOURCE
A. H. Borning. 1986. Classes versus prototypes in object-oriented languages. In Proceedings of 1986 ACM Fall joint computer conference (ACM ‘86). IEEE Computer Society Press, Washington, DC, USA, 36–40. DOI:10.5555/324493.324538
📄 Lien public
DOIs:
10.5555/324493.324538
Contracts: specifying behavioral compositions in object-oriented systems 🔗
🔣 Science des Langages
📃 Les contrats ont été inventés en 1990 afin de compléter les interfaces des classes. Ces dernières donnent les signatures des méthodes exposées par une classe, mais ne disent rien du comportement que chacune des parties attend de l’autre. Les commentaires sont largment insuffisants, car il faut que de telles spécifications soient exécutables.
🌱 La première idée émise par les chercheurs fut d’intégrer les contrats dans les langages de programmation eux-mêmes. Cette idée n’a pas pris, mais les contrats sont loin d’être morts ! Les tests fonctionnels sont les héritiers directs de ce morceau d’histoire du logiciel. Plus éloignés, certains types de foncteurs (Maybe, Lazy, Either, …) ou les systèmes de Tasks/Promises peuvent se rattacher à des contrats.
SOURCE
Richard Helm, Ian M. Holland, and Dipayan Gangopadhyay. 1990. Contracts: specifying behavioral compositions in object-oriented systems. SIGPLAN Not. 25, 10 (Oct. 1990), 169–180. DOI:10.1145/97946.97967
📄 Lien public
DOIs:
10.1145/97945.97967
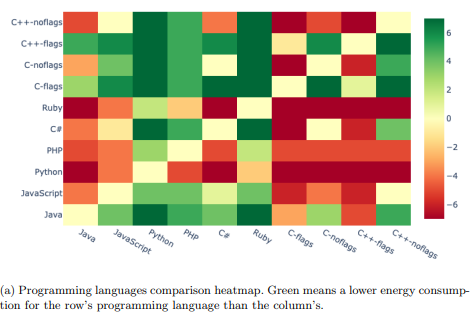
Green code : towards measuring the efficiency of software system execution 🔗
🪫 Comment produit-on un logiciel économe en énergie ? Sans surprise, il faut déjà que le besoin en soit exprimé. C’est une exigence non-fonctionnelle et aucun développeur ne s’en préoccupe si ça n’est pas formulé sous forme d’objectifs chiffrés.
📏 Ensuite, il faut que le développeur puisse mesurer la consommation de son programme. Il faut de l’outillage pour cela, notamment en intégration continue. Hélas le papier reste en surface et ne nous dit pas lesquels.
⚡ Mesurer ne sert à rien si l’on ne peut pas agir. Les développeurs doivent se former à repérer les antipatterns énergétiques au niveau architectural, dans le design ou les structures de données. Certains patterns sont connus pour favoriser les économies d’énergie. Problème : certaines bonnes pratiques logicielles semblent alourdir le bilan energétique des projets, comme l’encapsulation, en tout cas sur certains langages. A l’inverse, le bon usage du multithreading permet souvent des économies importantes. Plus surprenant, la pratique du refactoring semble liée à une meilleure efficacité energétique.
👟 Tous les frameworks, bibliothèques et bases de données ne se valent pas, certains sont des gouffres énergétiques, l’auteur note hélas que ce sont souvent les dépendances les plus performantes qui sont aussi les moins efficientes. Cette tension se retrouve également dans les réglages des compilateurs C/C++ où les optimisations les plus aggressives ne sont pas toujours les plus vertes. Sans surprise, la conteneurisation, voire pire la virtualisation sont des gouffres énergétiques.
SOURCE
Rifat, Ahmed, Green code : towards measuring the efficiency of software system execution. School of Engineering Science, Tietotekniikka. 2022.
📄 Lien public
Secure Software Development Methodologies: A Multivocal Literature Review 🔗
🧮 Méthodes de développement
🔒 Les méthodologies de Secured Software Development sont nombreuses, populaires et font même l’objet de normes gouvernementales depuis une demi-décennie. Trois raisons de s’en méfier, donc.
📐 Chercheurs, gouvernements et praticiens s’accordent sur un socle commun de pratiques : évaluation des risques, création d’une culture de la sécurité et standards de code. En dehors de ce noyau commun, les pratiques recommandées divergent.
🤡 Les auteurs de cette revue de littérature relèvent l’absence quasi-totale de justification des pratiques recommandées par ces méthodologies. La charge de la preuve leur incombe, pourtant. Ils notent également l’absence d’évaluation de l’efficacité de telles méthodologies, pointant ironiquement que les entreprises desquelles elles sont issues ont été remarquées pour des hacks massifs depuis la parution de leurs méthodes.
⛓️ Ajoutons que très peu de méthodes envisagent le développeur comme un acteur de la sécurité. Au mieux leur impose-t-on des standards de code et des revues de leur travail par des experts. La plupart des frameworks se contentent de faire de la gestion de risque, à mille lieux de méthodologies de développement, sécurisé ou non.
SOURCE
Kudriavtseva, Arina and Olga Gadyatskaya. “Secure Software Development Methodologies: A Multivocal Literature Review.” ArXiv DOI:abs/2211.16987 (2022)
📄 Lien public
DOIs:
10.48550/arXiv.2211.16987
Hints on Test Data Selection: Help for the Practicing Programmer 🔗
🧪 Tests
🧪 En 1978, quasiment tout ce qu’un développeur de 2025 doit savoir sur les tests avait déjà été dit. Comment sélectionner les cas de test pour éviter le Happy Path Testing ? Goodenough et Gerhart en 1975. L’idée des tests de mutation ? Budd, DeMillo et Lipton en 1978. L’hypothèse du programmeur compétent ? Youngs en 1971. Le rapport logarithmique entre effort de test et découverte de bugs ? Tucker en 1965.
🥊 Ce papier de 1978 vulgarise avec brio tous les concepts susmentionnés. En 2025, personne n’a d’excuses pour les ignorer, sinon un parcours de formation défaillant.
SOURCE
DeMillo, Richard A., Richard J. Lipton and Frederick G. Sayward. “Hints on Test Data Selection: Help for the Practicing Programmer.” Computer 11 (1978): 34-41. DOI:10.1109/C-M.1978.218136
📄 Lien public
DOIs:
10.1109/C-M.1978.218136
Agile Gets Physical : Slice-Based Integration 🔗
👔 Avis d'expert
·
🧪 Tests
🤖 L’agilité fait grincer les dents dans le monde du hardware. Réaliser une carte électronique est tellement long que personne ne s’amuse à ajouter chaque feature itérativement. Ca n’est même pas physiquement possible dans la plupart des cas.
🚧 Le hardware connaît cependant le développement incrémental, c’est là que nous pouvons nous entendre. Avant le produit fini, l’ingénieur conçoit tout un bestiaire de prototypes de plus en plus aboutis, avec lesquels les développeurs peuvent composer pour exécuter les tests du software.
⌚ Peu d’effort est demandé au hardware : seulement de s’aligner sur des jalons convenus avec les développeurs. Chaque jalon spécifie un ensemble de cas d’utilisation que toutes les équipes devront tester ensemble de manière intégrée à une échéance donnée. Chacun retourne travailler après s’être accordé sur une interface commune, permettant le développement de doubles de test propres à chacun. Le jour J, on met en commun et on teste. Les réalignements se font à l’incrément suivant jusqu’au produit fini.
⚠️ Cette méthode semble prometteuse, mais ce papier ne fait que la présenter, sans conduire d’étude prouvant son efficacité.
SOURCE
Iberle, Kathleen (2022). Agile Gets Physical : Slice-Based Integration. PNSQC Proceedings.
📄 Lien public
Encapsulation and inheritance in object-oriented programming languages 🔗
📦 L’orienté-objet moderne ne s’est pas figé du jour au lendemain. Les différences entre les langages actuels portent les cicatrices des débats qui ont eu lieu dans les années 1980, à l’époque où ce paradigme se consolidait. Ces papiers n’ont plus aucun intérêt scientifique, sauf pour les amoureux de l’histoire du logiciel qui y trouveront les minutes des débats qui ont animé la communauté objet.
❓ Alan Snyder explore ici les liens pas si évidents entre héritage et encapsulation. L’enfant doit-il accéder aux parties privées du parent ? Être traité en étranger ? Quelque chose entre les deux (ce qui deviendra le mot clé protected) ? Le fait qu’une classe hérite d’une autre doit-il être une information accessible au reste du programme ? Ces questions ont été tranchées, mais il est toujours intéressant de comprendre le chemin intellectuel qui nous a mené à la situation actuelle.
SOURCE
Snyder, Alan. “Encapsulation and inheritance in object-oriented programming languages.” OOPLSA ‘86 (1986). DOI:10.1145/960112.28702
📄 Lien public
DOIs:
10.1145/960112.28702
Designing Reusable Classes 🔗
👔 Avis d'expert
·
#️⃣ Façonnage de code
🧊 Certains papiers sont des instantanés des erreurs de leur époque et méritent leur place ici principalement pour cela. Le début de celui-ci est une description claire et impeccable de ce qu’est l’orienté-objet à la fin des années 80. Presque rien n’a changé depuis, seulement quelques additions mineures.
🔗 La suite porte sur les frameworks : ils y sont correctement décrits comme étant plus que de simples boîtes à outils. Tout framework lie irrévocablement le code qui l’utilise à une architecture. L’auteur rappelle une distinction aujourd’hui oubliée entre frameworks white-box et black-box, les premiers ayant presque disparu du marché.
✅ La fin du papier liste des “bonnes pratiques” de l’époque, certaines aujourd’hui réfutées. L’usage de hiérarchies d’héritage profondes est recommandée, alors que nous savons désormais que le nombre de niveaux d’héritage est corrélé au nombre de bugs. La création d’un maximum de code générique et même de frameworks y est encouragée, bien que décrite comme dangereuse, afin de réutiliser au maximum le code. Aujourd’hui il est recommandé d’attendre qu’un besoin de réutilisation existe pour entamer une telle démarche.
🧑🔬 Il est dommage que l’auteur n’ait pas cherché de preuves de l’efficacité de ces différentes règles, mais se soit simplement fait l’écho de l’esprit du temps.
SOURCE
Johnson, Ralph & Foote, Brian. (1988). Designing Reusable Classes. Journal of Object-Oriented Programming.
📄 Lien public
Values and objects in programming languages 🔗
🔣 Science des Langages
🗃️ Les familiers de DDD connaissent la distinction Entité/Objet-Valeur. Peu savent qu’Evans n’a rien inventé : en 1982, Bruce McLennan plaidait pour que les langages orientés-objet n’utilisent pas le même mécanisme pour représenter les valeurs et les objets. Les premières sont des abstractions intemporelles et immuables que la programmation partage avec les mathématiques. Les seconds sont des instances partageant une forme commune (leur classe), mais différent en substance (leur identité et leurs accidents).
🧮 En réalité, McLennan non plus n’a rien inventé, il poursuit simplement la longue tradition d’Aristote, de Saint Thomas d’Aquin et des scolastiques. L’orienté-objet n’a rien de neutre, ce paradigme est l’héritier d’une longue tradition philosophique réaliste. Pour McLennan, les mathémathiques sont trop abstraites et incommodes pour représenter les cas particuliers. A l’inverse, un style de programmation qui ignore la distinction valeur/objet se prive d’outils puissants pour représenter l’abstrait, l’immuable, le calculable et donc la simplicité.
🏛️ Ce papier est à ranger parmi les grands classiques de la programmation. “Programmer, c’est faire des mathémathiques orientées-objet. Mathématiser, c’est faire de la programmation orientée-valeur” résume d’auteur.
SOURCE
MacLennan, Bruce J.. “Values and objects in programming languages.” ACM SIGPLAN Notices 17 (1982): 70-79. DOI:10.1145/988164.988172
📄 Lien public
DOIs:
10.1145/988164.988172
Evaluation of Approaches for Documentation in Continuous Software Development 🔗
🧮 Méthodes de développement
·
🧪 Tests
📖 Même un code exemplaire a besoin d’être accompagné d’une documentation. Concevoir c’est faire des choix, qui doivent être consignés quelque part pour être compris dans le futur. A l’heure actuelle, deux approches ont le vent en poupe : “Just enough Upfront” et “Executable Documentation”. Elles sont trop récentes pour en évaluer les résultats, mais il est cependant possible de baliser le terrain et de savoir de quoi il en retourne.
🖼️ Just enough up Front utilise des supports de documentation déstructurés en amont du développement : présentations, description d’interfaces, schémas. Le développement démarre dès que suffisamment d’informations sont récoltées, et utilise l’abstraction pour garder le code extrêmement perméable au changement. La documentation in fine est le code lui-même, ainsi que les messages de commits.
🧪 Executable Documentation utilise massivement les méthodes de recueil du besoin piloté par les tests, les spécifications et exigences exécutables tout au long du cycle de vie du logiciel. Le reverse engineering est une méthode d’extraction de la connaissance adaptée avec une telle couverture du code.
🧭 Tandis que Just enough up Front est déjà bien installé en entreprise, Executable Documentation souffre de l’obsession mondiale pour les tests unitaires, incapables de supporter cette méthode. C’est dommage car les deux méthodes se complètent bien. L’une permet de savoir où l’on va, l’autre de ne pas oublier ce que l’on voulait accomplir.
📍 Git est le lieu parfait pour documenter du code dans le cadre de ces deux démarches, notent les chercheurs. Les messages de commits sont sous-cotés.
SOURCE
Theunissen, Theo & Hoppenbrouwers, Stijn & Overbeek, Sietse. (2023). Evaluation of Approaches for Documentation in Continuous Software Development. 404-411. DOI:10.5220/0011846200003464.
📄 Lien public
DOIs:
10.5220/0011846200003464
Understanding and Detecting Harmful Code 🔗
🦨 Code Smells
🐛 La plupart des odeurs du code ne sont pas corrélées à la présence de bugs et inversement, la plupart des bugs ne sont pas liés à des odeurs du code. Ces deux concepts désignent des réalités différentes. Une seule odeur du code ressort du lot en étant modérément corrélée à l’apparition de bugs : l’appel de méthodes abstraites depuis le constructeur. S’il faut prioriser un refactoring c’est bien celui-ci.
🔎 Le papier vise surtout à améliorer les outils de détection de bugs. En remontant depuis les odeurs jusqu’aux métriques permettant de les détecter automatiquement, les chercheurs en ont sélectionné plusieurs qui sont modérément corrélées à l’apparition de bugs. Rien de surprenant pour un développeur chevronné : nombre excessif de paramètres, nombre excessif de méthodes par classes, complexité ou longueur extrême d’une méthode. Rien de nouveau sous le soleil.
SOURCE
Rodrigo Lima, Jairo Souza, Baldoino Fonseca, Leopoldo Teixeira, Rohit Gheyi, Márcio Ribeiro, Alessandro Garcia, and Rafael de Mello. 2020. Understanding and Detecting Harmful Code. In Proceedings of the XXXIV Brazilian Symposium on Software Engineering (SBES ‘20). Association for Computing Machinery, New York, NY, USA, 223–232. DOI:10.1145/3422392.3422420
📄 Lien public
DOIs:
10.1145/3422392.3422420
Identification and measurement of Requirements Technical Debt in software development: A systematic literature review 🔗
🧮 Méthodes de développement
💰 Depuis Ward Cunningham, le concept de dette technique a été étendu, souvent abusivement. L’une de ses ramifications contemporaines, la dette technique d’exigence (requirements technical debt) désigne tout écart entre les spécifications idéales et les spécifications réelles du projet. On y retrouve l’exclusion de certaines parties prenantes, les mauvaises techniques d’élicitation, l’implémentation non-conforme. Dette ou malfaçon, je vous laisse juges, mais vu que le terme est utilisé en recherche, il faut bien l’accepter pour débattre du sujet.
🤝 Les pricipaux remèdes sont la revue des spécifications par le client (encore faut-il un format qu’il puisse lire) et le recueil du besoin en face à face, non par documents interposés. De vieilles recettes.
🧮 La quantification et la priorisation de la dette technique sont des sujets prometteurs mais complexes. La dette intentionnelle, celle de la définition d’origine, est facile à quantifier et à prioriser. La quantification de dette non-intentionnelle relève de la divination. Le concept recouvre surtout des failles organisationnelles qui n’ont rien à voir avec la métaphore d’une “dette”. La dette technique d’exigences n’en fait pas partie et les auteurs recommandent plus volontiers de prévenir que de quantifier, prioriser et remédier à un recueil du besoin défaillant.
* Le lien redirige vers le dernier preprint, car le papier définitif est derrière un paywall.
SOURCE
Melo, Ana & Fagundes, Roberta & Lenarduzzi, Valentina & Santos, Wylliams. (2022). Identification and measurement of Requirements Technical Debt in software development: A systematic literature review. Journal of Systems and Software. 194. 111483. 10.1016/j.jss.2022.111483.
📄 Lien public
DOIs:
10.1016/j.jss.2022.111483
How Does Modern Code Review Impact Software Design Degradation? An In-depth Empirical Study 🔗
🧮 Méthodes de développement
💣 Les Code Reviews n’empêchent pas l’érosion du design d’un logiciel, voire l’aggravent dans certains cas. Si une review n’est pas explicitement dédiée à l’amélioration du design, mieux vaut d’abstenir d’y toucher. Même lorsqu’une review s’intéresse explicitement au design, elle tend à ne régler que les problèmes localisés et n’a pas d’impact sur les problèmes plus larges, nécessitant le remaniement de nombreux éléments.
🥊 Plus une review est conflictuelle et s’enlise dans les débats, plus le design a de chances d’être dégradé. L’amélioration d’un aspect du design tend de surcroît à se faire au détriment d’autres éléments. Seul l’implication véritablement active de plusieurs reviewers permet de sauver les meubles. A ce prix là, ne serait-il pas plus pertinent de faire directement réaliser le code par plusieurs devéloppeurs ?
SOURCE
Uchôa, Anderson & Barbosa Vieira da Silva, Caio & Oizumi, Willian & Blenilio, Publio & Lima, Rafael & Garcia, Alessandro & Bezerra, C. I. M.. (2020). How Does Modern Code Review Impact Software Design Degradation? An In-depth Empirical Study. DOI:10.1109/ICSME46990.2020.00055.
📄 Lien public
DOIs:
10.1109/ICSME46990.2020.00055
Evolution of Software Testing Strategies and Trends: Semantic Content Analysis of Software Research Corpus of the Last 40 Years 🔗
🧪 Tests
⌚ 40 ans de recherche sur les tests résumés en un papier académique ? Une équipe turco-norvégienne l’a réalisé. Il s’agit ici de recenser les grandes tendances de chaque demi-décennie, de manière quantitative.
🧪 L’intérêt des chercheurs pour les tests naît dans les années 80 où la recherche se concentre sur l’outillage adéquat et la détection des bugs. La décennie 90 a exploré le sujet de la génération des cas de tests. Les années 2000 ont évalué les résultats des différentes approches de manière empirique avant que la décennie qui nous précède ne s’intéresse à la prédiction des défauts. Les chercheurs parient que l’avenir vera des percées dans la sécurité, l’open-source et le mobile.
🗨️ Ce papier est utile pour qui veut connaître les grands courants de la recherche, sans discriminer les papiers qui ont fait école de ceux qui sont tombés dans l’oubli. L’exercice est intéressant mais mériterait une suite où chaque papier est pondéré selon le nombre et la longévité des citations.
SOURCE
Gurcan, Fatih & Menekşe Dalveren, Gonca & Cagiltay, Nergiz & Roman, Dumitru & Soylu, Ahmet. (2022). Evolution of Software Testing Strategies and Trends: Semantic Content Analysis of Software Research Corpus of the Last 40 Years. IEEE Access. PP. 1-1. DOI:10.1109/ACCESS.2022.3211949.
📄 Lien public
DOIs:
10.1109/ACCESS.2022.3211949
Test-Driven Development with the Focus on Inexperienced Programmers: A Literature Review 🔗
🧪 Tests
🧪 Chez les débutants, TDD et TLD permettent d’atteindre une qualité produit similaire. Ces résultats sont confirmés par une revue de littérature de 2022. Celle-ci nous apprend aussi que TDD permet une meilleure couverture de tests que TLD, donc potentiellement une meilleure capacité anti-régression, mais est plus difficile à apprendre. Les pièges sont nombreux pour les débutants en TDD : les étudiants tendent à ne pas comprendre immédiatement la démarche et à ne pas refacto une fois les tests au vert. Ils sont souvent adeptes du happy-path testing, donc de tests peu approfondis. Avec de l’entraînement et un suivi correct, ces problèmes sont rapidement corrigés.
SOURCE
Nyman A, Rimmi O. Test-Driven Development with the Focus on Inexperienced Programmers: A Literature Review. 2022.
📄 Lien public
Iteration Causes, Impact, and Timing in Software Development Lifecycle: SLR 🔗
🧮 Méthodes de développement
🔁 Itérer est toujours une perte de temps et d’argent. Un développeur omniscient recueillant un besoin parfait travaille de manière linéaire. Aucune itération volontaire ne lui est nécessaire, car le problème est bien défini. Il ne cause pas d’itérations involontaires car il produit un code simple, exempt de défauts, adéquat par rapport au besoin, sans aucune ambiguïté.
🧚 Si nous quittons le monde des fées, l’itération est bourrée d’avantages : qualité en hausse donc baisse des défauts, meilleure lisibilité donc meilleure maintenabilité, plus faible complexité donc plus grande productivité, adoption d’une solution plus adaptée au problème et plus innovante. Autrement dit, itérer c’est compenser nos limites bien humaines par une méthode d’amélioration continue. Nous sommes en négociation permanente avec les autres parties prenantes, nous-même et surtout la froide logique des machines.
🪙 La seule raison pertinente de ne pas itérer, c’est de gagner du temps à court-terme, au détriment du temps long. C’est ce que l’on appelle la dette technique.
📚 Voici les conclusions d’une équipe pakistano-saoudienne, qui a réalisé une SLR sur près de 153 études après sélection qualitative.
SOURCE
Mumtaz, Mamoona & Ahmad, Naveed & Ashraf, M. Usman & Alghamdi, Ahmed & Bahadad, Adel & Almarhabi, Khalid. (2022). Iteration Causes, Impact, and Timing in Software Development Lifecycle: SLR. IEEE Access. 10. 1-1. DOI:10.1109/ACCESS.2022.3182703.
📄 Lien public
DOIs:
10.1109/ACCESS.2022.3182703
Debugging reinvented 🔗
🧮 Méthodes de développement
🔍 Une fois localisée l’origine de l’erreur, celui qui débugge doit savoir pourquoi la valeur est erronnée. Les débuggers actuels sont laborieux car ils expliquent quelle est la valeur d’une variable, non qui la lui a donnée. Une équipe de Carnegie-Mellon a conçu un outil fonctionnel permettant de suivre les éditions successives d’une variable afin de répondre à la question la plus chronophage du debug : pourquoi ?
💣 Ils sont mêmes allés plus loin : parfois une valeur devrait changer, mais ne change pas. A l’aide d’heuristiques simples, ils ont pu répondre également à la question “pourquoi pas ?”.
❓ A ce jour, je ne connais aucun outil de debug utilisant ce principe. Quelqu’un en connaît-il un ?
SOURCE
Ko, Amy J. and Brad A. Myers. “Debugging reinvented.” 2008 ACM/IEEE 30th International Conference on Software Engineering (2008): 301-310. DOI:10.1145/1368088.1368130
📄 Lien public
DOIs:
10.1145/1368088.1368130
Finding Failure Causes through Automated Testing 🔗
🧪 Tests
🐛 Une révision fonctionne, alors qu’une autre bugge. C’est presque une routine. Le développeur doit alors rechercher la cause racine du bug et la corriger. L’usage de tests dans ce processus est ancien, bien qu’il ne soit apparu dans la littérature scientifique qu’autour des années 2000. L’idée est simple : reproduire le bug dans un cas de test pour l’empêcher de revenir. C’est le defect testing. Hélas, cette technique n’aide pas à trouver la cause racine, ce qui représente 95% du temps de debug.
🧪 Deux chercheurs allemands proposent d’utiliser les tests afin de repérer la cause racine. Il faut pour cela deux révisions séparées par un delta. Dans la première, le test de défaut fonctionne, dans l’autre celui-ci est cassé. L’étape suivante est de trouver le scénario minimal dans lequel le bug se produit, en diminuant la quantité de changements du delta. Cette étape n’est pas obligatoire, mais réduit largement la quantité de calculs nécessaires ensuite. La dernière étape consiste à muter le code afin de trouver le plus petit jeu de changements provoquant le bug, donc faisant passer au rouge le test de défaut. Cette étape est extrêmement lourde en calculs, car le nombre de mutants à générer et tester est immense.
🗜️ Cette technique n’est pas utilisée en l’état par les praticiens, à ma connaissance. Elle pourrait cependant être à l’origine du shrinking utilisé en property-based testing.
SOURCE
Cleve, Holger and Andreas Zeller. “Finding Failure Causes through Automated Testing.” arXiv: Software Engineering (2000) DOI:10.48550/arXiv.cs/0012009
📄 Lien public
DOIs:
10.48550/arXiv.cs/0012009
The Impact of using a Contract-Driven, Test-Interceptor based Software Development Approach 🔗
#️⃣ Façonnage de code
·
🧪 Tests
📃 La programmation par contrats est impopulaire, malgré ses preuves d’efficacité. Pour la rendre sexy, des chercheurs ont envisagé d’utiliser les contrats comme moyen de générer des tests avant le code, comme alternative à Behavior-Driven-Design. Ils ont évidemment appelé leur découverte Contract Driven Design selon la coutume.
🚧 Des intercepteurs sont utilisés afin de vérifier que les pré-conditions, les post-conditions et les invariants sont respectés sur le composant, dont seule l’interface est visible. Le dépôt git n’étant plus accessible, je n’ai pas pu voir en détail comment ces intercepteurs sont appelés par le moteur de tests, mais l’idée ressemble grosso modo au Property-Based Testing, apparu en 1997 dans la littérature et vers 2015 chez les praticiens.
🤔 PBT a l’avantage de ne pas encombrer le code avec les annotations contactuelles, qui doivent être maintenues et bloquent le refactoring. Ces annotations appartiennent plus naturellement au monde des tests qu’au code. Le second inconvénient, pour qui veut concurrencer BDD, est l’opacité des contrats pour le client, alors que l’intérêt de BDD est justement de pouvoir dialoguer avec lui sur un terrain commun. Enfin, l’expérience contenue dans le papier est très faible, pour ne pas dire qu’elle ne prouve rien.
SOURCE
Posthuma, Justus & Solms, Fritz & Watson, Bruce. (2022). The Impact of using a Contract-Driven, Test-Interceptor based Software Development Approach. 39-58. DOI:10.5121/csit.2022.120704.
📄 Lien public
DOIs:
10.5121/csit.2022.120704
Sources of software development task friction 🔗
🧮 Méthodes de développement
·
#️⃣ Façonnage de code
⌨️ Avez-vous déjà codé sur un PC qui n’est pas le vôtre ? L’inconfort naît de la friction, soit la part du temps de développement passé à gérer l’environnement au lieu de coder, plus grande sur un système qui n’est pas ajusté à nos habitudes. La friction a fortement diminué depuis l’époque des cartes perforées mais reste encore importante. Ce papier de 2022 fait le point.
🤖 Le problème fondamental est la médiation de multiples outils entre notre cerveau et notre code. Si nous pouvions simplement penser pour coder, nous éliminerions la friction de traduction. Si l’ensemble de l’information pertinente était directement dans notre tête, nous n’aurions aucune friction d’intégration. Sans la nécessité de coordonner un navigateur, des post-it, un IDE et un terminal, pas de friction d’accès. Sans friction, moins d’erreurs également, comme les commandes shell invalides ou les “solutions” stackoverflow fausses.
🐧 Les IDE promettent de tout faire à un seul endroit, mais c’est un pieux mensonge : il y a autant de manières de réaliser une tâche que de développeurs. Bienheureux celui qui trouve out-of-the-box le bon outil ! Beaucoup se tournent vers un assemblage hétéroclite d’outils simples, dans l’esprit GNU, ce qui augmente la friction d’accès mais améliore les autres formes de friction.
🪄 La solution miracle n’existe pas, Fred Brooks l’a démontré en 1986 dans “No Silver Bullet”, mais par petits incréments successifs, nous adaptons l’outil à notre cerveau. L’IA peut aider mais elle ne sera pas la panacée.
SOURCE
Bradley, N.C., Fritz, T. & Holmes, R. Sources of software development task friction. Empir Software Eng 27, 175 (2022). DOI:10.1007/s10664-022-10187-6
📄 Lien public
DOIs:
10.1007/s10664-022-10187-6
Detecting Argument Selection Defects 🔗
#️⃣ Façonnage de code
🔀 L’inversion de paramètres d’appel d’une fonction est un défaut courant, qui peut rester indétecté longtemps si la couverture de tests n’est pas bonne. Une équipe germano-américaine comptant des chercheurs de Google a voulu déterminer la meilleure approche pour détecter ce problème à l’aide d’un analyseur statique.
💡 L’outillage qu’ils ont développé obtient un score de détection honorable, mais là n’est pas le principal fruit du papier. Ils sont surtout démontré, si c’était encore nécessaire que l’usage de Builder doit toujours être préféré à des paramètres pléthoriques, qu’il faut respecter les conventions (expected avant actual dans les tests) et que l’héritage doit respecter l’ordre des paramètres.
🫙 J’ajoute que si les développeurs cessaient d’utiliser des primitives au profit de types encapsulés, ils n’auraient même pas à se poser la question. Avec 64% de la profession utilisant JS, c’est une utopie.
SOURCE
Andrew Rice, Edward Aftandilian, Ciera Jaspan, Emily Johnston, Michael Pradel, and Yulissa Arroyo-Paredes. 2017. Detecting argument selection defects. Proc. ACM Program. Lang. 1, OOPSLA, Article 104 (October 2017), 22 pages. DOI:10.1145/3133928
📄 Lien public
DOIs:
10.1145/3133928
Evolution of Software Development in the Video Game Industry 🔗
🧮 Méthodes de développement
⚔️ Dans le monde du jeu vidéo, la guerre économique fait rage entre les studios. Il est compliqué pour les chercheurs d’analyser les méthodes de développement de ce secteur. Une équipe d’Oakland y est parvenue à partir des post-mortem que les équipes réalisent presque systèmatiquement après la sortie d’un jeu. Première différence avec l’informatique de gestion.
🎉 L’idée d’impliquer tôt les stakeholders dans les itérations est une question de vie ou de mort dans un jeu : seul un joueur peut savoir si le fun est présent, aucun P.O ou proxy quelconque ne peut le remplacer. C’est une grosse différence avec l’informatique de gestion où le client a rarement du temps à consacrer à cela.
🥷 La problématique du hacking est semblable des deux côtés : certains pratiquent l’exploit pour le fun, d’autres pour en tirer un bénéfice. Les jeux vidéo récents n’ont plus aucune tolérance envers les glitch-exploiters et les tricheurs à cause de la compétition régnant entre les joueurs. Ce n’est plus seulement un loisir.
🐚 Le jeu vidéo utilise bien plus le modèle Spiral que l’Agilité proprement dite. Cette dernière perce dans les entreprises ayant adopté le modèle du Game as a Service, qui divergent de plus en plus de celles restées sur le modèle Game as a Product. L’agilité vient adresser des problèmatiques rencontrées par l’informatique de gestion 15 ans plus tôt, mais sous une forme adaptée aux contraintes du jeu vidéo.
SOURCE
Newell, Kieran & Patel, Kunjal & Linden, Magnus & Demetriou, Michael & Huk, Michal & Mahmoud, Mohammed. (2021). Evolution of Software Development in the Video Game Industry. DOI:10.1109/CSCI54926.2021.00367
📄 Lien public
DOIs:
10.1109/CSCI54926.2021.00367
The 4+1 View Model of architecture 🔗
👔 Avis d'expert
💣 L’acte de naissance de l’Architecture 4+1 de Philippe Kruchten est un sujet difficile à traiter. Avec presque 30 ans de recul peu de choses vont dans ce papier, sans que cela puisse être complètement reproché à l’auteur en 1995. Celui-ci a d’ailleurs changé de position et corrigé sa vision du sujet.
1️⃣ Le premier problème est une confusion permanente entre design et architecture. En 4+1, l’architecte s’encombre de diagrammes de classes, de process et des diagrammes UML correspondants. Nous sommes dans un cas flagrant de Big Design Up Front, une erreur des années 70 ayant mis 30 ans à disparaître. Oui, l’architecture peut être conçue à l’avance, mais certainement pas le design.
2️⃣ Le deuxième problème du papier est son fétichisme de la documentation : l’architecture est déjà une documentation, qu’il faut en plus documenter pour en capter la rationnelle, les scénarios, les charges, etc. Le groupe chargé de cela ne peut qu’y être dédié, créant donc une classe d’architectes séparée du terrain, manipulant de la documentation et des abstractions.
3️⃣ Le troisième problème est épistémologique. Dire en conclusion que ça fonctionne, sans aucune étude ni source fait de ce papier un pur avis d’expert. Hélas, l’influence de M. Kruchten lui a permis de faire école : 1350 citations du papier et 46 brevets s’appuyant dessus. De la part d’un docteur, c’est un problème, mais également un symptôme du fonctionnement de l’IEEE qui a toujours publié ensemble des études chiffrées et des avis d’expert sans étiquetage.
SOURCE
P. B. Kruchten, “The 4+1 View Model of architecture,” in IEEE Software, vol. 12, no. 6, pp. 42-50, Nov. 1995, DOI:10.1109/52.469759
📄 Lien public
DOIs:
10.1109/52.469759
Secure by Design 🔗
👔 Avis d'expert
A l’heure de l’IoT et de l’informatique partout, un programme doit être Secure by Design. Cela suppose d’ajouter des pratiques de sécurité sur toute la chaîne de production du logiciel : Exigences, Design, Implémentation, Tests.
Ce papier extrêmement court est un bon résumé mais n’est pas exhaustif. Rien n’est dit sur le typage fort, l’intérêt de TDD ou encore le pair programming, qui ont pourtant de bons résultats. Les tests ne sont envisagés qu’après le développement ce qui montre un manque de connaissances de l’auteur sur la partie purement Dev. Cybersécurité et qualité logicielle sont deux mondes qui doivent se parler.
SOURCE
Abdulhamid A. Ardo, Julian M. Bass, Head, Tarek Gaber, Secure by Design, gmcyberfoundry.ac.uk
📄 Lien public
Exploring the Influence of Identifier Names on Code Quality: An empirical study 🔗
👌 Qualité logicielle
·
🗣️ Nommage
🌥️ Un nommage obscur est fortement corrélé à un code de piètre qualité, au point même de pouvoir estimer la qualité d’un code ainsi en première lecture. C’est la conclusion d’un papier anglais de 2010.
🤖 Un nommage obscur n’est pas difficile à détecter, même par une machine : encodage, identifiants trop courts ou trop longs, abbréviations, casse dissonnante, etc. La plupart des analyseurs statiques ont largement automatisé cela. L’oeil humain vient analyser en dernier lieu quand la machine a dégrossi le travail. L’équipe de chercheurs a procédé ainsi pour caractériser un nommage défaillant dans son travail.
👎 La qualité logicielle est plus difficile à quantifier : les chercheurs ont choisi la très décriée complexité cyclomatique, ainsi qu’un score FindBugs. C’est rapide et facile à obtenir, mais cela affaibit grandement le papier.
⚠️ Enfin il est important de noter que seuls des projets open-source ont été inclus dans les données de l’étude. Les chercheurs avertissent que les résultats (confidentiels) obtenus avec des projets commerciaux semblent ne pas suivre du tout la même tendance. Prudence, donc !
SOURCE
Butler, Simon; Wermelinger, Michel; Yu, Yijun and Sharp, Helen (2010). Exploring the Influence of Identifier Names on Code Quality: An empirical study. In: 14th European Conference on Software Maintenance and Reengineering, 15-18 Mar 2010, Madrid, Spain, pp. 156–165. DOI:10.1109/CSMR.2010.27
📄 Lien public
DOIs:
10.1109/CSMR.2010.27
Factors Affecting Software Development Productivity: An empirical study 🔗
🧑💼 Management
·
🧮 Méthodes de développement
·
#️⃣ Façonnage de code
📊 Comment augmenter la productivité des développeurs ? D’abord en ne se trompant pas de métrique : mesurer le nombre de lignes de code vous emmène dans une direction désastreuse, surtout à l’heure de ChatGPT. La productivité, c’est la valeur livrée dans une période de temps. Les auteurs de cette revue de littérature ont pris soin d’écarter les papiers basés sur le nombre de lignes de code, pour en retenir 57.
🔨 Les résultats ne surprendront pas les développeurs, mais peuvent se révéler utiles pour servir d’argument d’autorité face à un manager récalcitrant. D’abord il y a les facteurs humains : experience, compétences, faible turnover et facilités à communiquer en tête. Viennent ensuite les caractéristiques du produit : faible complexité, langage de haut-niveau, difficulté et nombre des exigences.
❗ C’est au niveau de l’organisation que l’on trouve les résultats les moins intuitifs : la présence d’une culture du postmortem et de la métrique, l’élimination du rework et la structuration en petites équipes sont en bonne place. La réutilisation des composants, l’usage d’outils et le temps passé à s’entraîner sont également pointés comme des facteurs de productivité.
👉 La liste présentée ici n’est pas exhaustive, il faut lire le papier pour en avoir la version complète.
SOURCE
Edna Dias Canedo and Giovanni Almeida Santos. 2019. Factors Affecting Software Development Productivity: An empirical study. In Proceedings of the XXXIII Brazilian Symposium on Software Engineering (SBES ‘19). Association for Computing Machinery, New York, NY, USA, 307–316. DOI:10.1145/3350768.3352491
DOIs:
10.1145/3350768.3352491
Regarding the Impact of Code Smells on the Energy Efficiency of Different Computer Languages 🔗
#️⃣ Façonnage de code
·
🦨 Code Smells
🦨 Les odeurs du code ne sont pas seulement un gâchis de temps de cerveau : la consommation d’énergie augmente également ! C’est le résultat obtenu par un étudiant néerlandais sur plusieurs langages.
🍝 L’étude présente néanmoins de fortes limites : certains langages ne parviennent pas à rejeter l’hypothèse nulle sur tous les problèmes testés et pire, seule l’odeur “Long Function” a été évaluée.
🌍 Ce papier a un mérite : il ouvre un champ de recherche entier à ceux qui veulent savoir si les odeurs du code ne seraient pas aussi des plaies environnementales.
SOURCE
Van Oostveen Sander, Regarding the Impact of Code Smells on the Energy Efficiency of Different Computer Languages, University of Amsterdam, 2020
Energy efficiency: a new concern for application software developers 🔗
🧮 Méthodes de développement
·
👌 Qualité logicielle
🔋 Avant 2012, la consommation d’énergie n’intéressait personne, certainement pas les chercheurs. Depuis ? Les applications mobiles ont mis cette question au centre, bien plus que les préoccupations écologiques. Une application mobile moderne ne consomme rien car elle balance tous les calculs lourds sur un cloud supposé vertueux. L’idéologie californienne de Barbrook, toujours elle.
👿 La plupart des développeurs ne sont pas des salauds, mais manquent de connaissances et d’outils sur ce sujet ! Peu savent distinguer puissance et énergie, les outils de mesure de consommation sont peu répandus et ne conseillent en aucun cas sur les mesures à prendre pour économiser l’énergie. L’outillage de haut-niveau manque, les développeurs en sont réduits aux modifications hasardeuses de bas-niveau, très corrélées au nombre de défauts.
✅ Les auteurs dressent ensuite un état de l’art qui n’a pas vieilli dans ses grandes lignes, le papier date de 2017.
SOURCE
Pinto, Gustavo & Castor, Fernando. (2017). Energy efficiency: A new concern for application software developers. Communications of the ACM. 60. 68-75. DOI:10.1145/3154384.
📄 Lien public
DOIs:
10.1145/3154384
The World Wide Web: Past, Present and Future 🔗
👔 Avis d'expert
💣 En 1996, l’architecte du World Wide Web, Tim Berners-Lee, annonçait les effets potentiels de celui-ci sur le monde. Appauvrissement de la diversité culturelle par l’abaissement des barrières géographiques au profit d’une soupe américanoïde; Transfert de l’autorité parentale à l’Etat, seul capable de contrôler le contenu visionné par les enfants; Ghettoïsation de la vie démocratique en clans radicalisés et irréconciliables;
🧙♂️ Il n’était nullement prophète, mais architecte. L’architecture du Web est pensée pour répondre ensemble à des exigences précises, définies dès son origine. Ces exigences sont démentes : le Web doit permettre de relier arbitrairement deux ressources à travers le monde, indépendamment des technologies qui les servent, sans format contrait, de manière décentralisée et suffisamment ergonomique pour impliquer des non-techniciens dans l’ajout de contenu. Berners-Lee n’est pas le premier à essayer de faire advenir le rêve de Vanevar Bush et de toute une génération, mais il sera le premier à y arriver.
🌐 Face à des exigences, le travail de l’architecte est de définir des contraintes, qui devront être suivies par les implémentateurs. La première contrainte est l’indépendance des spécifications : tout doit cohabiter sur le web, l’ancien comme le neuf afin qu’il n’ait pas besoin d’être “redémarré” pour évoluer. La seconde est la capacité de référencer n’importe quoi sur un autre serveur, sans son consentement (ce qui a le défaut de permettre les liens morts). La troisième est la possibilité de négocier le contenu préalablement à l’échange, afin que client et serveur trouvent un format commun.
🦯 Ces contraintes remplissent les exigences, mais sans garantir l’absence d’effets de bord. Le déploiement d’un tel système au niveau mondial a eu les effets décrits au début de cet article. Fallait-il créer le Web ? Face à ces risques, Berners-Lee répondit par le techno-solutionnisme : nous trouverons bien un moyen technique de rendre le Web éthique. L’echec de PICS sert d’invalidation de cette idée.
SOURCE
Berners-Lee Tim, The World Wide Web: Past, Present and Future, August 1996, W3.org
📄 Lien public
How reuse influences productivity in object-oriented systems 🔗
👌 Qualité logicielle
📦 Utiliser une bibliothèque plutôt que de développer from scratch permet une plus grande productivité, avec moins de défauts, de bugs et de temps passé à corriger ces derniers. Tout cela bien entendu, si les bibliothèques sélectionnées sont pertinentes pour le besoin.
🧑🎓 Ces résultats ont été obtenus sur des étudiants, ce qui peut biaiser les résultats, de l’aveu même des auteurs. Les bibliothèques utilisées ont probablement été développées par plus senior qu’eux.
SOURCE
Basili, Victor R., Lionel Claude Briand and Walcélio L. Melo. “How reuse influences productivity in object-oriented systems.” Commun. ACM 39 (1996): 104-116. DOI:10.1145/236156.236184
📄 Lien public
DOIs:
10.1145/236156.236184
Classifying Software Changes: Clean or Buggy ? 🔗
🧪 Tests
🔮 Prenez un commit, il serait miraculeux d’avoir un “oracle” capable de dire avec précision les chances d’y trouver des bugs, exactement comme les indices au démineur. C’est possible grâce au Machine Learning, au moins en conditions de laboratoire.
🤖 Il faut pour cela entraîner un modèle, le classificateur, à partir des changements sur un VCS. La procédure exacte est détaillée dans le papier. Le modèle est évalué en vérifiant si de véritables bugs, présents puis corrigés sur des projets open-source, sont détectés.
🛠️ J’ignore si des outils contemporains utilisent de telles techniques. L’article date de 2008, bien avant la hype sur l’IA.
SOURCE
Kim, Sunghun, E. James Whitehead and Yi Zhang. “Classifying Software Changes: Clean or Buggy?” IEEE Transactions on Software Engineering 34 (2008): 181-196.
📄 Lien public
DOIs:
10.1109/TSE.2007.70773
Random Test Run Length and Effectiveness 🔗
🧪 Tests
🎲 Les tests aléatoires fonctionnent comme un puits de pétrole. Les premiers runs ont peut de chance de remonter des bugs. Persévérez, ils viendront, puis se raréfieront progressivement. A partir d’un certain point, le temps passé pour détecter un nouveau bug rendra la démarche totalement inefficiente budgétairement.
📈 Le nombre de runs avant d’atteindre ce “pic” dépend du projet, il est donc conseillé de mesurer le nombre de défauts détectés par heure lorsque l’on lance des tests aléatoires. Le pic se verra sur la courbe ainsi tracée.
SOURCE
Andrews, James & Groce, Alex & Weston, Melissa & Xu, Ru-Gang. (2008). Random Test Run Length and Effectiveness. 19-28. DOI:10.1109/ASE.2008.12.
📄 Lien public
DOIs:
10.1109/ASE.2008.12
Empirical investigation towards the effectiveness of Test First programming 🔗
🧪 Tests
🐌 Test-First, dont TDD fait partie, ne rend pas les développeurs plus productifs que Test-Last ! Pire, les praticiens de Test-First passent plus de temps à tester, pour une qualité visible identique. Le temps passé à tester est en revanche du temps en moins passé sur le code.
⚠️ TDD est-il à ranger au placard ? Pas si vite. D’abord, l’étude note que les groupes TDD n’avaient pas une forte expérience et ont passé autant de temps à apprendre la méthode qu’ils en ont passé à pratiquer. Fait connu des praticiens de TDD : au début c’est laborieux. Second biais : le groupe TDD n’effectuait que des tests unitaires. Or, il est plutôt recommandé actuellement l’outside-in TDD, soit TDD pour les tests fonctionnels.
🕰️ L’étude date de 2009, ce qui explique bien des choses. Elle mériterait d’être reproduite 15 ans après.
SOURCE
Huang, Liang & Holcombe, M.. (2009). Empirical investigation towards the effectiveness of Test First programming. Information & Software Technology. 51. 182-194. DOI:10.1016/j.infsof.2008.03.007.
📄 Lien public
DOIs:
10.1016/j.infsof.2008.03.007
What Types of Defects Are Really Discovered in Code Reviews ? 🔗
🧮 Méthodes de développement
👀 Les revues de code sont complémentaires aux tests. Les tests sont incapables de repérer le manque d’évolutivité du code, les revues très peu performantes pour remonter les défauts fonctionnels.
🤖 Mieux, les revues de code sont complémentaires aux outils comme les linters ou les analyseurs statiques, à condition de faire passer ceux-ci avant la review pour éviter de longs débats inutiles.
🧑🎓 L’étude démontre également que les étudiants et les professionnels obtiennent des résultats comparables lors des code reviews, ce qui peut permettre de valider certaines études similaires uniquement effectuées sur des étudiants.
🤝 Ce que l’étude ne vérifie pas, c’est si le pair programming, véritable revue de code en live, obtient des résultats similaires.
SOURCE
Mika Mäntylä and Casper Lassenius. “What Types of Defects Are Really Discovered in Code Reviews?” IEEE Transactions on Software Engineering 35 (2009): 430-448. DOI:10.1109/TSE.2008.71
📄 Lien public
DOIs:
10.1109/TSE.2008.71
Using Program Slicing in Software Maintenance 🔗
🧪 Tests
👎 Pour éviter les régressions, nous utilisons habituellement les tests. Même lorsqu’ils existent et sont de qualité, il s’agit rarement d’une assurance tous-risques. D’autres techniques peuvent les compléter pour s’assurer de ne rien casser. L’une d’elle est le slicing.
🍕 Une slice est une tranche de programme elle-même exécutable. Prenez un programme. Faites-le tourner avec des valeurs particulières jusqu’à un point d’arrêt. Supprimez tout le code qui n’a pas eu d’influence sur l’exécution. Vous avez une slice.
🧑🔬 Déjà utilisées en débogage, pour restreindre l’endroit du code où chercher les problèmes, les slices peuvent aussi être utilisées pour s’assurer de ne pas introduire de régressions lors d’une modification. La technique se fait en construisant 2 slices liées mathématiquement : la décomposition et son complément. La logique de construction de ces 2 slices assez complexe et plutôt réservée aux développeurs d’outils.
✅ Ce binôme de slices permet de prédire si une insertion ou une suppression de code aura des effets de bord. Le développeur effectue ses modifications, puis regénère à nouveau les deux slices. Si les compléments sont identiques avant et après les modifications, il est mathématiquement sûr qu’aucune régression n’a été introduite. Attention cependant : cela n’indique en rien que le changement lui-même est correct.
🔬 J’ignore si ce papier a eu une postérité, cela fera l’objet d’une recherche à part, tant l’idée a l’air novatrice.
SOURCE
Gallagher, Keith & Lyle, James. (1991). Using Program Slicing In Software Maintenance. Software Engineering, IEEE Transactions on. 17. 751-761. DOI:10.1109/32.83912
📄 Lien public
DOIs:
10.1109/32.83912
Mixin-Based Inheritance 🔗
🔣 Science des Langages
🍨 Les mixins sont un moyen surprenant d’ajouter des fonctionnalités à une classe, sans en hériter et sans la modifier. La technique est longtemps restée du domaine du “hack”, tant en LISP, d’où elle tire son nom, que sur des langages plus récents.
🪄 Un mixin en LISP est une classe abstraite, dont les méthodes invoquent un parent que le mixin ne possède pas. La magie opère lorsqu’une classe tierce hérite à la fois du mixin et d’un parent compatible avec celui-ci. La linéarisation des parents, un mécanisme propre à Lisp, “insère” le mixin entre la classe concrète et son parent dans la relation d’héritage.
💡 Le papier va plus loin, en montrant que les mixins sont un mécanisme bien plus universel que la manière dont les langages orientés objet gèrent l’héritage. Les chercheurs proposent donc d’envisager l’héritage comme un usage particulier des mixins. L’idée n’a pas pris, mais le regain de notoriété des mixins dans les années 2000 a permis des implémentations plus propres, comme les méthodes d’extension de C#, les inclusions en Ruby ou l’héritage de Python. Les traits modernes héritent directement des mixins.
SOURCE
Bracha, Gilad and William R. Cook. “Mixin-based inheritance.” OOPSLA/ECOOP ‘90 (1990). DOI:10.1145/97946.97982
📄 Lien public
DOIs:
10.1145/97945.97982
Formalizing style to understand descriptions of software architecture 🔗
📐 Architecture
😣 Quiconque s’est un jour renseigné sur l’architecture l’a constaté : c’est une non-discipline où peu de standards existent et où chacun a sa propre manière de procéder. Le papier du jour, sorti en 1995, disait déjà sensiblement la même chose.
🖌️ Les praticiens sont globalement d’accord pour dire qu’il existe des composants et des connecteurs. La définition des premiers ne fait pas débat. Les composants sont les “endroits du calcul” chez quasiment tous les auteurs. La définition des connecteurs est bien plus problématique : Que sont-ils ? Comment les représenter dans un schéma ? Faites débattre deux architectes, vous obtiendrez trois définitions.
👓 Abowd, Allen et Garlan proposent d’acter cette diversité à travers la notion de “style d’architecture”. Le style architectural a pour rôle d’attacher une sémantique à la syntaxe d’un schéma d’architecture. Prenez un schéma constitué de deux rectangles reliés par une flèche. Selon les lunettes que vous chausserez, vous verrez deux programmes s’envoyant des données, deux modules ayant une relation de dépendance ou encore un programme tirant ses données d’une source. Ces lunettes se nomment “style architectural”.
🤯 L’idée est brillante, mais ne fait que déplacer le problème. Cherchez de la littérature sur les styles architecturaux, vous trouverez le même brouhaha que sur la discipline en général. Il reste encore du travail.
SOURCE
Abowd, Gregory D., Robert J. Allen and David Garlan. “Formalizing style to understand descriptions of software architecture.” ACM Trans. Softw. Eng. Methodol. 4 (1995): 319-364. DOI:10.1145/226241.226244
📄 Lien public
DOIs:
10.1145/226241.226244
The influence of organizational structure on software quality 🔗
👌 Qualité logicielle
·
🧑💼 Management
📖 La Loi de Conway énonce que les systèmes qu’une organisation produit sont la copie de sa structure de communication. Brooks n’est pas plus tendre en reliant la qualité des logiciels à la qualité des relations dans l’équipe. Cependant aucun n’apporte de preuves empiriques.
📏 Mesurer une telle corrélation n’est pas simple. Il faut déjà quantifier la qualité. A la lecture de cette proposition, la plupart des philosophes se sont crevés les yeux. Nous savons cependant approximer la qualité à l’aide d’un cocktail de métriques : la complexité du code, son niveau de beurdassage (code churn en anglais, je trouve la traduction saintongeaise plus transparente que le français), le coverage, le nombre de dépendances ou le taux de bugs. Ces mesures ont toutes de gros défauts, mais mises ensemble elles sont une mesure acceptable de qualité. Côté relationnel, il a fallu inventer 8 métriques, quantifiant des indicateurs découverts par d’autres travaux.
⚠️ Les chercheurs ont découvert que la structure de l’organisation portant le projet prédit mieux la probabilité de défaut que l’ensemble des métriques de qualité listées plus haut. Ces résultats sont à prendre avec beaucoup de prudence : un seul projet a servi d’étude de cas, les métriques organisationnelles sont crées pour l’occasion et la quantification de la qualité est périlleuse. Cependant ces résultats sont encourageants et appellent à répliquer cette étude.
SOURCE
Nagappan, Nachiappan, Brendan Murphy and Victor R. Basili. “The influence of organizational structure on software quality.” 2008 ACM/IEEE 30th International Conference on Software Engineering (2008): 521-530. DOI: 10.1145/1368088.1368160
📄 Lien public
DOIs:
10.1145/1368088.1368160
Exploration on the Performance of Ideological and Political Responsibilities and Evaluation of Computer Teachers in Colleges and Universities 🔗
🧑🏫 Pédagogie
🐟🐟🐟🐟🐟🐟🐟
👨💻 Les professeurs d’informatique forment les masses à l’usage des ordinateurs, omniprésents dans la société moderne. Leur rôle est central. Le risque qu’ils introduisent des déviations idéologiques dans leur modules, donc dans toute la société est grand.
👮 Il est important que chaque module de formation énonce clairement les objectifs politiques et idéologiques du professeur. Les étudiants doivent aussi avoir une écoute active pendant les cours afin de repérer les éléments politiques et idéologiques, y compris dans les matières les plus arides. Ils trouveront ensuite chez les autorités municipales une oreille attentive, afin qu’elles invitent le professeur à plus d’excellence dans les éléments idéologiques qu’il transmet.
🚀 L’exaltation de réussites comme WeChat, Alipay ou le rover Yutu doivent raffermir ceux qui doutent de la capacité de la République Populaire de Chine à se réformer et à s’ouvrir, sans dévier de la route vers le socialisme. Le travail en petits groupes doit permettre de comprendre que l’armée des U.S.A peut être vaincue par le respect de l’autre, le travail d’équipe, la conscience de la situation et l’esprit collectiviste.
🧧 Le rôle du professeur d’informatique est de faire comprendre tout cela aux masses éduquées. Il doit en permanence évaluer idéologiquement ses étudiants et rapporter leurs progrès à sa hiérarchie. Il n’est pas un canal secondaire de transmission de l’idéologie, mais bien le canal principal, à l’heure où les ordinateurs sont partout. C’est ainsi que nous cultiverons d’excellents talents socialistes en informatique.
SOURCE
Fei Wang, Xu Yu, Exploration on the Performance of Ideological and Political Responsibilities and Evaluation of Computer Teachers in Colleges and Universities, Proceedings of the 2022 International Conference on Science Education and Art Appreciation (SEAA 2022), 2022, DOI:10.2991/978-2-494069-05-3_191
📄 Lien public
DOIs:
10.2991/978-2-494069-05-3_191
Energy efficiency across programming languages: how do energy, time, and memory relate ? 🔗
🔣 Science des Langages
⚙️ Un programme économe en énergie est-il toujours un programme performant ? Pour le savoir, il faut déjà mesurer la consommation en énergie d’un même algorithme exécuté par plusieurs langages. Une équipe portugaise a montré l’incroyable sobriété des langages compilés, C en tête. Les langages à machine virtuelle comme Java et la famille .NET viennent ensuite. Les langages interprétés sont bons derniers.
📈 Cette conclusion est également vraie en matière de performance brute, sur des algorithmes simples. Que l’on cherche à optimiser le temps de calcul, la consommation de mémoire, l’efficience énergétique, ou un cocktail de ces variables, le trio de tête reste le même : C, Go, Pascal.
⏱️ Comment expliquer ces résultats ? Probablement car ces langages sont depuis des décennies utilisés lorsque l’efficience est déterminante. Ils ont donc évolué pour satisfaire leur “clientèle”, contrairement aux langages de haut-niveau qui recherchent plus volontiers la vélocité de développement. Un outil émerge toujours en fonction d’un besoin en ne peut être compris qu’à travers celui-ci.
SOURCE
Pereira, Rui & Couto, Marco & Ribeiro, Francisco & Rua, Rui & Cunha, Jácome & Fernandes, João & Saraiva, João. (2017). Energy efficiency across programming languages: how do energy, time, and memory relate?. 256-267. DOI:10.1145/3136014.3136031.
📄 Lien public
DOIs:
10.1145/3136014.3136031
The benefits of Test Automation in Software Development 🔗
🎓 Thèse
·
🧪 Tests
🧪 Rédiger un test automatisé prend 20 fois plus de temps que de vérifier la même chose à la main, en moyenne. C’est pour cela que les prototypes et autres logiciels “one shot” ne sont pas accompagnés de cas de test. 20 fois ça n’est pas grand chose, surtout avec des méthodes comme TDD où les tests sont exécutés plusieurs fois par heure.
🐺 Il y a tout de même un loup : si les tests automatisés doivent être refaits en permanence à cause d’une technique inadaptée, l’addition peut être bien plus salée. C’est là que le bât blesse dans de nombreuses entreprises. Des tests fragiles, trop couplés à une implémentation (tests unitaires par exemple) ou mal fichus auront très peu d’intérêt économique par rapport à des tests manuels.
📞 Pour savoir comment tester correctement, l’industrie et la recherche doivent communiquer. Ca n’est absolument pas le cas. La recherche tourne en vase clos sur des hypothèses qui n’intéressent pas les praticiens. Ces derniers ne lisent pas les travaux des chercheurs, ce qui leur permettrait de valider les hypothèses des gourous à la mode. L’auteur de cette thèse met le doigt sur ce qui m’a fait démarrer cette entreprise de vulgarisation. Notre profession doit marcher sur deux jambes pour cesser de claudiquer : l’expertise des maîtres et le savoir des chercheurs.
SOURCE
Kemppainen, Toni, The benefits of Test Automation in Software Development (2022)
📄 Lien public
Program Comprehension During Software Maintenance and Evolution 🔗
🧠 Psychologie
🧠 Avec l’expérience, un développeur acquiert des connaissances générales sur son métier, mais aussi des connaissances spécifiques à divers projets sur lesquels il a oeuvré. Ces connaissances spécifiques prennent la forme d’un modèle mental du code, constitué de chunks. Cette construction, déjà abordée dans cette veille désigne un “paquet” compressé d’informations, pouvant contenir des connaissances très variées, mais aussi des pointeurs vers d’autres chunks.
📜 Le modèle mental contient des élements statiques et dynamiques. Parmi les élements statiques, nous trouvons la connaissance textuelle, stockée dans la mémoire à long terme et responsable de notre connaissance instructionnelle du code (ce que font chacune des instructions). Nous y trouvons également les plans, qui désignent nos attendus lorsque nous interprétons une structure. Un algorithme que nous connaissons ou un pattern seront stockés dans notre cerveau sous cette forme.
🪡 Nous mobilisons des éléments statiques lorsque nous tentons de comprendre un code, afin de générer des éléments dynamiques propres à celui-ci. Deux mécanismes sont à l’oeuvre, le chunking, grâce auquel nous créons des chunks de plus haut niveau à partir de connaissances statiques de plus bas niveau et le cross-referencing, qui nous permet de lier plusieurs éléments de niveaux d’abstraction différents dans une relation de tout à parties.
❇️ Si nous reconnaissons un pattern derrière un bloc de code, c’est grâce à des balises, des indices laissés par le rédacteur du code. Par conséquent, un algorithme valide, mais de forme inhabituelle sera dur à comprendre y compris pour un expert, d’où l’intérêt des conventions. L’expérience amène plus de souplesse mentale dans ce processus et une plus grande vélocité.
🥼 La suite du papier décrit plusieurs modèles cognitifs proposés par divers chercheurs, avant de les confronter. Cette analyse intéressera surtout les chercheurs en psychologie du développement. On peut cependant tirer quelques enseignements : D’une part, on sait que la connaissance n’est pas unidirectionnelle du métier vers le code. Le code rétroagit et nous apprend des choses sur le métier. D’autre part, la compréhension du code est un mélange de bottom-up et de top-down. Le développeur effectue de nombreux allers-retour entre les niveau d’abstraction afin de comprendre.
SOURCE
Anneliese von Mayrhauser and A. Marie Vans. 1995. Program Comprehension During Software Maintenance and Evolution. Computer 28, 8 (August 1995), 44–55. DOI:10.1109/2.402076
📄 Lien public
DOIs:
10.1109/2.402076
A Metric for Software Readability 🔗
#️⃣ Façonnage de code
·
🗣️ Nommage
🧶 La lisibilité d’un code est-elle universelle ? Autrement dit, classerions-nous tous de manière identique une série de snippets du plus lisible au plus obscur ? Deux américains ont tenté l’expérience et semblent montrer qu’une corrélation modérée existe.
✂️ Les chercheurs ont ensuite recherché les caractéristiques faisant un code lisible. La taille des identifiants n’a aucune corrélation avec la lisibilité. allonger ceux-ci sans but précis n’apporte rien à la compréhension. Les commentaires sont faiblement corrélés à la lisibilité, probablement car ceux-ci tendent à documenter un code peu lisible. La principale métrique corrélée à la lisibilité semble être le nombre d’instructions par ligne. La quantité de lignes vides arrive peu après.
🎶 Aérer son code semble être le meilleur conseil pour le rendre plus lisible. Comme dans un beau poème, l’aération et le placement des mots a un sens.
SOURCE
Buse, Raymond P. L. and Westley Weimer. “A metric for software readability.” International Symposium on Software Testing and Analysis (2008). DOI: 10.1145/1390630.1390647
📄 Lien public
DOIs:
10.1145/1390630.1390647
Ariane 5 : Flight 501 Failure Report By The Inquiry Board 🔗
💩 Cas d'échecs
💥 Le 4 juin 1996, le premier vol d’Ariane 5 se termine par une autodestruction. La mémoire collective retient un désastre logiciel, mais est-ce bien honnête ? Pour qui se plonge dans le rapport d’enquête, rien n’est moins sûr.
📰 La couverture médiatique de l’évènement se résume à cela : 40 secondes après le début du compte à rebours, les deux centrales inertielles de la fusée s’éteignent successivement après un même plantage. La fusée désorientée prend une trajectoire dangereuse, nécessitant sa destruction. Avant même d’étudier les causes du plantage, une aberration ressort : comment se fait-il que ces composants critiques soient matériellement et logiciellement identiques ? En de pareils cas, l’état de l’art recommande déjà à l’époque de confier le développement à deux équipes distinctes, ayant les mêmes spécifications, afin de minimiser les chances de bug identique.
😶🌫️ Le brouillard des responsabilités s’épaissit lorsque l’on apprend que les centrales inertielles n’ont pas été testées avec les paramètres de vol d’Ariane 5. Les ingénieurs ont considéré que les excellents états de service de ce composant sur Ariane 4 valaient qualification. Or Ariane 5 est d’un ordre de grandeur plus puissante que Ariane 4, ce qui a provoqué un dépassement d’entier lors d’une conversion non-protégée. La faute est partagée entre les ingénieurs et les développeurs : ces derniers auraient dû documenter cette limitation, présente en raison de problématiques de performance.
🐛 Chez Ariane, les exceptions ne sont pas utilisées, sauf pour rapporter une erreur matérielle par définition aléatoire. Elles ne sont donc pas gérées, sauf pour produire un rapport de plantage. Les développeurs doivent écrire un code qui n’en lance pas. Ceux-ci n’avaient pas anticipé que le langage Ada en émet en cas de dépassement d’entier. C’est cette conjonction qui provoqua le plantage.
📍 Le clou du spectacle ? Le code fautif ne sert pas sur Ariane 5, il a été conservé d’Ariane 4 afin de ne pas avoir à retester les centrales inertielles. Les développeurs sont-ils coupables ? Méritent-ils d’avoir le nez et les mains coupés ? Mon avis en commentaire.
SOURCE
Lyons, J. L. and Yvan Choquer. Ariane 5 : Flight 501 Failure Report By The Inquiry Board Paris, 19 July 1996.
—- Avis
Pour moi, l’erreur principale a été de ne pas tester les centrales inertielles sur Ariane 5 avant le vol inaugural. Cependant, je ne dédouane pas totalement les développeurs : Une limitation technique comme une conversion non-protégée aurait dû être documentée. Si elle l’avait été, cela aurait mis la puce à l’oreille des ingénieurs lors de la décision de qualifier le composant pour Ariane 5 sans tests. A mon avis, les responsabilités sont partagées à 75/25 entre ingénieurs et développeurs.
📄 Lien public
Le Refactoring comme modèle de couplage homme-machine : technique, sémiotique, mémoire 🔗
🎓 Thèse
·
#️⃣ Façonnage de code
👨🏫 Un de mes anciens professeurs, Ophir Paz, a publié sa thèse il y a presque 2 ans. C’est dense, j’ai donc choisi de la résumer par chapitres. J’ignore volontairement les premiers chapitres, introductifs, afin de débuter par le troisième, qui mêle sémiotique et développement.
Chapitre 3 : Différents niveaux de sens
⌨️ Comprendre du code a tout du parcours initiatique ! Il ne suffit pas de comprendre ce que font les instructions pas à pas pour en saisir le sens. A vrai dire, celui qui en reste au niveau instructionnel ne fait qu’effleurer la surface. Avec l’expérience, un développeur déchiffre le sens invariant de groupes d’instructions, c’est-à-dire la fonction attachée habituellement à une construction donnée. Par exemple, la plupart des développeurs savent qu’une boucle for où l’indice est une position dans un tableau sert à itérer sur celui-ci.
🧠 La majorité du sens que porte un code est encore au-delà : il s’agit du sens social. Que signifie un bloc de code pour l’équipe qui doit la maintenir ? Quel est son rôle dans le projet, c’est à dire par rapport au contexte : expérience des développeurs, exigences, histoire du code, etc. La part déterminante de la signification d’un code se trouve ici.
💣 Ce chapitre m’a permis d’affiner ma définition du Principe de Moindre Surprise (Principle of Least Astonishment en anglais). Respecter ce principe, c’est écrire du code ayant un sens social compatible avec le sens invariant communément admis des instructions qu’il contient.
Chapitre 4 : Grammaire de construction
🤢 Un code peut être syntactiquement valide, c’est-à-dire compilable, sans pour autant être socialement convenable au sein d’une communauté de développeurs. Le phénomène à l’oeuvre est le même qu’en français ou dans toute autre langue : “Combien d’années avez-vous ?” sonne mal, on lui préférera “Quel âge avez-vous ?”. De même for(int i=0 ; i<10 ; i = 1 + i) dissonne.
🗣️ Ophir Paz décortique ce phénomène en utilisant les grammaires de construction, une branche de la linguistique. Pour les auteurs de cette école, les locuteurs d’une langue apprennent et manipulent des constructions, c’est-à-dire des appairages forme-sens. L’expression “Comment vas-tu ?” lorsque l’on salue quelqu’un de familier n’est pas à interpréter littéralement. De même, l’incrémentation d’un pointeur (*p++) possède un sens invariant pour les développeurs C++ chevronnés : celui de parcourir un tableau séquentiellement.
😕 Ces constructions ont un sens instructionnel clair, qui sera exécuté par le compilateur, mais aussi un sens invariant non-prédictible, c’est à dire ne pouvant pas être déduit des seules instructions. C’est un problème pour le profane, qui lit un code qu’il n’a pas les codes pour comprendre. A cela s’ajoute un sens social, connu des seuls développeurs, pouvant contredire le sens invariant communément admis par la profession.
🪄 Ainsi, pour comprendre un programme, il ne suffit pas de partager les sources. Il faut également posséder des connaissances concernant les expressions idiomatiques répandues au sein de la communauté. Les programmes sont écrits à l’aide de ces constructions et en partant du principe que le futur lecteur les connaît également. De même pour les constructions plus confidentielles, propres à une équipe de développement, même si ces dernières doivent être limitées afin de garder le code reprenable.
Chapitre 5 : Sémiotique constructive du code
📡 En 1949, Claude Shannon propose son modèle de communication éponyme. Il régna sur la psychologie de la programmation pendant un demi-siècle, continué par les approches cognitivistes. Son postulat de base est la symétrie du message entre émetteur et destinataire. Appliqué au développement de logiciels, ce modèle voit le programmeur comme le récepteur de spécifications non-ambigues, qu’il est chargé de traduire en code non-ambigu destiné à une machine.
😶🌫️ Cette représentation, à l’origine de la famille de méthodes Waterfall (contenant le Cycle en V) est empiriquement erronnée. Ni le code, ni les spécifications ne sont des messages symétriques. Chaque développeur appairera un sens différent aux formes qu’il lit. Les formes elles-mêmes sont souvent polysémiques (“grand” n’a pas le même sens dans “un grand vin” et “un grand enfant”, de même pour le mot clé static en C).
🧠 Ophir Paz propose de dépasser ce modèle à l’aide d’une approche issue de la linguistique cognitive de Lakoff et Johnson, à la frontière de la sémiotique. Pour cette école, notre cerveau agit comme un moteur d’inférence lorsqu’il lit un code. Il associe les symboles à un sens en fonction du contexte, lui-même constitué des symboles entourant le premier et du contexte plus général du projet. Le langage n’est pas un signal, il est la pensée elle-même ! Nous apprenons et restituons nos connaissances par le biais de métaphores, qui ne sont pas de simples figures de style, mais l’incarnation de la pensée abstraite. La manière dont les enfants apprennent l’arithmétique, par analogie avec des collections d’objets ou les design patterns sont autant d’indices de la validité de ce modèle.
🤝 Chacun interprète le code en fonction de son système de métaphores propre, difficilement reformatable. Travailler en équipe suppose donc une négociation du sens entre les parties. Chacun doit miser sur ce que l’autre comprendra au moment d’écrire un code. Ne pouvant être dans tête de ses collègues, chaque développeur est amené à évoluer par essais et erreurs, à ajuster la structure du code sans en changer le fonctionnement, afin de le clarifier pour autrui, mais également pour soi, lorsque le temps aura effacé une partie de notre mémoire. Cette procédure, les développeurs la nomment refactoring et Ophir Paz en donne une nouvelle compréhension.
Chapitre 6 : Le code en tant qu’outil
📚 Le code n’est pas seulement la traduction du besoin en un langage intelligible par une machine. C’est un objet technique à part entière, forgé à partir de pièces plus simples, en perpétuelle évolution. Parfois cet objet est réutilisé en dehors de son cadre d’usage et devient un standard, à l’instar des langages de programmation ou des bibliothèques populaires.
🦾 Le code n’est pas le logiciel, mais la prothèse permettant au développeur qui s’en saisit de produire un logiciel. Il est l’interface entre le logiciel et les schémas mentaux dudit développeur. Refactorer le code c’est aligner les grilles de lecture de chacun, afin que toute l’équipe comprenne bien la même chose en lisant le code. Ce processus augmente la capacité à travailler ensemble autour d’une oeuvre commune, gage de vélocité et de résilience.
🧠 On se méprend sur ce phénomène en pensant que seul le code s’améliore dans ce processus. Le développeur en sort également transformé. L’invention de l’écriture n’a pas seulement permis de coucher sur support ce qui était transmis oralement. De nouvelles formes d’expressions sont apparues et ont augmenté les possibles offerts à notre espèce et par voie de conséquence le champ du concevable s’est dilaté. On retrouve ce phénomène à plus petite échelle dans l’apprentissage des nouveaux développeurs : ils apprennent par imitation d’une base de code existante, en appairant un sens qui leur est propre à des constructions récurrentes, afin de les réutiliser plus tard.
🗣️ La prochaine fois que vous verrez une équipe de developpement discuter au lieu de coder, n’ayez crainte, ils sont simplement en train d’augmenter leur productivité collective. Le principal produit de l’activité de développement n’est pas le logiciel, mais le développeur lui-même. Cette paraphrase de Frédéric Le Play conclut ce résumé d’une thèse que j’ai eu plaisir à lire.
SOURCE
Le refactoring comme modèle du couplage homme-machine / Ophir Paz ; sous la direction de Jean-Baptiste Guignard. Thèse de doctorat : Automatique, Productique, Signal et Image, Ingénierie cognitique : Bordeaux : 2022.
Program and interface slicing for reverse engineering 🔗
🧮 Méthodes de développement
🔨 Les développeurs sont condamnés à éternellement devoir pratiquer l’ingénierie inverse (reverse engineering). De mauvais systèmes seront toujours produits par le bois tordu de l’humanité. Même un bon code aujourd’hui pourrait paraître archaïque dans quelques décennies à peine.
🧠 Pratiquer l’ingénierie inverse requiert 2 compétences distinctes : savoir déchiffrer l’intention derrière un design d’une part et pouvoir comprendre le comportement d’algorithmes d’autre part. Nous savons depuis Weiser qu’une telle opération requiert la création de modèles mentaux sous forme de slices : des morceaux discontinus de logiciels obtenus en rassemblant dans notre tête l’ensemble des endroits que nous pensons reliés au problème étudié.
🎛️ Beck et Eichmann, deux chercheurs américains, proposent de dériver ce concept de slices afin de mieux coller à la réalité de l’ingénierie inverse. Au lieu de chercher les morceaux de code reliés à un souci, ils proposent aux développeurs de repérer les morceaux de code participant à une interface, c’est à dire ceux offrant une fonctionnalité au monde extérieur. Ils nomment cette technique interface slicing.
🤖 L’avantage ? Il est facile de s’aider d’outils capables de prendre une interface donnée et de mettre en évidence les slices y étant reliées. Ces travaux servent donc surtout aux développeurs d’outils.
SOURCE
J. Beck and D. Eichmann, “Program and interface slicing for reverse engineering,” Proceedings of 1993 15th International Conference on Software Engineering, Baltimore, MD, USA, 1993, pp. 509-518, doi:10.1109/ICSE.1993.346015.
📄 Lien public
DOIs:
10.1109/ICSE.1993.346015
Convergent contemporary software peer review practices 🔗
🧮 Méthodes de développement
·
#️⃣ Façonnage de code
💡 La revue par les pairs a été maintes fois étudiée sous l’angle de la réduction des défauts. Qu’en est-il du partage du savoir ? Les auteurs ont étudié les pratiques de revue de code en vigueur dans l’Open Source, mais aussi chez Google, AMD et Microsoft. L’époque des process lourds est achevée, la majorité de la profession utilise désormais des méthodes de revue légères, moins formelles, voire laissant la part belle à la revue avant commit.
🤝 La revue de code d’est hybridée avec le Pair Programming, en devenant “une résolution de problèmes en groupe”, plutôt qu’une recherche méthodique de défauts. A ce titre, les auteurs notent que le nombre optimal de reviewers est de … deux. Cette vision de la review évite le context-switching que provoque le rejet simple de la modification.
🔦 Plus intéressant, les auteurs notent que les développeurs ne se limitent pas aux fichiers sur lesquels ils ont déjà travaillé lors d’une revue. Celle-ci leur permet donc de connaître plus de parties du projet que si aucune revue n’était en place. La connaissance est moins approfondie que si le développeur travaillait en pair programming, mais tout de même.
👁️🗨️ Ce papier est intéressant, car il montre à nouveau à quel point la revue de code est un compromis entre le pair programming et l’absence totale de double-validation. Rien n’interdit à une équipe d’être souple et de passer d’une pratique à l’autre selon ses besoin.
SOURCE
Peter C. Rigby and Christian Bird. 2013. Convergent contemporary software peer review practices. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2013). Association for Computing Machinery, New York, NY, USA, 202–212. DOI:10.1145/2491411.2491444
📄 Lien public
DOIs:
10.1145/2491411.2491444
Domain-Driven Design in Software Development: A Systematic Literature Review on Implementation, Challenges, and Effectiveness 🔗
📐 Architecture
·
🧮 Méthodes de développement
·
#️⃣ Façonnage de code
🔬 Enfin une revue de littérature sur l’efficacité de DDD ! Il n’y en avait jusqu’alors pas. Les conclusions des trois auteurs tendent à affirmer que DDD fonctionne mais avec de sérieuses réserves quant à la fiabilité de la littérature existante.
😶🌫️ Aucune manière standardisée de mesurer les performances de DDD n’a été adoptée par les différentes équipes, qui n’ont d’ailleurs pas étudié les mêmes questions. Le monde académique et l’industrie ne se sont pas rencontrés et ont mené deux types d’études disjoints.
🌶️ Les défauts de DDD ont en revanche été repérés par de nombreuses équipes : la méthode est exigeante, tant en compétences qu’en organisation. Globalement si vous n’avez pas une équipe de développeurs et d’experts métiers confirmés, habitués à travailler ensemble et une organisation agile mûre, commencez par cela.
SOURCE
Özkan, Ozan, Önder Babur and Mark van der Brand. “Domain-Driven Design in Software Development: A Systematic Literature Review on Implementation, Challenges, and Effectiveness.” ArXiv abs/2310.01905 (2023): DOI: 10.48550/arXiv.2310.01905
📄 Lien public
DOIs:
10.48550/arXiv.2310.01905
Encapsulation of legacy software: A technique for reusing legacy software components 🔗
🧩 Design (Anti-)Patterns
·
📐 Architecture
🏚️ Parmi les composants obsolètes*, les plus difficiles à gérer sont ceux dont la technologie sous-jacente est dépréciée, voire abandonnée.
📦 Faut-il reprendre ou refaire de tels composants ? La question n’admet aucune réponse générale, trop de paramètres sont contextuels. Dans le cas où l’on choisit de reprendre, deux options s’offrent à nous : encapsuler ou adapter. Plus exactement, il s’agit d’un continuum, car l’encapsulation parfaite, celle qui ne requiert aucune adaptation, n’existe souvent pas.
🧑⚕️ L’encapsulation peut s’effectuer à plusieurs niveaux. Dans le plus grossier, le programme est lancé avec des entrées forgées, ses sorties sont converties dans le format du nouveau système. Dans le plus fin, le code du composant obsolète est modifié afin d’accepter les entrées telles que le requiert le nouveau sytème. Ce dernier est bien plus chronophage que le premier niveau.
⌛ La technologie était déjà mûre en 2000 quand ce papier a été écrit. Encapsuler est bien moins coûteux qu’un redéveloppement, mais au prix d’une fuite en avant. Maintenir le composant obsolète sous cloche sera de plus en plus difficile avec le temps. Ca n’est jamais une solution définitive, mais un moyen d’acheter du temps, afin de refaire le composant ou de modifier le besoin qui en est à l’origine.
* L’auteur utilise le terme de Legacy, impropre ici.
SOURCE
Sneed, H.M. Encapsulation of legacy software: A technique for reusing legacy software components. Annals of Software Engineering 9, 293–313 (2000). DOI:10.1023/A:1018989111417
📄 Lien public
DOIs:
10.1023/A:1018989111417
Iterative reengineering of legacy functions 🔗
🧩 Design (Anti-)Patterns
·
📐 Architecture
Ce que l’on connaît aujourd’hui sous le nom de Strangler Pattern en architecture trouve ses racines en 2001 dans un papier de 4 chercheurs italiens. Pour rappel, il s’agit d’encapsuler un composant Legacy afin de remplacer une à une ses fonctionnalités par leur équivalent dans une codebase propre. Les deux codebase cohabitent jusqu’à la fin du processus et la mort du Legacy se produit quand plus rien ne peut en être extrait.
Le papier décrit en détail le processus et donne un exemple. Le principe de tests d’équivalence, cousins des tests de non-régression est évoqué, afin de s’assurer que le nouveau système remplit le même service que l’ancien.
SOURCE
A. Bianchi, D. Caivano, V. Marengo and G. Visaggio, “Iterative reengineering of legacy functions,” Proceedings IEEE International Conference on Software Maintenance. ICSM 2001, Florence, Italy, 2001, pp. 632-641, doi:10.1109/ICSM.2001.972780
📄 Lien public
DOIs:
10.1109/ICSM.2001.972780
Cognitive biases in Software Development 🔗
🧠 Psychologie
🧠 Les biais cognitifs altèrent notre raisonnement et peuvent conduire à des comportements suboptimaux, voire socialement nocifs. La pandémie du Covid-19 fut un véritable étalage de biais de confirmation en bas et d’arguments d’autorité en haut, conduisant à une gestion hasardeuse de l’épidémie. Les développeurs n’échappent pas à ces biais dans leur activité. N’étant pas formés aux limites de leur cerveau, ils n’adaptent pas leur manière de travailler à ce fait.
🕵️ Une équipe de chercheurs a trouvé 28 biais en observant 10 développeurs dans leur travail quotidien, puis en interviewant 18 autres développeurs. Ils ont été rassemblés en 10 catégories. Pour chacune d’entre elles, les conséquences sur le code ont été analysées et des solutions ont été proposées.
🔧 Beaucoup de biais peuvent être évités par des améliorations de l’outillage, le biais de confort peut ainsi être corrigé par un outil suggérant une manière plus optimale d’effectuer une opération, comme le font les IDE de Jetbrains par exemple.
🤏 Le papier est court, suffisamment pour qu’un résumé plus exhaustif soit peu efficient.
SOURCE
Souti Chattopadhyay, Nicholas Nelson, Audrey Au, Natalia Morales, Christopher Sanchez, Rahul Pandita, and Anita Sarma. 2022. Cognitive biases in software development. Commun. ACM 65, 4 (April 2022), 115–122. DOI:10.1145/3517217
📄 Lien public
DOIs:
10.1145/3517217
Concept-centric software development 🔗
🧠 Psychologie
·
🗣️ Nommage
💭 Quand un programme mue en véritable système, la cohérence des concepts devient un véritable tour de force. Les meilleurs n’échappent pas à ce problème et le journaliste tech Casey Newton se moquait de Google en tweetant : “Google Reminders est maintenant Google Tasks. Pour créer un Reminder, utilisez Calendar. Pour créer une Task, utilisez GMail. N’utiliser PAS Keep”. Ce phénomène est appelé par les auteurs “Entropie conceptuelle”.
🔮 Palantir a atténué ce problème en créant un dépôt centralisé de concepts, utilisé par les parties prenantes de ses différents logiciels. Ce projet répondait à la complexification croissante de l’ontologie interne, nécessitant un format commun pour standardiser des quantités invraisemblables de notes, mémos et autres documents de nature conceptuelle.
📚 Au sein de la complexité des logiciels, peu considèrent la complexité conceptuelle : quand des fonctionnalités sont créées, changées, remplacées, les concepts qui les accompagnent se décalent progressivement de leur définition d’origine. La solution est la même que pour le code : un refactoring régulier afin de réaligner les concepts avec leur définition. Seuls les outils varient : ils empruntent plus au knowledge management qu’au développement
SOURCE
Wilczynski, Peter A., Taylor Gregoire‐Wright and Daniel Jackson. “Concept-centric Software Development.” ArXiv abs/2304.14975 (2023) DOI:10.48550/arXiv.2304.14975
📄 Lien public
DOIs:
10.48550/arXiv.2304.14975
An approach for experimentally evaluating effectiveness and efficiency of coverage criteria for software testing 🔗
🧪 Tests
🧪 Un jeu de tests peut être efficace sans être efficient. L’efficacité désigne la capacité à détecter des défauts ou des régressions. L’efficience consiste à maximiser cette capacité de détection en fonction du nombre de tests. Cette distinction est important : les tests coûtent à écrire et personne ne veut voir 15 tests passer au rouge à la première évolution de son code.
🇮🇳 Deux chercheurs indiens ont voulu vérifier la corrélation entre critère de coverage (branch, statement …) et efficience du jeu de test minimal permettant de le satisfaire sur un code donné.
📶 L’intérêt de l’expérience est plutôt limitée pour le praticien, le coverage n’étant pas un indicateur fiable de la qualité d’une suite de tests. Les résultats en revanche sont intéressants : ils montrent une relation quasi-linéaire entre effort de test et efficicacité. Autrement dit nous ne connaissons pas de méthode de test miracle, offrant une efficience d’un ordre de grandeur supérieure aux autres. Nous sommes, dans l’état actuel des connaissances, condamnés à devoir tester plus pour sécuriser plus.
⚠️ Cette conclusion doit néanmoins être prise avec du recul : l’usage de mutants et la génération automatisée de tests confine ces conclusions au monde des tests unitaires. Il est impossible de déduire quoi que ce soit pour les tests de niveau supérieurs, souvent les plus utiles aux praticiens. Ce papier servira donc principalement à d’autres chercheurs, non aux développeurs.
SOURCE
Gupta, Atul & Jalote, Pankaj. (2008). An approach for experimentally evaluating effectiveness and efficiency of coverage criteria for software testing. STTT. 10. 145-160. DOI:10.1007/s10009-007-0059-5.
DOIs:
10.1007/s10009-007-0059-5
Security Risks in the Software Development Lifecycle: A Review 🔗
La sécurité des logiciels commence dès l’écriture du code. Un logiciel bien-né posera bien moins de défis à sécuriser qu’un infect bourbier. Trois chercheurs Kenyans nous proposent une revue de littérature exhaustive sur ce sujet autour de 3 questions : d’où viennent les vulnérabilités, quelles en sont les conséquences et comment les résoudre ?
Nous y apprenons que les vulnérabilités naissent du manque de connaissance ou de la nonchalance des développeurs, ainsi que de la faible priorisation de la sécurité par les product owners. Ces considérations sont jugées trop peu rémunératrices par des équipes sous-pression à court-terme. Autrement dit, les incitatifs à faire du code sécurisé sont encore trop faibles, alors même que l’on sait que les vulnérabilités sont plus coûteuses lorsque corrigées tardivement.
La partie sur les conséquences est la plus faible, la littérature disponible est trop maigre. Notre profession n’a pas l’habitude de publier ses rapports d’incidents. Il s’agit d’ailleurs d’un énorme problème pour la recherche. Rappelons-nous que l’aviation a progressé ainsi.
Enfin, les auteurs détaillent les nombreuses solutions disponibles, allant de la revue de code appuyée par un professionnel de la sécurité du code à l’analyse statique.
Ce papier est surtout une immense mine de sources et un bon point de départ pour qui s’intéresse au sujet.
SOURCE
Odera, David & Otieno, Martin & Ounza, Jairus. (2023). Security Risks in the Software Development Lifecycle: A Review. 8. 230–253. DOI:10.30574/wjaets.2023.8.2.0101.
📄 Lien public
DOIs:
10.30574/wjaets.2023.8.2.0101
Toward remaking Software Development to Secure it 🔗
👔 Avis d'expert
·
👌 Qualité logicielle
L’ensemble des pratiques actuelles visant à sécuriser le développement de logiciels adoptent une approche accidentelle et réactive : les attaques sont analysées, catégorisées et les développeurs (éventuellement) formés. Cette pratique est défaillante : la sécurité a toujours un train de retard sur les attaquants.
Une piste prometteuse pour résoudre ces défis est le développement basé sur les propriétés, un paradigme émergent en développement. Ce paradigme permettrait par exemple d’empêcher des données sensibles de passer d’un composant sécurisé à un ne l’étant pas. L’auteur soutient que le flux de données est une propriété contrôlable dans un logiciel : un flux de données correctement encapsulé peut n’autoriser l’accès à son contenu qu’en échange d’identifiants valides.
L’idée est intéressante, je compte l’expérimenter de mon côté en attendant que des chercheurs testent ce qui n’est pour le moment qu’un avis d’expert.
SOURCE
Jenkins, Jonathan. “Toward Remaking Software Development to Secure It.” The Journal of the Southern Association for Information Systems (2022): n. pag. DOI: 10.17705/3jsis.00020
📄 Lien public
DOIs:
10.17705/3jsis.00020
A Case Study on Design Patterns and Software Defects in Open Source Software 🔗
🧩 Design (Anti-)Patterns
🏗️ Corrélation n’est pas causalité, mais l’usage de certains design patterns, comme Adapter, Command, Observer, State, Strategy, Template et Proxy réduisent de manière significative le nombre de défauts.
🧑💼 Ce résultat est obtenu par minage de projets open-source. Il n’est pas précisé si des résultats similaires ont été obtenus sur des projets commerciaux.
SOURCE
Onarcan, M. and Fu, Y. (2018) A Case Study on Design Patterns and Software Defects in Open Source Software. Journal of Software Engineering and Applications, 11, 249-273. DOI:10.4236/jsea.2018.115016
📄 Lien public
DOIs:
10.4236/jsea.2018.115016
Software development: do good manners matter ? 🔗
🧠 Psychologie
🙊 Si un ticket n’avance pas assez vite, insultez les mamans des développeurs. Non seulement vous aurez passé vos nerfs, mais de surcroît il avancera encore moins vite, ce qui vous offrira l’occasion de redoubler d’injures.
🎩🤌 Un équipe italo-britannique confirme que la politesse des commentaires influe sur la priorisation des tickets, mais également sur l’attractivité de ceux-ci pour les développeurs. Plus le langage est fleuri, moins les mainteneurs se pressent pour résoudre un problème et plus ils tendent à attribuer une priorité basse au ticket.
🤰 L’étude portait sur des projets open-source, les auteurs ne précisent pas si leurs conclusions sont applicables en entreprise. Dans le doute, n’insultez pas les mamans des développeurs.
SOURCE
Destefanis G, Ortu M, Counsell S, Swift S, Marchesi M, Tonelli R. 2016. Software development: do good manners matter? PeerJ Computer Science 2:e73 DOI:10.7717/peerj-cs.73
📄 Lien public
DOIs:
10.7717/peerj-cs.73
Self-collaboration Code Generation via ChatGPT 🔗
🧮 Méthodes de développement
🤖 ChatGPT est à la mode, selon ses partisans capables de changer l’humanité. Revenons sur terre avec un papier proposant de générer du code à l’aide de 3 instances ChatGPT 3.5, promptées pour occuper 3 rôles classiques, bien que dépassés, de la production de logiciels : analyste, codeur et testeur.
🔮 Les auteurs y font collaborer 3 instances du célèbre modèle de langage afin de générer du code, avec de meilleurs résultats que les modèles génératifs les plus récents, meilleurs même que ChatGPT 4 pris seul. Est-ce l’avenir du développement ? Pas vraiment si l’on analyse le papier.
🧮 Afin d’évaluer le modèle, les auteurs comparent ses résultats à des catalogues de problèmes algorithmiques. L’enoncé est donné au ChatGPT-analyste, qui collabore avec ses deux collègues. La solution est comparée au corrigé. Il s’agit donc d’épreuves d’algorithmique, non de développement de logiciels, qui dépasse largement ce seul travail.
📝 L’expérimentation a deux variantes : dans la première le modèle reçoit seulement une description du problème en langage naturel. Dans la seconde, la signature de la méthode attendue et les tests unitaires lui sont fournis. Hélas, il est difficile de savoir à quelle variante les résultats présentés dans le papier sont attribuables.
🧠 De l’aveu même des auteurs, ce modèle n’offre pas de résultats satisfaisants à des niveaux d’abstraction supérieurs à la fonction. Or il s’agit de la majorité de la plus-value d’un développeur. Cependant ce papier offre une piste sérieuse à une hypothèse personnelle : les outils capables de générer un code minimal passant un test du rouge au vert sont proches, accélérant le cycle TDD. Le développeur pourra alors se concentrer sur les étapes où son cerveau est le plus pertinent : le refactoring et l’écriture dudit test.
SOURCE
Dong, Yihong, Xue Jiang, Zhi Jin and Ge Li. “Self-collaboration Code Generation via ChatGPT.” ArXiv abs/2304.07590 (2023), DOI: 10.48550/arXiv.2304.07590
📄 Lien public
DOIs:
10.48550/arXiv.2304.07590
Computer system reliability and nuclear war 🔗
⚙️ Technocritique
·
💩 Cas d'échecs
🚀 Le 3 juin 1980, un radar américain détecte deux missiles nucléaires lancés par des sous-marins. 18 secondes plus tard, ils sont indénombrables. Quelques secondes plus tard … plus rien. Vinrent ensuite des alertes montrant des missiles intercontinentaux, au Pentagone cette fois-ci. Les pilotes de B-52 ont ordre de décoller, jusqu’à un contre-ordre quelques minutes plus tard : fausse-alerte.
🐛 Dans l’espoir de reproduire le problème, le NORAD ne touche à rien. L’évènement se reproduit 3 jours plus tard et une puce est incriminée. Son défaut provoquait des confusions entre les scénarios de test, exécutés fréquemment, et de vraies attaques.
🌙 Ce bug n’est pas isolé, en 1960 le NORAD confondait une attaque soviétique et la lune. Sachant cela, est-il prudent de laisser le contrôle d’armes nucléaires à des machines ? Compte-tenu de la consommation d’alcool et de drogues rapportée par les services de santé des deux côtés du Rideau de Fer, l’humain ne ferait pas mieux.
⚛️ Comment piloter la dissuasion nucléaire, alors ? Notre technologie est aussi limitée que nous, notre honte prométhéenne est largement psychologique. Tout système est fondamentalement limité par notre capacité à écrire des spécifications complètes. Nous ne sommes pas des dieux omniscients.
💥 Alan Borning nous répond que la solution n’est pas technologique, mais politique. Les limitations technologiques sont indépassables, c’est au politique de s’assurer de ne jamais être en situation où une machine prend seule une décision, surtout si celle-ci est un tir nucléaire. L’accumulation de Close Call de la guerre froide prouve l’intérêt de la redondance machine-machine, machine-humain et surtout humain-humain, le plus le mieux. Hélas l’urgence réelle ou supposée des situations pousse à réduire les redondances.
SOURCE
Borning, Alan. “Computer system reliability and nuclear war.” Commun. ACM 30 (1987): 112-131. DOI:10.1145/12527.12528
📄 Lien public
DOIs:
10.1145/12527.12528
When Only Random Testing Will Do 🔗
🧪 Tests
🎲 Les tests aléatoires sont mal vus. Au mieux un moyen de découvrir des bugs supplémentaires, au pire une stratégie de la dernière chance. Dick Hamlet tente de les réhabiliter et d’en faire la méthode de test de première intention pour deux classes de problèmes.
🎆 Lorsque le nombre de cas de test possibles pour un composant est trop élevé et qu’il n’est pas possible de repérer des valeurs limites pertinentes, on parle d’éparpillement des échantillons (sparse sampling). Il s’agit du premier cas dans lequel l’aléatoire s’en sort mieux que le déterminisme.
💾 Quant un programme manipule un état persistent, les développeurs tendent à abstraire celui-ci afin de contourner le problème. Ce faisant ils ne s’y attaquent pas vraiment. L’aléatoire peut résoudre ce problème. Il faut voir un test comme une série d’actions réalisées à partir d’un état persistent de départ. Ici, l’aléatoire concerne quelles actions seront réalisées dans quel ordre, non les valeurs injectées. Cette seconde partie est plus exigeante à lire.
🔀 L’auteur souligne que les méthodes présentées ne remplacent pas les tests déterministes, mais les complètement. Ainsi un même composant peut parfaitement être testé sous ces deux modes pour en tirer le meilleur.
SOURCE
Dick Hamlet. 2006. When only random testing will do. In Proceedings of the 1st international workshop on Random testing (RT ‘06). Association for Computing Machinery, New York, NY, USA, 1–9. DOI:10.1145/1145735.1145737
DOIs:
10.1145/1145735.1145737
Explicit Namespaces 🔗
🔣 Science des Langages
·
🗣️ Nommage
🗣️ La notion d’espace de nom est plus vaste que les “namespace” de C++ ou C#. Les packages de Java, les interfaces ou encore les scopes de Javascript sont des espaces de nom. Un espace de nom, pour étendre la définition, est un mécanisme permettant de retrouver un objet donné à partir d’un nom dans un contexte.
🪨 L’histoire commence avec des espaces de nom inflexibles. Deux globales ont le même nom ? Le programme plante. Vinrent ensuite les espaces de nom fixes, comme en java. Avec un préfixe unique à l’échelle d’Internet, chaque composant est libre d’utiliser les noms qu’il souhaite sans se soucier des autres. Les espaces de nom restreints suivent : c’est Python ou Javascript où chaque fichier possède son espace de nom. La globalisation nécessite un mot clé particulier. Enfin, l’état de l’art actuel utilise les conteneurs d’injection de dépendance afin de résoudre des dépendances nommées quand c’est nécessaire.
📦 Pour les auteurs, toutes ces méthodes doivent être dépassées par des langages incluant une gestion dynamique des espaces de nom : chaque composant s’exécute dans un contexte, incluant un espace de noms sur lequel l’appelant a un total contrôle. Le langage expérimental Piccola est de ceux-ci.
🧑🏫 L’inconvénient ? Les espaces de noms dynamiques sont extrêmement peu intuitifs pour nos cerveaux et un énorme effort pédagogique, absent de ce papier, est nécessaire. Un tel paradigme n’est prometteur qu’à mesure qu’il est utilisable par le commun des mortels.
SOURCE
Achermann, Franz and Oscar Nierstrasz. “Explicit Namespaces.” Joint Modular Languages Conference (2000). DOI:10.1007/10722581_8
📄 Lien public
DOIs:
10.1007/10722581_8
Property-Based Software Engineering Measurement 🔗
👌 Qualité logicielle
📏 Notre métier est paradoxal, artisanal oserais-je dire. Le consensus sur les pratiques se fait naturellement, sans nécessiter de lourdes études pour trancher la plupart des débats. A contrario, celui sur les mesures est hérissé d’objections, de controverses et finalement n’a jamais vraiment émergé. Mesurer les logiciels est une gageure, encore en 2023.
🧮 En 1996, une percée majeure a été faite par trois chercheurs. Ils ont utilisé la théorie des ensembles afin d’obtenir des mesures fiables des logiciels, basées sur les composants et leurs interactions. Ils ont redéfini des mesures connues auparavant de manière formelle, comme le couplage, la complexité et la cohésion, mais ils ont aussi fait progresser le débat en séparant les mesures précédentes de “volume” des logiciels en deux mesures plus pertinentes : la taille (size) et la longueur (length) d’un logiciel.
🏫 Le papier nécessite quelques connaissances en logique et en algèbre pour être compris, mais rien d’insurmontable, un niveau légèrement supérieur au lycée suffit.
❓Le papier ne dit cependant pas à quoi peuvent bien servir ces mesures dans le quotidien des développeurs, mais ce problème est là depuis les origines de notre métier : nous n’avons jamais su quoi en faire.
SOURCE
Briand, Lionel Claude, Sandro Morasca and Victor R. Basili. “Property-Based Software Engineering Measurement.” IEEE Trans. Software Eng. 22 (1996): 68-86. DOI: 10.1109/32.481535
📄 Lien public
DOIs:
10.1109/32.481535
Programmers use slices when debugging 🔗
#️⃣ Façonnage de code
🐛 Lorsque nous débuggons, nous n’utilisons pas les mêmes représentations mentales que lorsque nous programmons. En réalisant un code, nous pensons les blocs que nous construisons. Lorsqu’il s’agit de le corriger, nous adoptons une autre représentation mentale que Mark Weiser nomme les Slices.
🔪 Une Slice s’obtient en retirant tout ce qui ne nous semble pas faire partie de la cause d’un bug dans un code. Ne restent à la fin qu’une poignée de variables et de méthodes éparses, que le développeur pense être de bons candidats pour l’origine du bug. Ces Slices sont rarement composés de morceaux de code contigus.
💡 Cette découverte n’apporte rien en elle-même, mais a ouvert la voie à de nombreux papiers en pédagogie du développement, en maintenance, en psychologie, etc.
SOURCE
Weiser, Mark D. “Programmers use slices when debugging.” Commun. ACM 25 (1982): 446-452. DOI:10.1145/358557.358577
📄 Lien public
DOIs:
10.1145/358557.358577
Software Safety: Why, What, How 🔗
👌 Qualité logicielle
☠️ Un constat n’a pas pris une ride depuis 1986 : la sûreté des sytèmes s’effondre dès que l’on y introduit des logiciels. L’auteur, Nancy Leveson est avec Robert Glass un catalogue vivant des échecs de notre profession. Mars Polar Lander, le funeste Therac 25 ou le récent F-35 sont autant de rappels que la sûreté des logiciels est un véritable sujet.
☔ Ce papier est une introduction complète à une nouvelle matière : la sûreté des logiciels, une branche de la sûreté des sytèmes, qui se sont massivement informatisés dans les années 80. L’auteur balaye les problèmes essentiels et accidentels qui rendent le logiciel dangereux, en particulier s’il sert à piloter des machines aussi inoffensives que des missiles nucléaires ou des avions de combat.
🪱 La conclusion est presque technocritique : dans certains systèmes où le risque dépasse les innombrables bénéfices de l’informatique, peut-être vaut-il mieux s’abstenir d’introduire le ver logiciel dans le fruit de la sûreté.
SOURCE
Nancy G. Leveson. 1986. Software safety: why, what, and how. ACM Comput. Surv. 18, 2 (June 1986), 125–163. DOI:10.1145/7474.7528
📄 Lien public
DOIs:
10.1145/7474.7528
Evaluating the effect of a delegated versus centralized control style on the maintainability of object-oriented software 🔗
👌 Qualité logicielle
·
#️⃣ Façonnage de code
💎 Un style de design jugé “plus élégant” qu’un autre par les plus expérimentés est-il forcément plus maintenable ? Non, car il est très fréquent que la maintenance soit exercée par des juniors qu’un style trop complexe. L’étude d’Arisholm et Sjøberg rappelle que la maintenabilité est relative à ceux qui maintiendront. Un logiciel n’est pas maintenable “dans l’absolu”, mais par rapport aux compétences de l’équipe de maintenance.
SOURCE
Arisholm, Erik and Dag I.K. Sjøberg. “Evaluating the effect of a delegated versus centralized control style on the maintainability of object-oriented software.” IEEE Transactions on Software Engineering 30 (2004): 521-534. DOI: 10.1109/TSE.2004.43
📄 Lien public
DOIs:
10.1109/TSE.2004.43
The prediction ability of experienced software maintainers 🔗
🧮 Méthodes de développement
⏱️ Peut-on se fier aux développeurs pour estimer la durée d’une tâche de maintenance ? Non.
⭐ Peut-on se fier aux plus expérimentés pour faire légèrement mieux ? De manière presque imperceptible.
🎲 Ne demandez pas d’estimations aux développeurs. Roulez un dé, vous gagnerez du temps.
SOURCE
Jørgensen, Magne, Dag I.K. Sjøberg and Geir Kirkebøen. “The prediction ability of experienced software maintainers.” Proceedings of the Fourth European Conference on Software Maintenance and Reengineering (2000): 93-99. DOI:10.1109/CSMR.2000.827317
DOIs:
10.1109/CSMR.2000.827317
A comparison of methods for locating features in legacy software 🔗
#️⃣ Façonnage de code
·
🧪 Tests
🏚️ Lorsqu’il s’agit de savoir quels morceaux de code legacy sont reliés à une feature que l’on veut éditer, nous avons plusieurs outils à notre disposition, tous complémentaires.
🔍 Le plus simple est le bon vieux Ctrl+F/grep. Rapide, mais peu précis, il est très dépendant à la qualité du nommage, rarement exemplaire dans le code legacy. Les auteurs le recommandent en première intention, pour se familiariser avec le code.
🔦 Vient ensuite la reconnaisance logicielle, utilisant des tests afin de repérer quelles parties du code sont appelées par ceux-ci. Cette méthode est détaillée sur cette veille 10.1109/ICSM.1992.242542. Il s’agit de la méthode la plus fiable, mais aussi de la plus lourde à mettre en place. Elle est en outre incapable de repérer des concepts, contrairement aux deux autres.
🪢 Enfin, les graphes de dépendance peuvent parfois servir, mais il dépendent d’une bonne structuration du code en module, rarement présente dans les code legacy.
🧰 Ces trois outils se complètent dans la boîte à outils du développeur faisant face au code legacy.
SOURCE
Wilde, Norman, Michelle Buckellew, Henry Page, Václav Rajlich and LaTreva Pounds. “A comparison of methods for locating features in legacy software.” J. Syst. Softw. 65 (2003): 105-114. DOI:10.1016/S0164-1212(02)00052-3
📄 Lien public
DOIs:
10.1016/S0164-1212(02)00052-3
Locating user functionality in old code 🔗
#️⃣ Façonnage de code
·
🧪 Tests
🏚️ Outre leurs nombreux bienfaits, les tests permettent aussi de localiser les fragments de code legacy impliqués dans une fonctionnalité donnée. Le principe est le même que les marqueurs en médecine nucléaire : mettez sous surveillance l’ensemble du code, en journalisant tous les appels à toutes les méthodes. Les outils modernes de code coverage permettent un suivi ligne à ligne. Une fois ce harnais posé, écrivez un jeu de tests utilisant la fonctionnalité à éditer.
💡 L’ensemble des méthodes appelées par votre test contiennent potentiellement des fragments de la fonctionnalité à éditer. Ce résultat reste à raffiner, mais la recherche montre un gain de temps potentiel par rapport à une recherche à la main.
SOURCE
Wilde, Norman, Juan Ángel Gómez, Thomas A. Gust and Don Strasburg. “Locating user functionality in old code.” Proceedings Conference on Software Maintenance 1992 (1992): 200-205. DOI: 10.1109/ICSM.1992.242542
DOIs:
10.1109/ICSM.1992.242542
What can commit metadata tell us about design degradation ? 🔗
#️⃣ Façonnage de code
·
🦨 Code Smells
📏 Les métriques fiables et utiles manquent aux développeurs et l’analyse statique du code piétine. Cependant un second filon est plus prometteur : le minage de commits. Il consiste en l’analyse des changements sur un VCS. Quatre chercheurs brésiliens ont réussi à quantifier la fragilité et la rigidité d’un code, deux mesures de Robert C. Martin, en mesurant les propriétés d’une série de commits.
💥 Si un commit édite de nombreux fichiers, il est dit dense, ce qui est une odeur indiquant une rigidité potentielle. La notion se rapproche de la shotgun surgery.
🪢 Si un commit touche à de nombreux fichiers éloignés dans l’arborescence, il est dit dispersé, ce qui est un odeur indiquant une fragilité potentielle.
💎 La méthode fonctionne, mais rencontre deux limites : la première est son inapplicabilité sans pré-traitement des commits. Merge commits, changements de style, documentation … ces changements polluent les mesures et les faussent, il faut donc un moyen de les exclure des calculs. La seconde est la nécessité pour les développeurs de respecter strictement le principe d’une feature par commit. Sans cela les facteurs de confusion rendent inopérante la méthode.
SOURCE
Oliva, Gustavo Ansaldi, Igor Steinmacher, Igor Scaliante Wiese and Marco Aurélio Gerosa. “What can commit metadata tell us about design degradation?” International Workshop on Principles of Software Evolution (2013).
📄 Lien public
DOIs:
10.1145/2501543.2501547
Three steps to views: extending the object-oriented paradigm 🔗
🔣 Science des Langages
💡 Le papier du jour décrit un mécanisme d’extension du paradigme objet n’ayant pas eu de suite, mais là encore, intéressant tant historiquement, car ses prémisses ont été implémentées, que comme point de vue novateur sur nos logiciels.
🧠 Pour les auteurs, la difficulté intellectuelle principale du code est notre capacité limité à nous représenter de gros objets ou un grand nombre de petits objets en interaction. Afin d’être manipulé, un tel système pourrait être synthétisé sous forme d’une vue, ne présentant que les éléments utiles au problème à résoudre.
👀 Le concept de vues est antérieur, il vient du monde des bases de données. Les auteurs proposent d’implémenter un mécanisme similaire dans les langages objet. Pour cela il faut 3 éléments successifs, qui manquaient à l’appel dans les langages objet de l’époque.
1️ Le premier élément est la capacité d’une classe à implémenter plusieurs interfaces. Ce point est évident pour nous en 2023, il ne l’était pas en 1989.
2️ Le second élément est la visibilité différenciée des variables d’un objet selon l’interface consommée. Là encore, rien de novateur pour nos yeux de 2023, C# le fait depuis les années 2000 avec les propriétés, que l’on peut définir en lecture seule dans une interface et en écriture dans une autre.
3️ Le dernier élément est la capacité pour les objets d’offrir une copie différente de leurs variables à chaque invocation d’une interface. A quoi cela sert ? A versionner, chaque instance de vue est une réprésentation du système à un moment, rafraîchir la vue revient à demander à celle-ci une nouvelle instance d’elle-même.
⏭️ Ce dernier élément n’est pas passé à la postérité, même si on peut le considérer comme un précurseur des techniques d’event sourcing.
🤝 Pour les auteurs, le principal bénéfice de ce système est la capacité pour une entité à éditer des composants logiciels ayant seulement des vues pour contrat. Ainsi libre à cette entité de refondre complètement l’implémentation sous-jacente sans se soucier des consommateurs tant que la vue ne change pas.
SOURCE
Shilling, John J. and Peter F. Sweeney. “Three steps to views: extending the object-oriented paradigm.” Conference on Object-Oriented Programming Systems, Languages, and Applications (1989). DOI:10.1145/74877.74914
📄 Lien public
DOIs:
10.1145/74877.74914
Foundations for the study of software architecture 🔗
💾 Histoire de l'informatique
🏗️ Perry et Wolf n’ont pas à proprement parler inventé l’architecture. L’honneur revient à Schwanke qui, le premier, eut l’idée de connecter des composants pour créer ce niveau supérieur d’abstraction. Cependant, Perry et Wolf ont réellement fondé cette discipline aux côtés de Garlan en Shaw, déjà évoqués ici.
🏛️ Il ont pris pour modèle l’architecture en bâtiment, après avoir éliminé l’idée de prendre l’architecture hardware ou encore réseau, en raison de leurs différences inconciliables avec le logiciels. Peu naïfs, ils furent conscients des problématiques propres au logiciel et n’ont pas niaisement copié le savoir-faire de bâtisseurs de gratte-ciel.
🎨 Alors que le code est plus souple que le béton, chaque nouveau système est par essence sa propre architecture. Il est possible de trouver des traits communs, les styles architecturaux, mais les jeux de contraintes appliqués à chaque système sont trop dépendants du besoin pour être reproduits. Prudents, les auteurs ne s’avancent pas sur le caractère essentiel ou accidentel de cette propriété (contrairement aux partisans de l’ingénierie du logiciel).
🔗 L’architecture logicielle s’inspire mais ne copie pas. Pour Perry et Wolf, nous disposons de 3 éléments simples, les composants qui traitent la donnée, les connecteurs qui relient les composants et la donnée elle-même. Définir une architecture c’est donc créer un jeu de contraintes, définissant quelles catégories de composants peuvent être reliés à quelles autres et dans quelles conditions.
💡 S’arrêter là serait incomplet et ménerait à la dégénérescence ou à l’érosion de l’architecture ainsi conçue au fil des itérations. Il faut également expliciter le raisonnement derrière l’architecture et le diffuser, sinon les designers et développeurs vont à coup sûr rater la cible lors de l’implémentation. Pourtant, combien de maniaques du schéma format A1 font exactement cela en entreprise, se croyant supérieurs aux développeurs ?
SOURCE
Perry, Dewayne E. and Alexander L. Wolf. “Foundations for the study of software architecture.” ACM SIGSOFT Softw. Eng. Notes 17 (1992): 40-52. DOI:10.1145/141874.141884
DOIs:
10.1145/141874.141884
Social Identity in Software Development 🔗
🧠 Psychologie
🏰 Au sein d’une entreprise, les développeurs tendent à mieux communiquer entre eux qu’avec les autres parties prenantes des projets. En résulte une très forte identité de groupe, créant des barrières entre les développeurs et les autres. Il n’est pas souhaitable de dissoudre ces groupes forts, qui sont gage de productivité sur des tâches complexes.
👽 Ces barrières sont bidirectionnelles, les non-développeurs jugent les développeurs arrogants, peu impliqués, voire improductifs. A l’inverse, les développeurs se voient comme des étrangers, des invités ponctuels parmi les non-développeurs.
🚀 Il est possible de réconcilier développeurs et non-développeurs grâce à un pattern organisationnel : les groupes de support éphémères. Des développeurs et des parties-prenantes se réunissent en “Task Force” afin de livrer une fonctionnalité ou de surmonter une difficulté. Ce groupe s’auto-dissout une fois son objectif accompli, afin que les développeurs ne le vivent pas comme une dilution de leur identité de groupe.
SOURCE
Bäckevik, Andreas, Erik Tholén and Lucas Gren. “Social Identity in Software Development.” 2019 IEEE/ACM 12th International Workshop on Cooperative and Human Aspects of Software Engineering (CHASE) (2019): 107-114. DOI:10.1109/CHASE.2019.00033
📄 Lien public
DOIs:
10.1109/CHASE.2019.00033
Comparing non-adequate test suites using coverage criteria 🔗
🧪 Tests
🧮 La recherche sur les tests est gourmande en puissance de calcul. Elle fait appel dans de nombreux cas au score de mutation d’un jeu de tests afin d’en estimer l’efficacité réelle. Or cette opération est coûteuse, même si d’un ordre de grandeur plus précise que le coverage.
📊 Le papier du jour restreint la question : si l’on doit classer des jeux de tests du plus efficace au moins efficace, le coverage est-il une méthode acceptable ? Il ne s’agit pas ici de quantifier ou d’estimer, mais de classer par ordre d’adéquation.
💵 La réponse est oui, le coverage, bien moins couteux que le score de mutation, offre un moyen rapide de classer des jeux de test, par exemple pour éliminer ceux qui ne sont pas pertinents dans une étude, avant d’effectuer des mesures plus compliquées uniquement sur ceux retenus.
SOURCE
Gligoric, M., Groce, A., Zhang, C., Sharma, R., Alipour, M. A., & Marinov, D. (2013). Comparing non-adequate test suites using coverage criteria. In 2013 International Symposium on Software Testing and Analysis, ISSTA 2013 - Proceedings (pp. 302-313). (2013 International Symposium on Software Testing and Analysis, ISSTA 2013 - Proceedings). DOI:10.1145/2483760.2483769
DOIs:
10.1145/2483760.2483769
Attention span during lectures: 8 seconds, 10 minutes, or more ? 🔗
🧠 Psychologie
·
🧑🏫 Pédagogie
🧑🎓 Les étudiants sont attentifs au maximum 10 minutes, donc les cours magistraux appartiennent au passé ! Tout le monde a déjà entendu ce lieu commun, qui saute à pieds joints dans le biais d’appel à la nouveauté. Cours magistraux = pré-1968 = 💩. Sauf que les 10 min d’attention des étudiants sont un mythe. Débunk.
🎯 Le mythe ne vient pas de nulle part, des sommités de la pédagogie ont relayé ce chiffre. Pourtant aucune preuve ne l’appuie. Pire, depuis 1978 toutes les tentative d’en prouver la réalité ont tapé à côté ou échoué.
💤 On sait aujourd’hui que le temps d’attention dépend principalement de l’enseignant. Quelqu’un de barbant lassera avant 10 minutes, alors qu’avec professeur intéressant, l’heure peut être dépassée sans dommages.
🧨 La recherche a aussi montré que tout cours a ses temps forts, correspondant aux notions-clés. Si l’enseignant prend le temps d’insister sur l’importance d’une notion, il fait immédiatement remonter l’attention de ses étudiants pour les minutes suivantes.
⏱️ Enfin, sur la base de mesures physiologiques, il semble que la période la plus propice à la rétention des savoirs se situe entre 15 min et 30 min après le début du cours.
🚫 Les auteurs terminent en rappelant que le cours magistral fut un temps passé de mode, donc que le moindre chiffre pouvant justifier cette disgrâce fut utilisé. Pourtant l’état des connaissances est clair : il n’y a pas mieux pour une entrée en matière, même (et surtout) à l’heure d’Internet. Les autres méthodes restent pertinentes pour approfondir.
SOURCE
Bradbury NA. Attention span during lectures: 8 seconds, 10 minutes, or more? Adv Physiol Educ. 2016 Dec 1;40(4):509-513. doi: 10.1152/advan.00109.2016
📄 Lien public
DOIs:
10.1152/advan.00109.2016
A law-based approach to object-oriented programming 🔗
#️⃣ Façonnage de code
·
🔣 Science des Langages
⚖️ Un paradigme n’ayant pas survécu peut nous être utile, car il offre un regard différent sur le code. L’approche par la Loi de Minsky et Rozenshtein n’a pas été implémentée dans un langage dominant, pourtant la lecture de ce papier change notre regard sur l’Orienté-Objet.
📮 Selon Alan Kay, l’idée derrière l’objet est la communication de messages entre des entités encapsulées, les objets. L’approche par la Loi va plus loin en décrétant qu’il n’est pas de la responsabilité des objets de savoir à qui ils émettent des messages. Comme dans le système postal, chacun dépose son message auprès d’un intermédiaire, qui seul décide qui le recevra. Cet intermédiaire applique des règles : la Loi.
🚌 Cette approche a indirectement inspiré les ServiceBus modernes, voire les microservices. La lecture de ce papier nous fait réaliser la véritable nature de nos objets au quotidien.
SOURCE
Minsky, Naftaly H. and David Rozenshtein. “A law-based approach to object-oriented programming.” Conference on Object-Oriented Programming Systems, Languages, and Applications (1987). DOI:10.1145/38765.38851
📄 Lien public
DOIs:
10.1145/38765.38851
How do personality, team processes and task characteristics relate to job satisfaction and software quality ? 🔗
🧠 Psychologie
·
👌 Qualité logicielle
🤓 Si je vous dis “développeur”, avez-vous l’image d’un nerd introverti voire misanthrope en tête ? La recherche montre pourtant que les plus heureux au travail sont les plus agréables et consciencieux. Mieux : ceux produisant les logiciels les plus qualitatifs sont les extravertis.
💀 Vous pouvez cependant rester misanthropes, l’étude ne dit rien de cette option philosophique.
SOURCE
Acuña, Silvia Teresita, Marta Gómez and Natalia Juristo Juzgado. “How do personality, team processes and task characteristics relate to job satisfaction and software quality?” Inf. Softw. Technol. 51 (2009): 627-639.
DOIs:
10.1016/j.infsof.2008.08.006
On the Impact of Design Flaws on Software Defects 🔗
🦨 Code Smells
🦨 Les odeurs du code (ici nommées Design Flaws) sont corrélées positivement aux défauts des logiciels. Le plus fréquente des odeurs est la jalousie fonctionnelle (Feature Envy). Ces deux conclusions d’une équipe Suisse n’étonneront pas qui a l’habitude de lire des sources de projets legacy.
👀 La jalousie fonctionnelle désigne le fait, pour une classe, de faire plus appel aux attributs/getters d’autrui qu’à ses propres données. Elle augmente fortement le couplage et nuit à la lisibilité des classes. Elle est un signe d’une formation parcellaire ou insuffisante à l’orienté objet.
💪 Le remède ? Essayez de développer le jeu de la vie ou un bowling avec les règles Object Callisthenics, c’est radical.
SOURCE
M. D’Ambros, A. Bacchelli and M. Lanza, “On the Impact of Design Flaws on Software Defects,” 2010 10th International Conference on Quality Software, 2010, pp. 23-31, doi:10.1109/QSIC.2010.58.
DOIs:
10.1109/QSIC.2010.58
The Humble Programmer 🔗
#️⃣ Façonnage de code
·
👔 Avis d'expert
👴 Dijkstra est une personnalité du développement. Il est notre Confucius, largement cité, rarement lu. Un de ses plus célèbres papiers, The Humble Programmer raconte son histoire avec la programmation. Dans sa seconde partie, il disserte sur l’avenir de notre profession et sa condition de survie : atteindre la performance. Cela signifie que les développeurs ne doivent pas passer la majorité de leur temps à débugger, donc que les développeurs ne doivent plus mettre de bugs dans leurs programmes, tout simplement.
🐛 Comment atteint-on cette performance ? En créant des programmes intellectuellement maniables. Comment fait-on cela ? En remettant la célèbre citation de Dijkstra dans son contexte : “Tester peut être une manière efficace de trouver des bugs, mais jamais de prouver leur absence”.
🧪 Dijkstra parle ici des tests manuels après le développement. Il recommande plutôt de développer la preuve de validité et le programme main dans la main, car il s’agit de la seule manière de ne pas avoir de bugs. Un programme dont les tests sont l’ultime spécification n’a pas de bugs, seulement des tests manquants. Il suffit d’écrire ces tests pour ne jamais voir revenir ce “bug”.
♻️ Mieux, lorsque l’on a écrit une preuve de validité, il est possible d’itérer afin de trouver le programme valide le plus intellectuellement maniable. Le mot “refactoring” n’existe pas encore, mais le concept est posé. Alors, Dijkstra, un précurseur de TDD ?
SOURCE
Edsger W. Dijkstra, The Humble Programmer, ACM Turing Lecture 1972, EWD340, DOI:10.1145/355604.361591
📄 Lien public
DOIs:
10.1145/355604.361591
Direct and indirect connections between type of contract and software project outcome 🔗
🧑💼 Management
💵 L’utilisation de prestataires au forfait est plus risquée pour le projet que si ceux-ci sont en régie. C’est la conclusion d’une étude norvégienne portant sur 35 projets du secteur public. Le forfait a bien plus de chances de devenir problématique pour toute une liste de raisons, bien entendu cumulables :
👉 La sélection des prestataires favorise les moins chers, donc les plus optimistes et les moins expérimentés.
👉 Le management s’implique moins, car un forfait est psychologiquement ou juridiquement conçu comme du fire and forget.
👉 Il est improbable qu’un forfait soit itératif et livre fréquemment
👉 Le management contrôle moins la compétence du prestataire au fil de la prestation. Elle refuse d’évaluer le risque d’incompétence avant la livraison.
👨💼 Si la régie pose aussi ses problème, elle est moins risquée pour le projet que le forfait.
SOURCE
Magne Jørgensen, Parastoo Mohagheghi, Stein Grimstad, Direct and indirect connections between type of contract and software project outcome, International Journal of Project Management, Volume 35, Issue 8, 2017, Pages 1573-1586, ISSN 0263-7863, DOI:10.1016/j.ijproman.2017.09.003.
DOIs:
10.1016/j.ijproman.2017.09.003
Purposes, concepts, misfits, and a redesign of git 🔗
#️⃣ Façonnage de code
🙊 Git est un bon outil, mais le nombre d’appels à l’aide sur StackOverflow prouvent que son design est affreux. Deux chercheurs du MIT nous expliquent où le bât blesse à l’aide des techniques de design conceptuel.
🛑 Quiconque a pratiqué un peu connaît les défauts de git : difficile de changer de branche avec du travail en cours, de créer des variations locales sans les commiter, de comprendre l’état de tête détachée, etc. Pourquoi ? Car une régle fondamentale du design a été violée par git : la bijection concept/motif.
💭 Un concept est quelque chose que l’utilisateur doit comprendre pour utiliser un logiciel. Dans un bon design, chaque concept règle un problème, que l’on nomme son motif.
👉 Un concept sans motif est une complexité inutile.
👉 Un concept qui prétend régler plusieurs problèmes bâcle souvent les deux.
👉 Un problème qui n’est le motif d’aucun concept rend le logiciel incomplet.
👉 Un problème qui motive plusieurs concepts créé la confusion.
4️⃣ Git possède ces 4 catégories de défauts, analysés dans le papier. Il constitue une vraie leçon de design qui devrait être enseignée dans les écoles.
🌠 Les auteurs poursuivent en proposant à des utilisateur de tous niveaux de git l’essai de Gitless, un fork de Git respectant les canons du design conceptuel. Les résultats en matière de prise en main sont bien meilleurs.
SOURCE
Santiago Perez De Rosso and Daniel Jackson. 2016. Purposes, concepts, misfits, and a redesign of git. SIGPLAN Not. 51, 10 (October 2016), 292–310. DOI:10.1145/3022671.2984018
📄 Lien public
DOIs:
10.1145/2983990.2984018
The coupling effect: fact or fiction 🔗
🧪 Tests
🧪 En théorie des tests, l’effet de couplage (Coupling Effect) désigne l’hypothèse selon laquelle un jeu de tests ne laissant pas passer des fautes simple ne laissera que marginalement passer des fautes complexes. Enoncée en 1978, il faut attendre 1989 et une étude d’Offutt pour l’appuyer à l’aide de preuves expérimentales.
👾 En utilisant le principe des tests de mutation, l’auteur valide l’hypothèse sus-mentionnée. Il va même plus loin en montrant que l’hypothèse du Programmeur Compétent n’est qu’une version extrême de l’effet de couplage.
🃏 L’hypothèse du Programmeur Compétent énonce qu’un développeur produira en général des logiciels “presque corrects”. Personne n’écrit le code d’un système d’exploitation par erreur en voulant développer un compilateur. Autrement dit, un développeur tend à écrire des mutants de rang faible (ayant peu de différences) par rapport au programme visé. Un bon jeu de test cherche à attraper ces erreurs, donc n’a aucun intérêt à attraper les mutants de rangs supérieurs. Cela reviendrait à vérifier que notre compilateur n’est pas, par erreur, devenu un système d’exploitation, soit une situation hautement improbable.
SOURCE
A. Offutt. 1989. The coupling effect: fact or fiction. In Proceedings of the ACM SIGSOFT ‘89 third symposium on Software testing, analysis, and verification (TAV3). Association for Computing Machinery, New York, NY, USA, 131–140. DOI:/10.1145/75308.75324
DOIs:
10.1145/75308.75324
Experimental assessment of random testing for object-oriented software 🔗
🧪 Tests
🎲 Tester avec des valeurs aléatoire a-t-il un sens ? Sur un code implémentant un système de contrats (préconditions et postconditions), oui.
Un étude suisse a obtenu d’excellents résultats en effectuant des opérations aléatoires avec des valeurs aléatoires sur un code programmé par contrats. Cette méthode de test trouve un nombre très important de bugs dès les premières minutes, moyennant suffisamment de puissance de calcul pour essayer un nombre significatif de combinaisons.
🧪 Ces résultats n’ont pas été reproduits sur d’autres types de code, ceux remplaçant les contrats par un typage fort impitoyable, par exemple.
SOURCE
Ciupa, Ilinca & Leitner, Andreas & Oriol, Manuel & Meyer, Bertrand. (2007). Experimental assessment of random testing for object-oriented software. 84-94. DOI:10.1145/1273463.1273476.
DOIs:
10.1145/1273463.1273476
Is Design Dead ? 🔗
#️⃣ Façonnage de code
·
👔 Avis d'expert
·
♻️ Refactoring
·
🧮 Méthodes de développement
🤠 On reproche à eXtreme Programming d’être revenu à l’ancien temps du “Code&Fix” en rejetant la notion de planification du design. Martin Fowler rétorque qu’en effet, l’équipe qui ferait du cherry-picking dans les pratiques d’XP s’expose bien à un retour à l’ère des cowboy programmers. Dans un long plaidoyer, il explique que se libérer d’UML et de son cortège de diagrammes est absurde sans adhérer d’abord au coeur d’eXtreme Programming : 3 pratiques primant temporellement sur toutes les autres.
1️ Les Tests, sans lesquels tout le reste est impossible, car friable et invérifiable.
2️ L’Intégration Continue, qui permet de ne pas se marcher dessus à plusieurs. Elle nécessite les tests.
3️ Le Refactoring qui procède des tests et de l’intégration continue. Il est la clé permettant de diminuer suffisamment le coût du changement d’un système complexe afin qu’un design émerge en cours de route. Il permet de changer un aggrégat de solutions ad-hoc en design révélateur d’intentions, à comportement visible égal.
🆙 Ce n’est qu’une fois ces pratiques acquises qu’une équipe peut adhérer à d’autres pratiques d’eXtreme Programming.
SOURCE
Fowler, Martin. “Is design dead.” (2001).
35 years on: To what extent has software engineering design achieved its goals ? 🔗
💾 Histoire de l'informatique
·
👌 Qualité logicielle
🚀 En 1968 s’est tenue la conférence de l’OTAN sur l’ingénierie du logiciel. Une de ses tâches fut de définir le design de logiciels. Les participants ne sont pas partis d’une feuille blanche, mais ont d’abord rassemblé les définition du design dans les autres disciplines d’ingénierie. C’est d’ailleurs une des forces de ce papier : il est un des meilleurs résumés que je connaisse sur le design en général.
💣 Une fois les généralités passées, les participants ont essayé de sauver les meubles malgré les particularités du logiciel.
👉 Parce que le logiciel est en évolution permanente, son design et sa production sont indissociables. Le design de logiciels ne peut donc pas être fait totalement en amont. Hélas, 30 ans furent nécessaires pour en tirer les conclusions nécessaires et revenir au développement itératif et incrémental des années 60.
👉 Parce que le logiciel est intangible, il n’est pas posible de se bâtir une image mentale à partir des propriétés physico-chimiques ou géométriques du matériau travaillé. Il ne reste au designer que les besoins des utilisateurs pour se bâtir une intuition limitée de ce qui doit être fait.
👉 Parce qu’un logiciel est virtuel et que le développement est une discipline balbutiante, les métriques nécessaires à la mesure de sa qualité sont une terra incognita. Les designers perdent une source précieuse de feedback et doivent s’en remettre à l’intuition des développeurs (qualité transcendantale) ou à une satisfaction utilisateur qui arrive uniquement en fin de production.
🗿 Les participants à la conférence de Garmisch-Partenkirschen avaient toutes les cartes en main pour reconnaître l’ineptie de calquer le design de logiciels sur les autres disciplines d’ingénierie. Comme le souligne l’auteur, c’est l’orgueil voire l’idéologie qui interdit à l’époque de considérer les méthodes itératives, jugées “informelles et idiosyncratique” comme des méthodes d’ingénierie valable. Dans les années 60, la tradition n’était plus considérée comme une source de connaissance valable.
SOURCE
Simons, Christopher & Parmee, Ian & Coward, David. (2004). 35 years on: To what extent has software engineering design achieved its goals?. Software, IEE Proceedings -. 150. 337- 350. DOI:10.1049/ip-sen:20031198
DOIs:
10.1049/ip-sen:20031198
On Understanding Types, Data Abstraction, and Polymorphism 🔗
💾 Histoire de l'informatique
·
🔣 Science des Langages
🛡️ “Un type peut être vu comme une armure protégeant la représentation non-typée sous-jacente d’usages arbitraires ou illicites.”. Nous utilisons tous les jours des types, comme s’ils étaient naturels et intuitifs. Entiers, booléens, ou objets plus gros.
🦍 Nous avons appris à nous en servir par imitation, c’est à dire partiellement. Pour les maîtriser et en débloquer tout le potentiel, il est nécessaire de les approfondir.
📕 Luca Cardelli et Peter Wagner ont rédigé en 1985 un papier dense et exigeant, dont la lecture est néanmoins bénéfique à tout développeur voulant apprendre ce que renferment des notions comme les types, l’abstraction ou le polymorphisme.
🧮 Si vous ignorez ce qu’est le polymorphisme paramétrique ou ad-hoc, ou ce qu’est un treillis d’idéaux, sans pour autant aborder une thèse de mathématiques, ce papier est fait pour vous.
SOURCE
Luca Cardelli and Peter Wegner. 1985. On understanding types, data abstraction, and polymorphism. ACM Comput. Surv. 17, 4 (Dec. 1985), 471–523. DOI:10.1145/6041.6042
DOIs:
10.1145/6041.6042
What Does 'Product Quality' Really Mean ? 🔗
👌 Qualité logicielle
💎 Que signifie la qualité ? Le mot a 5 définitions communes, complémentaires mais contradictoires. La difficulté dans tout projet et d’adopter une définition limitée, locale et équilibrée de celle-ci afin de chasser l’ambiguïté et les conflits. Le papier de David Garvin que je vous livre fait partie des plus importants de l’histoire de l’industrie, rien de moins.
🎨 Si vous êtes un romantique, un philosophe ou un artiste, votre vision de la qualité sera probablement transcendante. Cela signifie que la qualité sera pour vous indéfinissable, reconnaissable uniquement par l’expérience.
💹 Si vous êtes un économiste, la qualité sera orientée produit, c’est à dire vue comme la quantité d’un attribut désirable possédé par le produit.
💼 Si vous appartenez au côté commercial de la force, vous aurez une vision orientée utilisateur de la qualité. La qualité d’un produit est un plébiscite. Est qualitatif ce qui se vend, ce que préfère le consommateur.
👷 Chez les ingénieurs, l’approche orientée production est fréquente : un produit de qualité répond parfaitement aux spécifications du premier coup, point final.
💰 Enfin, pour un gestionnaire, la qualité est orientée valeur, c’est à dire qu’un produit de qualité fournit la performance et la conformité à un prix acceptable.
🧠 Qui a raison ? Le compromis raisonnable, qui ne sera jamais idéal pour aucune de ces catégories de personnes, et qui varie selon le produit à réaliser. Garvin recommande de définir la qualité précisément dans 8 dimensions pour chaque produit : performance, fonctionnalités, fiabilité, conformité, durabilité, maintenabilité, esthétique et qualité perçue, afin d’éviter les querelles entre les différents métiers à l’oeuvre.
SOURCE
Garvin, David A. “What Does ‘Product Quality’ Really Mean?” MIT Sloan Management Review 26, no. 1 (fall 1984).
Reversing Entropy in a Software Development Project : Technical Debt and AntiPatterns 🔗
🎓 Thèse
·
🦨 Code Smells
·
🧩 Design (Anti-)Patterns
·
#️⃣ Façonnage de code
💣 Plus un logiciel est complexe ou mal fichu, puis il a de prise au réel et plus il vieillit vite. C’est l’entropie du logiciel. Existe-t-il une crème anti-âge pour le code ? Non, hélas, mais des techniques permettent de ralentir, voire d’inverser ce phénomène.
♻️ Le refactoring permet de regénérer le code, mais il doit être ciblé pour être efficient. Refaire en permanence tout le design n’a aucun sens.
🏚️ La cible se nomme antipatterns. Ils sont des problèmes de design ou d’architecture connus et identifiables.
🦨 Comment ? En identifiant des odeurs que la plupart laissent dans le code.
🔧 Comment ? Partiellement grâce à des outils présentés dans la thèse, capable de repérer certaines odeurs, partiellement avec l’expérience et l’oeil de l’artisan.
⚠️ Toutes les odeurs ne ménent pas à des antipatterns et tous les antipatterns n’ont pas d’odeur, mais c’est mieux que rien.
SOURCE
Ramirez Lahti, Jacinto, Reversing Entropy in a Software Development Project : Technical Debt and AntiPatterns, 2020, University of Helsinki, Faculty of Science, Tietojenkäsittelytieteen osasto
A View of 20th and 21st Century Software Engineering 🔗
🧠 Si on analysait l’histoire du développement avec la méthode hégelienne ? Barry Boehm a essayé en 2006 et les leçons qu’il en tire sont intéressantes.
💽 Thése des années 1950 : l’ingénierie du logiciel est similaire à l’ingénierié hardware. L’humain est bien moins cher à l’heure que les ordinateurs, le développeur doit agir en ayant ce principe économique en tête : suroptimisation, vérification pointilleuse des programmes avant leur livraison. Le rapport nécessaire aux sciences, l’absurdité de la gestion de projet séquentielle et la rigueur sont les enseignements de cette période.
🪛 Antithèse des années 1960 : Code and fix (que Boehm appelle, improprement à mon avis “Crafting”). Les développeurs se sont rendus compte que le logiciel est infiniment plus facile à modifier que le matériel. De plus le coût des ordinateurs baisse drastiquement. L’idée d’un code en état de maintenance permanent fait son chemin, précurseure de l’agilité moderne. On commence à parler d’itérations par opposition aux méthodes linéaires.
🧱 Synthèse des années 70 et antithèse : formalisme. Face aux plats de spaghetti souvent hérités de la décennie précédente, mais également afin de ne pas revenir aux processus guindés des années 50, une vague méthodologique a déferlé dans la gestion de projet, donnant Waterfall et dans le design donnant la programmation structurée, le concept de couplage et les balbutiements de la qualité logicielle en général. Hélas, l’esprit Top-Down et réductionniste est venu gâcher la fête en considérant un logiciels comme un ensemble de silos.
♾️ Synthèse des années 80 : scalabilité. C’est l’époque des tests automatisés, de l’orienté objet, de l’architecture, des IDE … La productivité des développeurs s’accroît d’un facteur 10. C’est la fin des obstacles accidentels à la vélocité des développeurs. Hélas le mouvement est allé trop loin, croyant se passer des développeurs, menant au ratage du WYSIWYG ou au mirage du Model-Based Software Enginering.
♻️ Antithèse des années 90 : recyclage. Les développeurs sont incontournables, mais lents, alors pour accélérer la livraison, il faut réutiliser au maximum. Cela est permis par le développement de l’orienté objet et de l’architecture. Il faut faire générique, trop parfois, quitte à créer d’infects frameworks d’entreprise. C’est aussi l’époque de la défiance envers la planification, jugée comme retardant le time-to-market, seule manière de savoir si le produit colle au besoin. C’est aussi l’âge d’Internet et de l’Open Source.
📝 Je vous laisse découvrir la suite, ainsi que les prédictions de Boehm dans le papier lui-même !
SOURCE
Barry Boehm. 2006. A view of 20th and 21st century software engineering. In Proceedings of the 28th international conference on Software engineering (ICSE ‘06). Association for Computing Machinery, New York, NY, USA, 12–29. DOI:10.1145/1134285.1134288
DOIs:
10.1145/1134285.1134288
Static analysis tools as early indicators of pre-release defect density 🔗
🧪 Tests
·
🦨 Code Smells
·
👌 Qualité logicielle
🐛 Les outils d’analyse statique de code sont un bon indicateur de la densité de fautes dans un code. Leurs résultats sont en effet fortement corrélés aux défauts trouvés lors de tests manuels. Si ces outils ne trouvent pas tous les bugs, ils ont de grandes chances de détecter les plus gros nids dans un ensemble de composants.
SOURCE
N. Nagappan and T. Ball, “Static analysis tools as early indicators of pre-release defect density,” Proceedings. 27th International Conference on Software Engineering, 2005. ICSE 2005., St. Louis, MO, USA, 2005, pp. 580-586, doi: 10.1109/ICSE.2005.1553604.
DOIs:
10.1109/ICSE.2005.1553604
Toward understanding the rhetoric of small source code changes 🔗
👌 Qualité logicielle
·
🥼 Épistémologie
🤫 Des chercheurs ont étudié statistiquement les changements d’une seule ligne de code, bref les “ça va, c’est une petite modification” que nous connaissons si bien. Accrochez-vous les chiffres sont contre-intuitifs.
♻️ 95% du code sera édité au moins une fois tout au long du projet. Aucun code ne doit être réalisé avec pour condition de ne jamais changer.
📝 95% des changements au cours d’un projet font moins de 50 lignes. Les petits changements sont plus fréquents que vous ne l’envisagez lors de la première release.
💣 Un changement d’une seule ligne n’a que 4% de chances d’introduire un défaut. C’est donc la répétition qui fait le poison en la matière. Le chiffre monte à 40% si le changement vient résoudre un bug existant. Le Defect Testing est donc bien votre ami.
✂️ Il n’y a aucune preuve qu’une suppression de moins de 10 lignes de code puisse engendrer un bug. La leçon la plus importante est donc de prendre les études statistiques avec des pincettes.
SOURCE
R. Purushothaman and D. E. Perry, “Toward understanding the rhetoric of small source code changes,” in IEEE Transactions on Software Engineering, vol. 31, no. 6, pp. 511-526, June 2005, doi:10.1109/TSE.2005.74.
DOIs:
10.1109/TSE.2005.74
Managing the development of large software systems 🔗
💾 Histoire de l'informatique
·
🧮 Méthodes de développement
🤖 A l’origine de la méthode Waterfall et de ses descendants, dont le célèbre cycle en V, on trouve un homme : Winston Walker Royce. Peu après la conférence de Garmisch-Partenkirchen de 1968, il produisit une méthode révolutionnaire afin “d’utiliser au mieux les ressources en programmeurs”. Le vocabulaire annonce la couleur : le développeur doit se tayloriser.
🔃 Son idée repose sur l’ajout d’étapes précédant la boucle analyse/programmation, qui suffit aux petits projets. Il s’agit des phases de spécification, analyse, architecture et autres analyses plus ou moins détaillées. Rendons cependant justice à Royce, qui avait bien compris que les étapes de programmation et de tests allaient lever de nombreux problèmes, nécessitant de remonter de nombreuses étapes en arrière dans les phases de spécification. Son erreur a été de sous-estimer la fréquence de ces retours : il pensait que la majorité des problèmes seraient détectés dans l’étape suivant immédiatement celle qui les a causés.
💣 La seconde erreur de Royce est de croire en la linéarité de la relation entre la taille d’un problème et l’importance des changement qu’il occasionnera. Tout son argumentaire repose sur ce mythe : si un problème est petit, il n’occasionnera que de petits changements et la majorité du travail réalisé avant sa détection sera conservé. Il est donc rentable de tout spécifier par raffinements successifs jusqu’à rendre la tâche du programmeur triviale. Avec le recul, nous savons qu’un petit problème d’implémentation peut invalider des centaines d’heures de conception sur plusieurs étapes.
📚 La troisième erreur de Royce est de croire que la documentation remplace la collaboration. Il prône une médiation universelle des différents métiers à l’oeuvre sur un logiciel par le document papier. Il y voit deux avantages : trouver les responsables des erreurs et spécialiser les tâches. Si un acteur rédige une documentation en amont, il est possible de diviser le travail en aval grâce à une photocopieuse. Chacun a son exemplaire de documentation, son silo et ses tâches spécialisées à effectuer. Il illustre en évoquant les tests “réalisables par des acteurs moins coûteux que les programmeurs”. De plus, vu que chacun est forcé de décrire son avancement sur une documentation, il est facile de remonter à la source, donc de blâmer.
🧠 Il est difficile de jeter la pierre à Royce, car les études venues invalider ses préjugés n’étaient pas sorties. Il aurait cependant pu faire preuve de plus de prudence avant d’appliquer au développement de logiciels tous les lieux communs de son époque. Le leçon, pour nous, est justement là. Appliquons-nous benoîtement la dernière méthode dans l’air du temps, ou bien avons-nous des preuves empiriques ?
SOURCE
Royce, Winston. “Managing the development of large software systems: concepts and techniques.” International Conference on Software Engineering (1987).
📄 Lien public
Traits : Composable Units of Behaviour 🔗
🔣 Science des Langages
🏹 L’héritage simple est trop limité. L’héritage multiple est trop dangereux. Les mixins sont maladroits. Si l’avenir était aux Traits ? Un trait est un ensemble de méthodes pures (au sens où elles ne mutent pas d’attributs) servant de blocs préfabriqués pour constituer des classes.
🧩 Un Trait peut spécifier des corps de méthodes, tant qu’elles n’accèdent pas aux données. Les Traits peuvent hériter et donc exiger la présence d’autres traits dans la classe. Un Trait n’a pas à être complet, il peut laisser certaines méthodes sans corps, afin que les classes les définissent.
📝 Plusieurs implémentations sont possibles, certains langages comme PHP adoptent un mot clé séparé, d’autres comme C# préfèrent simplement autoriser les méthodes dans les interfaces.
🧠 Le papier a en outre une définition originale et profonde de ce qu’est une classe, j’en recommande la lecture pour cette raison.
SOURCE
Schärli, Nathanael & Ducasse, Stéphane & Nierstrasz, Oscar & Black, Andrew. (2003). Traits: Composable Units of Behaviour. Proceedings ECOOP 2003. 2743. 248-274. DOI:10.1007/978-3-540-45070-2_12
DOIs:
10.1007/978-3-540-45070-2_12
What is object-oriented programming? 🔗
💾 Histoire de l'informatique
·
🔣 Science des Langages
💡 L’orienté objet, c’est l’abstraction plus l’héritage. L’abstraction, c’est l’encapsulation, plus le typage. Voici la définition, adossée à un argumentaire historique, que donne Bjarne Stroustrup de la POO.
🌡️ Il regrette que “POO” ait été trop souvent un buzzword, collé aux langages “cool” du moment comme Ada. Au risque d’un parti-pris pour faire entrer son propre langage, C++, dans la catégorie orienté-objet, Stroustrup vient combler ce manque de définition.
📜 Le papier présente également un intérêt historique, car Stroustrup y retrace la filiation de la POO dans l’histoire des langages.
SOURCE
Stroustrup, Bjarne. “What is object-oriented programming?” IEEE Software 5 (1988): 10-20. DOI:10.1109/52.2020
DOIs:
10.1109/52.2020
On the notion of inheritance 🔗
🔣 Science des Langages
🎨 L’héritage, comme toute chose, possède une essence et des accidents. Son essence est d’exprimer un lien conceptuel entre la classe et ses ancêtres. Ses accidents sont tous les usages plus ou moins défendables qui ont été inventés par les développeurs. Ainsi l’héritage peut servir à créer des modules, réutiliser du code, mêler les comportement de plusieurs classes, etc.
🤔 Est-ce légitime ? L’auteur ne donne son avis que dans de rares cas. Cependant, il conclut que l’héritage signifie de facto bien plus que le simple lien de spécialisation conceptuelle. Lire un code en partant du principe que tout héritage est à but conceptuel est un pari dangereux.
📜 Le papier ne s’arrête pas là : il est un traité sur l’héritage, un état de l’art détaillant les subtilités de ce concept. Sa lecture est une mine d’or pour le développeur qui souhaite approfondir l’orienté-objet.
SOURCE
Taivalsaari, Antero. “On the notion of inheritance.” ACM Comput. Surv. 28 (1996): 438-479.
DOIs:
10.1145/243439.243441
Using Customer Acceptance Tests to Drive Agile Software Development 🔗
🧮 Méthodes de développement
·
🧪 Tests
·
💾 Histoire de l'informatique
🧪 Connaissez-vous Customer Test Driven Development (CTDD) ? Probablement pas. Complètement éclipsée par Dan North et la célèbre méthode BDD, CTDD n’en reste pas moins la première méthode Story TDD (STDD) connue.
🔬 TDD, lorsqu’il est mal compris, mène à des aberrations, comme les projets testés 100% au niveau unitaire. Le terme d’origine est flou, alors Lisa Crispin remet l’église au centre du village : les tests doivent vérifier les comportements visibles, non les arcanes internes des programmes.
📖 Mieux : si les tests sont les spécifications du projet, le cahier des charges n’est qu’un doublon pataud à côté de tests automatisés de haut niveau, seule source de vérité évoluant avec le projet en permanence.
🗣️ Hélas Lisa Crispin n’est pas allée assez loin. Il manquait une révolution dans notre vocabulaire pour assoir les clients aux côtés des développeurs lors de la conception des logiciels. C’est chose faite avec l’article de Dan North publié un an plus tard : Behavior Driven Development.
📜 A cheval entre la note méthodologique et le billet de blog, j’ai longtemps hésité à passer le papier de Lisa Crispin sur cette veille scientifique. Sa valeur historique penche en sa faveur. Logiquement, ce résumé en appelle d’autres. En premier lieu, un résumé de l’article de Dan North sus-mentioné.
SOURCE
Crispin Lisa, Using Customer Acceptance Tests to Drive Agile Software Development, 2005, Methods And Tools
📄 Lien public
The most common causes and effects of technical debt: first results from a global family of industrial surveys 🔗
🧑💼 Management
·
👌 Qualité logicielle
🏃♂️ Quelles sont les causes et les effets de la “dette technique”* sur les projets ? Les causes sont connues : les deadlines et les problèmes de planification en majorité. Les autres causes sont minoritaires ou illusoires.
⏱️ Les conséquences ? Une faible qualité du code, du temps passé à refaire, donc des retards de plus en plus importants menant à toujours plus de raccourcis douteux.
🇧🇷 Les chercheurs reproduisent indépendamment dans un pays différent les travaux de Yli-Huumo et al. déjà mentionnés ici (DOI:10.1007/978-3-319-19593-3_1)
* La dette technique est à l’origine un acte conscient de prise de raccourci en échange d’un remboursement au plus vite.
SOURCE
Rios, Nicolli & Spínola, Rodrigo & Mendonça, Manoel & Seaman, Carolyn. (2018). The most common causes and effects of technical debt: first results from a global family of industrial surveys. 1-10. DOI:10.1145/3239235.3268917
DOIs:
10.1145/3239235.3268917
On the effectiveness of the test-first approach to programming 🔗
🧪 Tests
·
🧑💼 Management
🧪 Les approches Test-First (TDD, TCR, …) découplent la qualité du logiciel de la compétence de l’équipe de développement. Contre-intuitivement, ces approches n’augmentent pas la qualité d’un logiciel, mais boostent la productivité de l’équipe.
🥇 D’excellents développeurs n’ont pas besoin de Test-First pour produire un excellent code. Un projet sans Test-First peut fonctionner, mais est enchaîné à des développeurs de haut niveau, ce qui peut être un problème au niveau RH. Adopter une méthode Test-First permet d’obtenir une qualité de code satisfaisante quelque soit le niveau de l’équipe.
💹 En augmentant la compréhension et la concentration des développeurs, Test-First augmente leur productivité quelque soit leur niveau. Cependant, elle augmente bien plus la productivité des développeurs les plus expérimentés que celle des novices.
♻️ Le papier n’évoque pas le principal intérêt de Test-First : la capacité à refactorer à l’envi, ce qui empêche la diminution trop rapide de la vélocité de l’équipe et donc augmente sa productivité à moyen et long-terme.
SOURCE
H. Erdogmus, M. Morisio and M. Torchiano, “On the effectiveness of the test-first approach to programming,” in IEEE Transactions on Software Engineering, vol. 31, no. 3, pp. 226-237, March 2005, doi: 10.1109/TSE.2005.37
DOIs:
10.1109/TSE.2005.37
An Experimental Comparison of Four Unit Test Criteria: Mutation, Edge-Pair, All-Uses and Prime Path Coverage 🔗
🧪 Tests
🎯 Adopter un critère quantitatif pour les tests n’est pas une bonne idée. Les différentes formes de Coverage ne garantissent en rien la qualité des tests censés couvrir le code. Aucune des méthodes de calcul de Coverage ne fait mieux qu’une autre.
👾 Le score de mutation, en revanche, est un indicateur plus sérieux. Il est capable de repérer beaucoup de bugs simples et d’erreurs d’inattention. Il échoue cependant face aux bugs plus vicieux.
SOURCE
N. Li, U. Praphamontripong and J. Offutt, “An Experimental Comparison of Four Unit Test Criteria: Mutation, Edge-Pair, All-Uses and Prime Path Coverage,” 2009 International Conference on Software Testing, Verification, and Validation Workshops, 2009, pp. 220-229, doi: 10.1109/ICSTW.2009.30.
DOIs:
10.1109/ICSTW.2009.30
Effectiveness of Test-Driven Development and Continuous Integration: A Case Study 🔗
🧪 Tests
·
🧮 Méthodes de développement
🇳🇱 D’après une revue de littérature néerlandaise, TDD augmenterait modérément la qualité du code, mais aucune conclusion ne peut être tirée quant à la productivité des développeurs.
🙄 On peut regretter que cette revue de littérature ne vérifie pas si les études citées comparent TDD à Test-Last. Il est en effet malhonête de comparer TDD à l’absence de tests.
SOURCE
C. Amrit and Y. Meijberg, “Effectiveness of Test-Driven Development and Continuous Integration: A Case Study” in IT Professional, vol. 20, no. 1, pp. 27-35, January/February 2018, doi: 10.1109/MITP.2018.014121554
DOIs:
10.1109/MITP.2018.014121554
Is mutation an appropriate tool for testing experiments ? 🔗
🥼 Épistémologie
🔬 Contrairement à l’aviation ou à la pharmacologie, nous ne publions pas nos échecs. C’est un grand manque lorsqu’il s’agit de valider des hypothèses de recherche. Aussi les chercheurs remplacent de vrais bugs par des faux lorsqu’ils étudient les moyens de les combattre. Deux outils sont principalement utilisés : la mutation et l’introduction manuelle.
👾 La mutation consiste à créer des mutants, des copies du code ayant subi un changement préprogrammé (inverser une condition, incrémenter une constante, supprimer une ligne, etc.)
🧑💻 L’introduction manuelle emploie un développeur expérimenté, payé pour introduire des bugs en amont de la recherche. Job de rêve s’il en est.
✔️ La mutation et l’introduction manuelle sont-ils des substituts légitimes aux vrais bugs ? Une équipe canadienne a vérifié. Les mutants obtiennent une bonne corrélation avec les vrais bugs, à condition que les opérateurs de mutation choisis soient correctement sélectionnés. L’introduction manuelle tend à introduire d’énormes biais. L’équipe recommande de toujours faire répliquer les études de basant sur cette seconde technique par d’autres chercheurs. Ce qui suppose de documenter le processus d’introduction des bugs.
SOURCE
J. H. Andrews, L. C. Briand, and Y. Labiche. 2005. Is mutation an appropriate tool for testing experiments? In Proceedings of the 27th international conference on Software engineering (ICSE ‘05). Association for Computing Machinery, New York, NY, USA, 402–411. DOI:10.1145/1062455.1062530
DOIs:
10.1145/1062455.1062530
Representing concerns in source code 🔗
#️⃣ Façonnage de code
·
🎓 Thèse
🔍 Pierre Boutang considérait la politique comme souci. Martin Robillard, lui, fait de même avec le code. Lorsque nous voulons l’éditer, il nous faut d’abord savoir quelles parties seront sous notre scalpel. Ce que nous recherchons alors, à coup de lecture de tests pour les plus chanceux ou de rétro-ingénierie pour les plus audacieux, ce sont des soucis (concerns en V.O).
❌ Chaque souci est un aspect du problème global résolu par le projet dans son ensemble. Hélas, il arrive fréquemment qu’un même souci soit adressé par plusieurs parties du code, on parle alors de “scattered concern”, un souci éparpillé. L’inverse survient quand un même code adresse plusieurs souci à la fois, on parle de “tangled concerns”, de soucis enchevêtrés.
✔️ Les canons du design conceptuel nous enseignent qu’un faut une bijection concept-problème pour faire un bon logiciel. Martin Robillard affirme qu’il faut également une bijection souci-module. Ces deux bijections sont des généralisations à des échelles différentes du plus grand principe de l’orienté-objet : Single Responsibility Principle (SRP).
SOURCE
Robillard, Martin & Murphy, Gail. (2007). Representing concerns in source code. ACM Trans. Softw. Eng. Methodol.. 16. 10.1145/1189748.1189751.
DOIs:
10.1145/1189748.1189751
Aim, Fire 🔗
🧮 Méthodes de développement
·
#️⃣ Façonnage de code
·
💾 Histoire de l'informatique
🤯 Je m’attaque à un monument : ni plus ni moins que l’article fondateur de TDD. Aim, Fire est un plaidoyer en faveur des approches Test-First. Kent Beck chasse un homme de paille fréquent : TDD n’est pas une méthode de test, mais une méthode de design, de réflexion et d’analyse.
🗿 Avec TDD, le développeur entre en dialogue avec le code. TDD ne dit pas quels tests effectuer, mais comment avancer sur un logiciel tel un sculpteur : en entrant en résonnance avec la matière que nous travaillons pour la tailler par petits incréments.
🗺️ A l’inverse, une méthode de test est là pour convertir des exigences en plan de test. TDD n’est pas une méthode de test, mais bien une pratique complémentaire à une méthode de test.
SOURCE
K. Beck, “Aim, fire” in IEEE Software, vol. 18, no. 5, pp. 87-89, Sept.-Oct. 2001, doi: 10.1109/52.951502
📄 Lien public
DOIs:
10.1109/52.951502
A Literature Review on Story Test Driven Development 🔗
🧪 Tests
🗊 Les méthodes de Story TDD comme BDD ont été analysées par plusieurs chercheurs. Deux canadiens en ont fait une revue de littérature. On y apprend que la méthode fonctionne, mais que les projets d’UI et les gros projets s’y adaptent très mal. L’outillage est encore très rudimentaire ou trop lourd.
💵 Cependant, la méthode parvient à créer des tests de non-régression qualitatifs et peu couteux, puisqu’ils sont réalisés en même temps que le recueil du besoin. Ce dernier est d’ailleurs facilité par le dialogue avec le code, qui permet de repérer les ambiguités et contradictions très tôt, contrairement aux spécifications papier.
🗓️ Les développeurs se sentent plus sûrs de leurs estimations, le projet est globalement plus à l’heure et respecte mieux les coûts. La communication entre parties prenantes est améliorée. Cependant l’adoption n’est pas aisée car elle implique tout le monde.
🔧 Le coût de maintenance de tels tests fait débat et peu de papiers l’ont étudié sérieusement.
SOURCE
Park, S., Maurer, F. (2010). A Literature Review on Story Test Driven Development. In: Sillitti, A., Martin, A., Wang, X., Whitworth, E. (eds) Agile Processes in Software Engineering and Extreme Programming. XP 2010. Lecture Notes in Business Information Processing, vol 48. Springer, Berlin, Heidelberg. DOI:10.1007/978-3-642-13054-0_20
DOIs:
10.1007/978-3-642-13054-0_20
Modularizing design patterns with aspects: a quantitative study 🔗
🧩 Design (Anti-)Patterns
·
🔣 Science des Langages
🆙 La programmation orientée aspect (AOP) est une tentative d’augmenter la POO comme cette dernière a augmenté l’abstraction de données. Peut-on remplacer avantageusement les design patterns du Gang of Four par des équivalents “aspectisés” ? Oui, mais l’avantage n’est pas net.
🙄 AOP obscurcit le code, il faut donc un bénéfice certain pour en justifier l’usage. Tous les design patterns aspectisés n’entrent pas dans ce critère. Peu gagnent en réutilisabilité par rapport à la version originale, seuls la moitié présentent une meilleure répartition des responsabilités et certains se retrouvent plus complexes voire plus couplés.
❔ Les quelques patterns pour lesquels AOP présente un bénéfice justifient-ils l’introduction d’un nouveau pradigme dans le code ?
SOURCE
Garcia, Alessandro F., Cláudio Sant’Anna, Eduardo Figueiredo, Uirá Kulesza, Carlos J. P. Lucena and Arndt von Staa. “Modularizing design patterns with aspects: a quantitative study.” LNCS Trans. Aspect Oriented Softw. Dev. 1 (2005): 36-74. DOI:10.1145/1052898.1052899
DOIs:
10.1145/1052898.1052899
Exceptions and aspects: the devil is in the details 🔗
🔣 Science des Langages
💣 La programmation orientée aspect (AOP) peut-elle simplifier la gestion des exceptions ? Oui mais uniquement dans les cas triviaux. Les cas complexes posent problème. C’est logique : AOP répond à la problématique des soucis transversaux (crosscutting concerns). Les exceptions n’en sont que rarement.
❔ Les rares cas où AOP serait utile pour gérer des exceptions justifient-ils un changement de paradigme connu pour assombrir le code ?
SOURCE
Filho, Fernando Castor, Nelio Alessandro Azevedo Cacho, Eduardo Figueiredo, Raquel Maranhão, Alessandro F. Garcia and Cecília M. F. Rubira. “Exceptions and aspects: the devil is in the details.” SIGSOFT ‘06/FSE-14 (2006). DOI:10.1145/1181775.1181794
DOIs:
10.1145/1181775.1181794
On the Impact of Aspectual Decompositions on Design Stability: An Empirical Study 🔗
🔣 Science des Langages
🪢 La programmation orientée aspect (AOP) promet de stabiliser le design lors de changements touchant les fonctions transversales d’un logiciel (crosscutting concerns). C’est même son acte de naissance, mais ces promesses sont-elles tenues ? Oui, mais au prix d’un couplage plus fort entre ces fonctions transversales et des modules n’ayant souvent rien à voir avec la modification effectuée.
⚠️ Le papier a une grosse limite : c’est une étude de cas sur un projet unique, dont la version orientée objet a été développée pour l’étude.
SOURCE
Greenwood, Phil & Bartolomei, Thiago & Figueiredo, Eduardo & Dosea, Marcos & Garcia, Alessandro & Cacho, Nélio & Sant’Anna, Claudio & Soares, Sergio & Borba, Paulo & Kulesza, Uirá & Rashid, Awais. (2007). On the Impact of Aspectual Decompositions on Design Stability: An Empirical Study. 176-200. DOI:10.1007/978-3-540-73589-2_9
DOIs:
10.1007/978-3-540-73589-2_9
Aspect-Oriented Programming 🔗
#️⃣ Façonnage de code
🔏 Les logs, le monitoring ou la sécurité ne sont pas de la responsabilité d’une seule partie du code. Ce sont des responsabilités de l’ensemble du code. Or, SRP et DRY, principes fondamentaux du design, nous interdisent de surcharger chaque classe pour prendre en compte tous ces soucis. Ils sont appelés crosscutting concerns ou soucis transversaux en français.
📦 A l’aube des années 2000, la complexité croissante des logiciels a descillé les yeux des développeurs sur ces problèmes. Plusieurs tentatives ont été faites. L’une d’entre-elles, Aspect-Oriented Programming, postule qu’il manque une couche d’abstraction entre les classes et les modules : les composants.
🪡 Ces composants, exprimés à l’aide d’une syntaxe propre, tissent (weaving) les classes et les agencent afin de répondre aux soucis transversaux sans violer SRP.
🌫️ AOP se voyait comme l’itération suivante de l’orienté-objet. Avec 20 ans de recul AOP a été très peu adopté, principalement à cause de l’obscurcissement du code qu’il provoque. Les développeurs sont difficilement capables de prédire le fonctionnement d’un programme à cause du tissage qui fait un usage massif de réflexion. Les IDE sont souvent aussi perdus, et incapables d’assister le refactoring d’un tel code.
💉 Cependant, on doit à AOP un vocabulaire (aspect, crosscutting-concern, etc.) et il a ouvert la voie à l’injection de dépendances moderne, qui offre un moyen plus lisible de gérer les mêmes problèmatiques.
SOURCE
Lopes, Cristina & Kiczales, Gregor & Lamping, John & Mendhekar, Anurag & Maeda, Chris & Loingtier, Jean-marc & Irwin, John. (1999). Aspect-Oriented Programming. ACM Computing Surveys. 28. DOI:10.1145/242224.242420
DOIs:
10.1145/242224.242420
No Silver Bullet — Essence and Accidents of Software Engineering 🔗
💾 Histoire de l'informatique
·
📜 Lois du développement
🪄 Technologies miracles. Magiciels. No-Code. LinkedIn est farci de charlatans promettant de diviser par 10 le temps de développement, donc le coût de ces maroufles de développeurs. Pourtant Fred Brooks a clot le débat il y a 45 ans.
🏛️ S’inscrivant dans la tradition aristotélicienne, il distingue l’essence du développement et les accidents.
😶🌫️ L’essence de la profession de développeur consiste à concevoir les structures conceptuelles abstraites des logiciels. Osherove dit que nous bâtissons d’abord des châteaux de vent. Il s’agit de comprendre les besoins de nos clients et d’en assurer la cohérence. Cette partie est très proche du knowledge management.
🏚️ Les accidents sont tout le reste : contraintes matérielles, langages peu commodes, gestion de projet datée, IDE rudimentaires, etc. Avant les années 80, la gros de l’effort de développement était perdu par ces accidents. Pour Brooks, ce n’est plus le cas à son époque (1987). Je pourrais troller sur C ou Javascript, mais ce n’est pas le sujet.
⚠️ Le seul moyen de gagner en productivité d’un facteur 10 ou plus est donc de gagner du temps sur l’essence de notre profession. C’est bien moins simple que d’écarter un à un les obstacles accidentels comme nous l’avons fait depuis les années 50. Brooks affirme qu’il n’existe aucune technique ou méthode permettant cela à l’échelle de la profession. Il était modeste et affirmait “dans les 10 ans”. 45 ans après, le papier n’a pas pris une ride.
🐱💻 Restent quatre “hacks” pour contourner cette loi empirique : acheter un logiciel sur étagère, utiliser des techniques de prototypage, adopter une approche incrémentale et recruter un développeur d’exception. Rien de tout cela ne suffit, mais mis ensembles ces hacks permettent d’atteindre une grande vélocité.
🚩 Ce papier doit être lu par tout développeur, au cours de sa formation ou ensuite. Il fait partie de notre histoire et de nos lois.
SOURCE
Brooks, Jr, Frederick. (1987). No Silver Bullet Essence and Accidents of Software Engineering. IEEE Computer. 20. 10-19. DOI:10.1109/MC.1987.1663532.
📄 Lien public
DOIs:
10.1109/MC.1987.1663532
Software Quality and Agile Methods 🔗
🧮 Méthodes de développement
·
👌 Qualité logicielle
🔍 L’agilité offre d’excellentes garanties en matière d’assurance qualité, mais elle ne s’appuie pas assez sur les techniques de QA statiques. Ces dernières sont basées sur l’analyse du code et des documents projet par les parties-prenantes, sans exécution de tests automatisés ou manuels.
⚠️ Le risque est d’avoir un projet satisfaisant pour l’utilisateur, mais possédant une faible qualité de production, donc peu maintenable ou reprenable dans le temps, sans parler de sécurité ou de compatibilité à l’avenir.
🤝 Cependant, ces problèmes sont largement atténués par des pratiques connexes à l’agilité mais hélas absentes de certains frameworks omniprésents dans l’industrie : le pair programming et l’interaction directe et sans proxy entre les développeurs et les utilisateurs. Encore un point pour eXtreme Programming ?
❓ Le papier ne conclut cependant pas à la supériorité de waterfall ou de l’agilité en matière de QA, car leurs champs d’application ne se rencontrent pas vraiment.
SOURCE
Huo, Ming & Verner, June & Zhu, Liming & Ali Babar, Muhammad. (2004). Software Quality and Agile Methods. Computer Software and Applications Conference, Annual International. 1. 520-525. DOI:10.1109/CMPSAC.2004.1342889
DOIs:
10.1109/CMPSAC.2004.1342889
A structured experiment of test-driven development 🔗
🧪 Tests
🍁 Une équipe canadienne a testé deux hypothèses : le code développé avec TDD est-il de meilleure qualité qu’un groupe cotrôle utilisant waterfall ? Le temps de développement est-il plus court avec TDD ?
➕ Les résultats tendent à montrer une hausse de la qualité, envisagée comme la conformité aux spécifications. La qualité interne du code, cependant, ne présente pas de différence significative avec une méthode plus traditionnelle.
➖ Le résultats montrent 16% de baisse de productivité des développeurs avec TDD. Cependant les chercheurs notent que la comparaison est injuste. Le groupe TDD n’a pas seulement livré du code, il a également livré des tests utilisables à l’avenir.
🍲 Ces résultats s’ajoutent à une grande marmite remplie de résultats contradictoires sur TDD.
SOURCE
George, Boby & Williams, Laurie. (2004). A structured experiment of test-driven development. Information and Software Technology. 46. 337-342. DOI:10.1016/j.infsof.2003.09.011
DOIs:
10.1016/j.infsof.2003.09.011
The Benefits and Consequences of Workarounds in Software Development Projects 🔗
🧑💼 Management
·
👌 Qualité logicielle
🏃♂️ Quelles raisons poussent les développeurs à prendre des raccourcis, au détriment de la qualité du code ? Principalement le deadlines et la préexistence de raccourcis. Autrement dit, les raccourcis sont une drogue dure : une fois commencés, ils sont un habitude impossible à terrasser.
⏱️ Bien entendu, le papier et les 7 études de cas qu’il décrit est plus subtil, mais l’essence du problème est là : on ne peut pas demander une estimation précise à un developpeur, a fortiori un junior. Se baser sur une estimation est contraire à tout ce que nous savons des lois du logiciel et mènera à des raccourcis impossibles à juguler.
👌 Il n’y a que deux manières de faire un logiciel : donner une deadline mais rester souple quant au contenu de la livraison (agilité) ou donner un contenu, mais rester souple quant à la date de livraison. Toute autre conception est un mensonge plus ou moins grossier.
SOURCE
Yli-Huumo, Jesse & Maglyas, Andrey & Smolander, Kari. (2015). The Benefits and Consequences of Workarounds in Software Development Projects. DOI:10.1007/978-3-319-19593-3_1
DOIs:
10.1007/978-3-319-19593-3_1
On Transfer Learning in Code Smells Detection 🔗
🦨 Code Smells
🤖 Les techniques de Transfer Learning fonctionnent pour porter la connaissance de nombreuses odeurs du code d’un langage objet à un autre. Cela pourrait indiquer, comme le subodore l’artisanat du logiciel, l’universalité des odeurs du code.
🦨 Le papier est un preprint, mais si ses résultats sont confirmés, la recherche sur les odeurs du code sera grandement facilitée en permettant la mutualisation de celles-ci entre les communautés des différents langages.
SOURCE
Moabson Ramos and Rafael de Mello and Baldoino Fonseca, On Transfer Learning in Code Smells Detection, EasyChair Preprint no. 7717, EasyChair, 2022
Architecture Technical Debt: Understanding Causes and a Qualitative Model 🔗
📐 Architecture
·
♻️ Refactoring
·
👌 Qualité logicielle
📐 La déviation d’un projet par rapport à l’architecture prévue est une forme de dette technique. Sa gestion est différente de la dette “classique”.
🪲 Tel un insecte, un projet qui grandit doit muer pour adopter une architecture plus adaptée. Cette réarchitecturation ne peut pas être évitée, mais une bonne gestion de cette forme de dette permet d’en réduire la fréquence. Vu le coût d’un tel chantier c’est salutaire.
🔃 L’usage de méthodes agiles tend à augmenter l’accumulation de dette architecturale. Cependant ces méthodes permettent de mieux repérer le problème et de le traiter avant la crise.
😶🌫️ En tout cas, l’idée d’un projet immortel, éternel et immuable est à proscrire et le viellissement du logiciel doit être prévu budgétairement par le management.
SOURCE
Martini, Antonio & Bosch, Jan & Chaudron, Michel. (2014). Architecture Technical Debt: Understanding Causes and a Qualitative Model. Proceedings - 40th Euromicro Conference Series on Software Engineering and Advanced Applications, SEAA 2014. DOI:10.1109/SEAA.2014.65.
DOIs:
10.1109/SEAA.2014.65
Interruptions in Agile Software Development Teams 🔗
🧮 Méthodes de développement
·
🧠 Psychologie
🙉 Un développeur interrompu va mettre un certain temps à se remettre dans le jus, c’est le Context Switching, devant lequel nous ne sommes pas tous égaux. Optimiser la productivité d’une équipe requiert de minimiser les interruptions. L’agilité et sa mise en interaction permanente des développeurs avec les parties prenantes est bien moins optimale sur ce plan qu’un bon vieux tunnel.
✅ Le chercheur Manuel Wiesche donne plusieurs axes pour protéger les équipes agiles des interuptions.
♻️ En haut du podium, le respect scrupuleux des procédures : si le client veut changer un élément, il attend la fin de l’itération pour cela. Il n’interrompt pas intempestivement l’équipe en plein travail. Le temps d’attente est souvent trop long ? C’est un signe que les itérations doivent être plus courtes.
🦍 Ensuite, il préconise d’avoir une personne chargée de juger si le problème vaut le dérangement, une sorte de vigile de l’équipe. Ce peut être un Scrum Master, un PO ou un rôle tournant dans l’équipe. La canalisation des demandes au sein d’un outil de ticketing peut aussi servir ce but.
🤝 Enfin, l’usage de Pair Programming réduit les interruptions au sein même de l’équipe.
SOURCE
Wiesche, Manuel. “Interruptions in Agile Software Development Teams.” Project Management Journal 52 (2021): 210 - 222.
DOIs:
10.1177/8756972821991365
Software Development Waste 🔗
🧑💼 Management
·
🧮 Méthodes de développement
🔗 Une fois n’est pas coutume, le papier que je présente a déjà été vulgarisé par ses auteurs. Je vais me contenter de vous rediriger vers l’article qu’ils ont réalisé : Software Development Wastes.
SOURCE
T. Sedano, P. Ralph and C. Péraire, “Software Development Waste,” 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), 2017, pp. 130-140, doi: 10.1109/ICSE.2017.20.
DOIs:
10.1109.ICSE.2017.20
The Effects of Continuous Integration on Software Development: a Systematic Literature Review 🔗
🧮 Méthodes de développement
·
🥼 Épistémologie
⚠️ L’Intégration Continue n’a pas prouvé son efficicacité à ce jour, en partie parce que les études qui l’ont analysée jusqu’ici sont biaisées. C’est la conclusion détonnante d’une revue de littérature brésilienne.
🌁 Les chercheurs notent que 58% des papiers sur la CI ne la définissent pas avant de l’étudier, ou alors trop lâchement.
👎 Sur les 31 affirmations recensées, 6 sont parfaitement gratuites, c’est à dire sans preuves quantitatives ou qualitatives.
💥 Plusieurs affirmations, même appuyées par des chiffres, se contredisent.
🔴 Sur ce domaine comme sur d’autres, l’abondance de publications ne fait pas leur qualité et notre discipline manque encore gravement de rigueur.
SOURCE
Soares, Eliezio, Gustavo Sizílio, Jadson Santos, Daniel Alencar da Costa and Uirá Kulesza. “The effects of continuous integration on software development: a systematic literature review.” Empirical Software Engineering 27 (2022): 1-61.
DOIs:
10.1007/s10664-021-10114-1
The Video Store Revisited – Thoughts on Refactoring and Testing 🔗
♻️ Refactoring
·
🧪 Tests
·
📜 Lois du développement
🪙 La règle d’or du refactoring est l’interdiction d’éditer à la fois le code et à la fois les tests. Soit on refactore le code, et les tests garantissent de n’avoir rien cassé lors du processus. Soit on refactore les tests à code égal. Cette théorie est belle, mais irréaliste.
💣 Arie van Deursen et Leon Moonen nous expliquent que certains refactorings changent une interface de manière non rétrocompatible. Il est donc rigoureusement impossible de ne pas éditer le code ET les tests en les exécutant.
🧰 Ces refactorings, qu’ils appellent “Type E”, comptent hélas parmi les plus utiles de notre outillage : Extract Subclass, Inline Method, Replace Error Code with Exception et bien d’autres.
🌐 Comment s’en sortir ? Les auteurs ne le précisent pas. Pour ma part, je recommande de tester son code le moins unitairement et le plus fonctionnellement possible pour laisser le maximum de liberté de mouvement aux interfaces. Utiliser son IDE pour effectuer les refactorings réduit le risque d’erreur mais ne l’annule hélas pas.
SOURCE
Deursen, Arie van and Leon Moonen. “The Video Store Revisited – Thoughts on Refactoring and Testing.” (2002).
Agile methods : a comparative analysis 🔗
🧮 Méthodes de développement
🔃 Qu’est-ce qu’une méthode agile, empiriquement ? En version courte, c’est une méthode développement objectiviste (visant l’adéquation entre besoin et solution), incrémentale et empirique (formée par les praticiens), fonctionnant avec des équipes à taille humaine afin de produire des logiciels fonctionnels en minimisant la documentation. La version complète se trouve dans le papier cité.
🔀 Chaque membre de la famille a ses spécificités et ses doctrines d’application. Il est possible de combiner certaines méthodes afin de compenser les faiblesses de l’une par l’autre.
💎 Dans Crystal/XP où XP sert de prototype de méthode, adapté à chaque projet.
🏉 Dans Scrum/XP, où XP vient apporter des pratiques de développement à Scrum qui n’est qu’une méthode de gestion de projet, un cadre dans lequel glisser une vraie méthode agile.
SOURCE
Strode, Diane E.. “Agile methods : a comparative analysis.” (2006).
The Role of Software In Spacecraft Accidents 🔗
💩 Cas d'échecs
🚀 Connaissez-vous le point commun entre le premier vol d’Ariane 5, Mars Climate Orbiter, Mars Polar Lander, Titan IV B-32 et SOHO ? Ce sont des missions spatiales ratées à cause de problèmes logiciels.
🤑 Dans tous ces cas, le risque associé aux défaillances logicielles a été minimisé ou nié afin de privilégier le respect des délais ou du budget.
💥 Cela a pris des formes multiples, mais récurrentes dans les accidents étudiés :
💣 Une diffusion de la responsabilité et de l’autorité. Les années 90 ont remplacé une culture de la supervision par une culture de l’incitation dans l’air du temps, sans pour autant s’assurer de son efficacité. De plus, en cas de dépassement de budget, le premier poste coupé était la sécurité, jugée redondante.
📧 La diffusion des informations était mauvaise. Les canaux étaient inadaptés à la gravité des informations. Sur SOHO, l’information sur le changement du logiciel des gyroscopes responsables de l’accident avait bien été transmise au pilotage … noyée dans des dizaines de mails.
🤠 Les spécifications étaient incomplètes, manquantes ou jamais mises à jour au cours du projet. Certaines parties du code étaient héritées de développeurs partis depuis longtemps, pratiquant le Cowbay Programming à haut niveau.
💋 KISS ? Connais pas. Le spatial c’est compliqué, alors quoi de mieux que des fonctionnalités compliquées et souvent inutiles ? Tous les projets accidentés avaient un code source encombré par de telles choses, souvent “au cas où”.
⛏️ Des morceaux de code ont simplement été minés dans les dépôts des anciennes missions et réutilisés sans tests, sur du matériel différent. Après tout, ça a fonctionné ! On retrouve ici le même schéma qu’avecle Therac-25, étudié par la même Nancy Leveson.
🤨 Les mauvaises pratiques furent légion, comme la non-séparation de systèmes critiques ou l’affichage de messages d’erreur distincts des informations normales. A ce stade, qui est étonné ?
🧪 Last but not least, le code ne comportait souvent aucun test automatisé. Nous sommes dans les années 90, pour rappel. Les campagnes de relecture du code et de tests manuels étaient effectuées sans trop de moyens ou de sérieux, pour économiser le budget.
🤦 Le rapport entier mérite la lecture, tant les similitudes entre les accidents spatiaux et le quotidien du développeur lambda sont édifiantes. Certaines anecdotes prêteraient à rire si elles n’avaient pas crashé des millions de $ d’argent public.
SOURCE
Leveson, Nancy G.. “Role of Software in Spacecraft Accidents.” Journal of Spacecraft and Rockets 41 (2004): 564-575.
DOIs:
10.2514/1.11950
The Effect of Lexicon Bad Smells on Concept Location in Source Code 🔗
🦨 Code Smells
·
🗣️ Nommage
😒 Il est plus difficile de s’orienter dans un code au nommage obscur. En effet, les odeurs lexicales augmentent le temps qu’un développeur met à retrouver les occurrences d’un concept dans un code.
🥼 La conclusion peut paraître évidente, mais comme souvent, mieux vaut une source académique pour convaincre les plus récalcitrants.
🦨 Les odeurs lexicales sont une type d’odeur du code lié à un mauvais nommage. On y trouve la contraction extrême, les termes vagues ou flous, la confusion nom/verbe, l’absence de relation d’hyponymie dans les héritages, etc.
👀 Peu d’outils sont aujourd’hui capables d’épauler les développeurs dans l’élimination de ces odeurs, le pair programming ou la relecture par autrui restent les seuls moyens de s’en prémunir.
SOURCE
S. Abebe, S. Haiduc, P. Tonella and A. Marcus, “The Effect of Lexicon Bad Smells on Concept Location in Source Code,” in 2011 11th IEEE Working Conference on Source Code Analysis and Manipulation, Williamsburg, VI, 2011 pp. 125-134. doi: 10.1109/SCAM.2011.18
DOIs:
10.1109/SCAM.2011.18
Refactoring Test Code 🔗
♻️ Refactoring
·
·
🦨 Code Smells
🛸 Quiconque a déjà pratiqué les tests et le refactoring en même temps s’est rendu compte que le code de test ne se refactore pas de la même manière que le code testé. 4 chercheurs néerlandais ont en effet identifié des odeurs et des refactorings qui lui sont propres.
🤗 Dites bonjour à Mystery Guest, Test Run War, Assertion Roulette du côté des odeurs et à Setup External Resource, Reduce Data, Introduce Equality Method du côté des Refactorings.
SOURCE
Deursen, Arie van, Leon Moonen, Armand van den Bergh and G. Kok. “Refactoring test code.” Report - Software engineering (2001): 1-6.
Software Engineering - As It Is 🔗
💩 Cas d'échecs
🤦♂️ En 1979, Barry Boehm listait 10 lois d’un projet logiciel réussi. Il notait qu’aucune de ces leçons n’avait vraiment été retenue par les développeurs de l’époque. Rien d’original. Sauf que Boehm est un troll : il avait déjà publié le même papier en … 1961. Rien n’a changé en 18 ans.
🪦 Le sel c’est qu’en août 2022, Boehm nous a quittés sans que grand chose n’ait changé. Eventuellement, certaines lois sont devenues caduques, sans que la profession n’applique mieux les connaissances actuelles que celles d’hier.
SOURCE
Barry W. Boehm. 1979. Software engineering-as it is. In Proceedings of the 4th international conference on Software engineering (ICSE ‘79). IEEE Press, 11–21.
DOIs:
10.5555/800091.802916
An empirical investigation into the role of API-level refactorings during software evolution 🔗
♻️ Refactoring
🐛 Vous voulez réduire le nombre de bugs d’une API ? Laissez vos développeurs faire ce $£%!§#@ de refactoring qu’ils demandent depuis des semaines. Mieux, laissez-les décider seuls du moment de refactorer. Cela n’a presque que des avantages :
👉 Le temps moyen de résolution d’un bug chute entre 35% et 63% après un refactoring.
👉 Le nombre de bugs résolus augmente entre 25% et 30% après un refactoring.
⚠️ Le papier présente un facteur de confusion : il est possible que le nombre de bugs résolus soit lié à de mauvais refactorings qu’il faut ensuite corriger. Cependant le temps moyen de résolution est une donnée fiable.
SOURCE
Kim, Miryung, Dongxiang Cai and Sunghun Kim. “An empirical investigation into the role of API-level refactorings during software evolution.” 2011 33rd International Conference on Software Engineering (ICSE) (2011): 151-160. DOI:10.1145/1985793.1985815
DOIs:
10.1145/1985793.1985815
Energy-Driven Software Engineering 🔗
🔣 Science des Langages
·
🌱 Écologie
🔋 Quels langages sont les plus économes en énergie ? C’est une question pertinente quand on connaît la consommation énergétique, donc en partie le bilan carbone de l’IT. Mieux développer est une chose, mais passer sur un langage plus économe est plus facile, au moins pour les nouveaux projets.
🥉 Sans surprise, les langages interprétés comme Python, PHP et Ruby sont en bas du classement.
🥈Au-dessus on retrouve Javascript, C# et C++ dans certaines configurations.
🥇 Sur le podium, C++, Java et C.
⏬ L’étude n’a pas ciblé les dernières versions en date, ce qui peut fausser les résultats pour vos langages préférés, mais l’ordre de grandeur est bien valable.
SOURCE
Oprescu A., Koedjik L., van Oostveen S., Kok S., Energy-Driven Software Engineering
Towards a theory of Conceptual Design for Software 🔗
#️⃣ Façonnage de code
·
🧠 Psychologie
💭 Nous sommes taillés pour appréhender et utiliser des concepts depuis notre enfance. Quoi de plus naturel que d’en retrouver aussi dans les logiciels. Ils aident le développeur à se retrouver dans son code, mais surtout, ils permettent à l’utilisateur de comprendre le potentiel du logiciel qu’il utilise.
💡 Tweets et Hashtags sur Twitter, Corbeille et Fenêtres sous Windows, Instance et Equipement sur World of Warcraft. Un logiciel qui réussit expose des concepts clairs.
📚 Un excellent logiciel n’a même pas besoin d’un manuel pour vous les amener. Ce que l’on nomme Game Design dans les jeux vidéos existe tout aussi bien dans les autres formes de logiciels, et même dans la vie courante : s’il vous faut un manuel pour prendre l’ascenseur, son concepteur a échoué.
💣 A l’inverse, il est possible de définir la complexité d’un design comme suit : un système où les actions de l’utilisateur ont des effets directs qu’il ne peut pas voir et des effets indirects qu’il ne pourra pas anticiper.
1️⃣ Pour atteindre la simplicité, il faut que chaque concept soit lié à un et un seul problème appelé son motif. Chaque motif doit quant à lui être adressé par un et un seul concept pour ne pas créer la confusion.
🔗 Un exemple de cette logique est expliqué dans un autre papier co-écrit par le même auteur : Purposes, concepts, misfits, and a redesign of git.
SOURCE
Jackson, Daniel. “Towards a theory of conceptual design for software.” 2015 ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!) (2015): n. pag. DOI: 10.1145/2814228.2814248
DOIs:
10.1145/2814228.2814248
F-35 Joint Strike Fighter : Problems Completing Software Testing May Hinder Delivery of Expected Warfighting Capacities 🔗
💩 Cas d'échecs
✈️ Le fameux avion F-35 américain est vendu à de nombreux pays avant même son achèvement, malgré des retards et des capacités très en-deça de ses spécifications. Un facteur de retard n’est autre que, surprise, la suite logicielle embarquée.
⏲️ En 2014, le GAO, équivalent américain de notre Cour des Comptes, rapportait des retards chroniques dans les livraisons des logiciels de contrôle mission.
💣 En cause ? Des bugs, un décalage chronique entre le cahier des charges et la version livrée, ainsi que la cohabitation de multiples versions du logiciel rendant pénible le développement.
🤦 13 mois de retard, qui ont provoqué une réaction du Congrès : mettre plus de moyens sur le développement. La Loi de Brooks n’est toujours pas assimilée.
SOURCE
F-35 Joint Strike Fighter: Problems Completing Software Testing May Hinder Delivery of Expected Warfighting Capabilities GAO-14-322
Effect of team diversity on software project performance 🔗
🧑💼 Management
·
🧠 Psychologie
🙃 Rarement définie, encore moins adossée à des études solides, mais pourtant présente dans les discours managériaux, la diversité est le mot à la mode. Ce n’est pas faute de papiers sur le sujet. Qu’en dit la recherche ?
3️⃣ D’abord qu’il faut distinguer 3 types de diversité :
- La diversité de connaissances (Knowledge Diversity) qui varie avec la formation, le poste, etc.
- La diversité sociale (Social Diversity) qui représente la diversité des couches sociales et des genres.
- La diversité des valeurs (Value Diversity) qui représente la diversité des communautés, des cultures et des civilisations.
💣Ensuite, que toutes les diversités ne se valent pas. La diversité produit toujours des conflits qui peuvent être de 2 types : interpersonnels ou liés à la tâche. Les seconds sont productifs, les premiers destructifs.
🤼 Enfin, que chaque type de diversité est corrélé à certains types de conflits, donc à une variation de la productivité :
🟢 La diversité des connaissances (KD) semble augmenter dans tous les cas la performance d’une équipe : différents points de vue produisent des solutions complémentaires, par le mécanisme des conflits liés à la tâche. De plus, les spécialisations différentes évitent bien des conflits interpersonnels dus à l’égo.
🟡 La diversité sociale (SD) n’a pas d’effet clair sur les performances. Elle peut augmenter ou diminuer les deux formes de conflit, selon les cas.
🔴 La diversité des valeurs (VD) augmente principalement les conflits interpersonnels, diminuant la productivité.
🪄 Les chercheurs recommandent au manager avisé de diversifier socialement et professionnellement ses équipes, tout en prenant garde à choisir des profils compatibles entre eux par leurs valeurs et leur vision du monde. Est-ce ce que l’air du temps désigne par diversité ? J’en doute.
SOURCE
Liang, Ting-Peng & Liu, Chih-Chung & Lin, Tse-Min & Lin, Binshan. (2007). Effect of team diversity on software project performance. Industrial Management and Data Systems. 107. 636-653. 10.1108/02635570710750408.
DOIs:
10.1108/02635570710750408
Combating architectural degeneration: a survey 🔗
📐 Architecture
·
♻️ Refactoring
·
📜 Lois du développement
💢 Lorsqu’un logiciel vieillit, il prend en complexité, ce qui a pour conséquence de baisser la vélocité des développeurs : le code est de plus en plus difficile à changer. Une des explications à ce phénomène est la dégénérescence architecturale.
📐 Lorsqu’un logiciel est créé, il possède une architecture, consciemment définie ou émergente. Cette architecture possède une part variable de règles explicites et d’intentions implicites : les lois et l’esprit des lois.
💫 Avec le temps, les développeurs oublient l’esprit des lois, c’est la dérive architecturale (architectural drift) et font des entorses de plus en plus fréquentes aux lois, c’est l’érosion (architectural erosion). Ce dernier phénomène est à rapprocher de l’hypothèse de la vitre brisée.
❓ Comment réaligner l’architecture et le code ? Les chercheurs donnent deux pistes :
👁️🗨️ Extraire régulièrement l’architecture à l’aveugle par reverse engineering, pour la comparer au schéma d’architecture d’origine.
♻️ Effectuer du refactoring pour corriger le tir, ce qui implique la présence de tests automatisés à haut niveau.
SOURCE
Lorin Hochstein, Mikael Lindvall, Combating architectural degeneration: a survey, Information and Software Technology, Volume 47, Issue 10, 2005, Pages 643-656, ISSN 0950-5849, DOI:10.1016/j.infsof.2004.11.005.
DOIs:
10.1016/j.infsof.2004.11.005
A Brief History of Software Development And Manufacturing 🔗
💾 Histoire de l'informatique
·
🧮 Méthodes de développement
⚙️ Selon Ashish et Akshay Kakar, l’histoire des approches de développement logiciel est la même que celle des autres industries, en accéléré.
🪛 A ses balbutiements, dans les années 50, l’approche Code&Fix est un décalque de la production artisanale d’avant 1910.
🏭 Ensuite, dans les années 70 le développement est passé par une phase de taylorisme proche de ce que l’industrie faisait dans les années 1910.
🏎️ Vint la phase Lean des années 90, calquée sur celle que l’industrie connut 20 ans auparavant.
🗒️ Enfin, l’Agile Manufacturing des années 90 aurait été portée chez les développeurs dans les années 2000.
🔮 Ce modèle simplifié, donc imparfait, de notre histoire sert le but que ses auteurs lui ont fixé : prédire l’avenir de notre profession en regardant ce qu’il se fait dans l’industrie.
🤓 Sauf si la prochaine révolution industrielle venait d’abord du développement pour ensuite essaimer ailleurs. Ce n’est pas un scénario improbable.
SOURCE
Kakar, Ashish & Kakar, Akshay. (2020). A Brief History of Software Development and Manufacturing.
On the relation of refactoring and software defects 🔗
♻️ Refactoring
🐛 Le refactoring agit comme un répulsif à bugs. Le nombre de défauts par commit décroît avec le nombre de refactorings dans les commits précédents. C’est la conclusion d’une étude basée sur le minage de projets open-source.
🧑💼 Ce n’est pas le seul avantage du refactoring, mais celui-ci a le mérite d’être compris facilement par les managers.
SOURCE
Ratzinger, Jacek & Sigmund, Thomas & Gall, Harald. (2008). On the relation of refactoring and software defects. Proceedings - International Conference on Software Engineering.
Exploratory study of Overhead in Lean/Agile Software Development 🔗
🧮 Méthodes de développement
🧹 Lean prône la chasse au gaspi parmi ses pratiques fondamentales. Lean Software n’y échappe pas, les Poppendieck ont dressé une liste exhaustive des gâchis dans le processus de développement de logiciels. Sowrabh Mummadi continue cette oeuvre en traquant les frais généraux (overhead), forme plus vicieuse de gâchis.
4️⃣ En étudiant la littérature existante, il liste 4 formes d’overhead, ainsi que leurs effets et les avantages à en réduire l’importance.
👉 Les frais de management, pouvant être dus à une méthode trop lourde ou à des sprints trop courts.
👉 Les frais de coordination, survenant quand un gros produit nécessite la coordination de nombreuses équipes.
👉 Les frais de process, dûs à un trop grand nombre de documents dans les méthodes traditionnelles, ou de membres dans les méthodes agiles.
👉 Les frais de communication, quand les outils de communication ne sont pas adaptés entre les équipes ou avec les clients.
🥗 Une cinquième catégorie regroupe les frais n’appartenant à aucune autres, comme les frais de revue, de débug ou de documentation. C’est dommage car la plupart d’entre eux auraient pu être regroupés sous l’étiquette “development overhead”.
SOURCE
Sowrabh Mummadi, Exploratory study of Overhead in Lean/Agile Software Development, May 2021, Blekinge Institute of Technology
The Difficult Art of Combining Design Patterns with Modern Programming Languages 🔗
🧩 Design (Anti-)Patterns
·
🔣 Science des Langages
·
🎓 Thèse
🩹 Les langages de programmation et les design patterns ont une relation compliquée. Déjà à l’époque du Gang of Four, Peter Norvig signalait que la plupart des patterns n’étaient que des rustines autour de langages trop pauvres. Les lambda des langages fonctionnels dispensent d’utiliser des factory, par exemple. Certains langages supportent nativement certains patterns et d’autres non ? Trop binaire et réducteur nous répond Eirik Emil Neesgaard Årseth.
🎨 A une vision binaire, il répond en classifiant les relations entre langages et patterns en 4 groupes, dans son mémoire de master (!). Ceertains langages incluent certains patterns dans leur syntaxe, nativement. D’autres absolument pas. Entre ces deux extrêmes, certains langages facilitent certains patterns sans les proposer pour autant. Par exemple, Javascript et son système de types facilite grandement le pattern Prototype. Enfin, certains langages ne proposant pas le support d’un pattern sont rattrapés par leur bibliothèque standard. Que serait C# sans Linq, par exemple.
🦽 Alors, les patterns sont-ils des prothèses pour des langages déficients ? Certains, assurément, mais il est abusif d’employer cette formule pour l’ensemble. Alors que les patterns créationnels sont presque tous des features manquantes, l’auteur prend le pari que les patterns structurels sont là pour de bon.
SOURCE
Årseth, Eirik Emil Neesgaard. The Difficult Art of Combining Design Patterns with Modern Programming Languages. Master thesis, University of Oslo, 2020
An Introduction to Software Architecture 🔗
🧮 Méthodes de développement
🏗️ Aussi étrange que cela paraisse, l’architecture logicielle n’est pas une discipline unifiée ou clairement définie. Une des définitions est celle donnée il y a 30 ans par Garlan et Shaw. Pour eux, l’architecture est la réponse à la complexité de certains logiciels, qu’un bon design ne peut plus juguler. Il faut alors ajouter une couche d’abstraction.
⛔ L’architecte ignore volontairement le code, encapsulé dans des blocs de design. Chaque bloc, nommé composant, interagit ou n’interagit pas avec les autres, selon des règles définies par l’architecte. L’ensemble de ces règles d’architecture détermine la forme du système. L’architecture, pour Garlan et Shaw, consiste à sculpter le système par des règles, qui viennent restreindre la manière dont peuvent se connecter les composants.
🪠 Un exemple ? Obligez les composants à avoir x entrées et y sorties dans un format standardisé. N’autorisez que les connecteurs reliant l’entrée d’un composant à la sortie d’un autre. Vous obtenez une architecture Pipes&Filters omniprésente dans la BI, le low-code ou les shells Unix.
👁️ La vision de Garlan&Shaw donne des règles sur la manière dont les composants ne doivent pas agir. Aux développeurs de les respecter. Elle s’oppose à l’architecture positive, qui inverse la logique : l’architecte dit comment les composants doivent interagir, explicitement. Ces deux visions donnent deux types d’architectes très différents. L’architecte négatif pose des règles, l’architecte positif détermine à chaque instant le comportement des équipes.
SOURCE
Garlan, David and Mary Shaw. “An Introduction to Software Architecture.” Advances in Software Engineering and Knowledge Engineering (1993). DOI: 10.1142/9789812798039_0001
DOIs:
10.1142/9789812798039_0001
A survey on software smells 🔗
🦨 Code Smells
🏛️ J’aime les classifications. Alors quoi de mieux qu’un papier classifiant les classifications des odeurs du code ? C’est ce que proposent 2 chercheurs … grecs. Débat de philosophes ou vrai outil ? Analysons leurs résultats.
☣️ Ils ont recensé plus de 200 (!) odeurs du code dans la littérature existante, rangés dans 14 classifications différentes. Pour les chercheurs, toutes ces classifications peuvent être regroupées en 4 cohortes selon qu’elles classifient eles odeurs selon :
👉 Les principes qu’elles violent
👉 Les effets qu’elles produisent
👉 Les types qu’elles touchent (data, interfaces, etc.)
👉 Leur granularité (intra-classe, design, architecture, etc.)
🐜 Cette clarification n’est pas le seul résultat de ce travail de fourmi ! En comparant les travaux des chercheurs, ils ont noté plusieurs problèmes :
🔴 Peu de chercheurs différencient odeur et antipattern avéré.
🔴 Les définitions de certaines odeurs sont contradictoires entre les papiers.
🟡 La détection et la contextualisation automatique de celles-ci est au mieux balbutiante.
🟡 Nous n’avons pas de preuve solide corrélant odeur et baisse de productivité.
🌋 Les odeurs du code sont un champ de recherche très actif, il faudra encore des années avant d’en voir la maturité.
SOURCE :
Tushar Sharma, Diomidis Spinellis, A survey on software smells, Journal of Systems and Software, Volume 138, 2018, Pages 158-173, ISSN 0164-1212, DOI:10.1016/j.jss.2017.12.034.
DOIs:
10.1016/j.jss.2017.12.034
Comparing four approaches for technical debt identification 🔗
👌 Qualité logicielle
·
#️⃣ Façonnage de code
🔎 Quels sont les meilleurs outils pour identifier la dette technique* ? Certains repèrent des odeurs du code, d’autres des violations de modularité, d’autres encore des violations d’usage des patterns tandis qu’une dernière catégorie repère des défauts connus.
🧩 Tous et aucuns ! Les problèmes que ces outils identifient se recouvrent très peu, il vaut mieux les cumuler.
* Le terme de dette technique désigne ici la complexité accidentelle du code, non la prise de dette au sens ou l’entend Ward Cunningham. Le terme aurait pu être mieux choisi.
SOURCE
Zazworka, N., Vetro’, A., Izurieta, C. et al. Comparing four approaches for technical debt identification. Software Qual J 22, 403–426 (2014). DOI:10.1007/s11219-013-9200-8
DOIs:
10.1007/s11219-013-9200-8
Why Large IT Projects Fail ? 🔗
📜 Lois du développement
😱 Chaque jour qui passe, le besoin réel à l’origine de vos spécifications évolue. Les spécifications, purs documents légaux, sont figées jusqu’à la prochaine livraison. Plus celle-ci est éloignée du recueil du besoin plus le produit sera décevant pour l’utilisateur. C’est le Glissement des Exigences (Requirements Drift) d’Henderson.
🚀 Ce phénomène est vicieux car très progressif en apparence. Si 0,1% de votre spécification devient obsolète chaque jour par rapport au besoin, les coûts de développement d’un produit satisfaisant auront rapidement doublé !
💡 Le glissement des exigences n’est pas seulement une reformulation de la première loi de Lehman, c’est une explication.
🔃 La morale de l’histoire : plus vous faites des itérations courtes, plus vous vous remettrez souvent en phase avec le besoin réel de votre client, moins le projet débordera.
SOURCE
Henderson, Peter B. “Why Large IT Projects Fail.” (2010).
Value and benefits of model-based systems engineering (MBSE): Evidence from the literature 🔗
🥼 Épistémologie
·
🧮 Méthodes de développement
🗺️ Qui n’a pas eu à l’école ce prof convaincu que dans l’avenir, il suffira de dessiner un diagramme UML pour créer un système ? L’intendance suivra. Cette idée, nommée Model-Based Software Engineering (MBSE) est venue remplacer les tombereaux de documents qui servent encore de source de vérité dans de nombreuses entreprises. Une revue de littérature de 2021 vient jeter un pavé dans la mare : il n’y a aucune preuve de l’efficacité de cette pratique.
💨 En démêlant le millier de papiers sortis sur le sujet, Henderson et Salado ont découvert très peu de preuves solides. 360 papiers affirment un bénéfice que 2 seulement mesurent objectivement. 36 “observent”, 240 “perçoivent” et 109 référencent un autre papier. L’homme qui a vu l’homme qui a perçu le loup !
❗ Pire, parmi les bénéfices prétendus de MBSE, des contradictions sont présentes et les chercheurs ne s’accordent pas sur une définition claire.
📣 La NASA ou L’International Council on Systems Engineering font de MBSE le standard de la profession pour 2025 sur la base de l’abondance des publications en sa faveur, mais la quantité est-elle la qualité ? Notre discipline a encore du chemin a faire vers la rigueur scientifique.
SOURCE
Henderson, K, Salado, A. Value and benefits of model-based systems engineering (MBSE): Evidence from the literature. Systems Engineering. 2021; 24: 51– 66. DOI:10.1002/sys.21566
DOIs:
10.1002/sys.21566
The business value of agile software development: Results from a systematic literature review 🔗
🧮 Méthodes de développement
💣 L’intérêt de l’agilité ne réside pas dans son meilleur respect des délais et des coûts. La recherche n’a d’ailleurs jamais affirmé que l’agilité ferait mieux que les méthodes dites “traditionnelles” à ce sujet. Un groupe de chercheurs allemands démontre grâce à une revue de littérature que la “valeur métier” de l’agilité dépasse de loin la simple performance économique :
😎 A un niveau individuel les développeurs se sentent plus motivés et impliqués dans leur travail
🏉 Les équipes sont plus soudées et interagissent mieux
🏢 L’entreprise tend à se réorganiser plus facilement
📊 Les process tendent à être plus souples et performants
🤩 L’agilité est une culture de la satisfaction client, non une méthode de conduite de projet.
❌ Pour enfoncer le clou, ils remarquent que les gains de performance attribués à l’agilité sont en réalité parfaitement corrélés à des pratiques distinctes de celle-ci :
🏭 Le refactoring réduit le nombre de bugs, le temps de débug et la performance du code
🧪 Les tests intensifs et le pair programming réduisent la densité de défauts des logiciels
🕯️ Les rituels augmentent la cohésion et la communication de l’équipe
🪢 Y a-t-il un intérêt à rassembler sous l’étiquette “agilité” des pratiques et une culture disparates ? Oui selon les chercheurs, car toutes ces pratiques forment un tout où chacune renforce l’efficacité des autres. Ils valident une intuition déjà exprimée il y a 30 ans par eXtreme Programming.
SOURCE :
Meckenstock, Jan-Niklas; Hirschlein, Nico; Schlauderer, Sebastian; and Overhage, Sven, “The business value of agile software development: Results from a systematic literature review” (2022). ECIS 2022 Research Papers. 24. https://aisel.aisnet.org/ecis2022_rp/24
A controlled experiment in maintenance: comparing design patterns to simpler solutions 🔗
🧩 Design (Anti-)Patterns
🏹Les design patterns sont-ils overkill par rapport à ce qu’ils apportent ? Tout dépend de la situation, nous répond une étude allemande. Dans certains cas ils alourdissent un code qui ne demande qu’à être laissé tranquille, dans d’autres ils sont une solution élégante.
👨💻 Seule l’expérience du professionnel permet de juger efficacement de la pertinence d’un pattern par rapport à une solution n’en comportant pas. Encore faut-il que ledit professionnel respecte 2 conditions :
👉 Connaître les patterns
👉 Ne pas les déifier
♻️ Je recommande pour ma part de développer les deux options « quick&dirty », sous forme de prototype jetable, afin de dissiper les doutes sur la meilleure solution.
🔰 Chose notable, l’étude a été réalisée sur des professionnels confirmés, non sur des étudiants.
SOURCE :
L. Prechelt, B. Unger, W. F. Tichy, P. Brossler and L. G. Votta, « A controlled experiment in maintenance: comparing design patterns to simpler solutions » in IEEE Transactions on Software Engineering, vol. 27, no. 12, pp. 1134-1144, Dec. 2001, doi: 10.1109/32.988711.
DOIs:
10.1109/32.988711
Bad Smells in Software – a Taxonomy 🔗
🦨 Code Smells
🦨 Il est temps de ranger les odeurs du code ! Perdu par leur trop grand nombre et par leur manque de formalisation, le chercheur Mika Mäntylä s’est attelé à les classifier dans sa thèse qui figure au rang des classiques. Son classement a même été repris par des sites grand public comme Sourcemaking ou Refactoring Guru.
💩 Les Bloaters désignent les objets qui sont devenus trop gros pour pouvoir être appréhendés par notre esprit. Méthodes longues, God Classes, mais également plus étonnant, Primitive Obsession et Data Clumps.
📦 Tout ce qui contrevient aux principes de l’orienté-objet est rangé dans la catégorie Object Orientation Abusers. Les switchs, champs temporaires, refus d’héritages y figurent, avec les duplications d’interfaces.
⛓️ Les odeurs ralentissant ou entravant le changement sont nommées Change Preventers.
🗿 Tout ce qui est inutile, mort ou contrevenant au principe YAGNI est un Dispensable.
🪢 Le couple Message Chains/Middle Man, est appelé Encapsulators.
🖇️ Les Couplers, eux, créent du couplage superflu, donc néfaste, entre les classes.
🪄 Cette classification a des défauts dont était déjà conscient Mäntylä : catégories pour 2 odeurs, odeurs ne rentrant dans aucune. Il s’agit d’un outil perfectible, mais pas dépassé depuis 20 ans à ma connaissance.
SOURCE
Mäntylä, Mika & Vanhanen, Jari. (2003). Bad Smells in Software – a Taxonomy and an Empirical Study.
Bad Smells in Software – Software Maintainability 🔗
📜 Lois du développement
·
🎓 Thèse
👎 La maintenance des logiciels n’existe pas, dans les faits. C’est une conséquence des lois de Lehman. Pour un logiciel, maintenir son contenu fonctionnel intact, c’est déjà décliner. Pour le chercheur Mika Mäntylä, il faut oublier l’idée de maintenance au profit de la notion d’évolution.
♻️ Le vocabulaire de la maintenance du logiciel, hérité de la maintenance industrielle (adaptative, perfective, corrective) n’est pas pertinent pour décrire le cycle de vie des logiciels. En effet, la maintenabilité n’est pas, comme pour un pont ou une route, la capacité à rester identique, mais bien la capacité à évoluer.
🧑🏫 Si la maintenance évolutive est une arnaque sur le plan contractuel, elle est la routine dans le fonctionnement des logiciels. Beaucoup de pédagogie est nécessaire pour le faire accepter aux clients.
SOURCE
Mäntylä, Mika & Vanhanen, Jari. (2003). Bad Smells in Software – a Taxonomy and an Empirical Study.
Partition testing does not inspire confidence 🔗
🧪 Tests
🤠 Dans la vie il y a deux types de testeurs : ceux qui utilisent l’aléatoire et ceux qui partitionnent. Ceux qui utilisent de l’aléatoire trouvent des bugs. Ceux qui partitionnent augmentent leur confiance.
🧠 Partitionner consiste à sélectionner soigneusement les valeurs utilisées lors des tests, contrairement à l’aléatoire qui les teste virtuellement toutes, sur la durée.
🎲 Dans un papier déjà ancien (1990), Hamlet et Taylor réaffirment que, moyennant une puissance de calcul que nous n’avons pas encore en 2022, le test aléatoire est la Rolls, car il permet de trouver plus de bugs.
🚵♂️ Attention cependant à ne pas caricaturer. Une Rolls consomme énormément et ne sert à rien sur les chemins de terre que l’on appelle « phase de spécification » !
🪧 Pour résumer grossièrement un papier que je vous recommande de lire :
1️⃣ Commencez par des tests partitionnés afin de définir votre domaine.
2️ « Hackez » les valeurs choisies pour vos tests dans le but de trouver des bugs.
3️⃣ Seulement dans un troisième temps, passez en aléatoire pour détecter des bugs résiduels.
🐛 Si chaque type de test est à sa place, les bugs seront bien gardés.
SOURCE
D. Hamlet and R. Taylor, « Partition testing does not inspire confidence (program testing), » in IEEE Transactions on Software Engineering, vol. 16, no. 12, pp. 1402-1411, Dec. 1990, doi: 10.1109/32.62448.
DOIs:
10.1109/32.62448
How Development and Personality Influence Scientific Thought, Interest, and Achievement 🔗
🧠 Psychologie
🤓Existe-t-il des traits de personnalité et des conditions de développement prédisposant à être scientifique ? Il semble que oui !
🛬 Vous avez 3 fois plus de chances de faire partie de l’élite scientifique de votre pays si vous êtes enfant d’étrangers.
♀️ Si vous êtes une fille sensibilisée aux sciences après l’adolescence, vous avez moins de chance d’en faire votre métier.
🚸 Un scientifique a de grandes chances de s’être intéressé aux sciences avant 12 ans.
🥇 Les premiers-nés sont en général plus conservateurs scientifiquement que les suivants dans la fratrie.
🤬 Être consciencieux, franc, dominant ou avoir confiance en soi diminuent les chances de s’intéresser aux sciences.
⌨️ Je suis à la recherche d’une étude similaire pour les développeurs !
SOURCE
Feist, Gregory J.. “How Development and Personality Influence Scientific Thought, Interest, and Achievement.” Review of General Psychology 10 (2006): 163 – 182. DOI:10.1037/1089-2680.10.2.163
DOIs:
10.1037/1089-2680.10.2.163
Motivated Humans for Reliable Software Products 🔗
🧠 Psychologie
·
🧑💼 Management
😌 Vous voulez des développeurs productifs ? Fichez-leur la paix en leur épargnant les réunions et les sollicitations incessantes (notifications, téléphone, etc.). Ne les surchargez pas. Ainsi ils pourront entrer plus souvent dans un état de concentration propice à leur art.
📢 Les Open Space ne semblent pas propices non plus à la concentration. Le papier date de 1997, il ne pouvait donc pas évoquer le télétravail, mais celui-ci pourrait être un moyen de laisser les développeurs tranquilles lors des phases où ils ne doivent pas être sollicités.
🥼 Bon sens ? Peut-être, mais avec de la science le message passe toujours mieux.
SOURCE
Frangos, S.A. (1997). Motivated Humans for Reliable Software Products. In: Gritzalis, D. (eds) Reliability, Quality and Safety of Software-Intensive Systems. IFIP — The International Federation for Information Processing. Springer, Boston, MA. DOI:10.1007/978-0-387-35097-4_7
DOIs:
DOI:10.1007/978-0-387-35097-4\_7
An exploratory study of the impact of antipatterns on class change- and fault-proneness 🔗
🧩 Design (Anti-)Patterns
🧂 A-t-on des preuves que les antipatterns sont vraiment générateurs d’erreurs ? Oui, et ils sont même corrélés à du code qui est changé plus souvent (avec le risque de le casser, donc).
⛏️ Ce résultat a été obtenu par une équipe italo-canadienne, en minant le code de projets open-source. Cette technique a permis de grandes avancées dans les sciences du logiciel, mais depuis Lehman, on sait que ces résultats sont à prendre avec prudence : l’open-source ne suit pas les même lois que le développement commercial.
SOURCE
Khomh, Foutse, Massimiliano Di Penta, Yann-Gaël Guéhéneuc and Giuliano Antoniol. “An exploratory study of the impact of antipatterns on class change- and fault-proneness.” Empirical Software Engineering 17 (2011): 243-275. DOI:10.1007/s10664-011-9171-y
DOIs:
10.1007/s10664-011-9171-y
Architectural Styles and the Design of Network-based Software Architectures 🔗
📐 Architecture
·
💾 Histoire de l'informatique
·
🎓 Thèse
🌐 Si Tim Berners-Lee est le papa du Web, alors le parrain en est Roy Fielding. Sa thèse 👇 devrait être lue par tout développeur web. Dans le chapitre 4, notamment, il définit avec précisions les problèmes que doit résoudre l’architecture dont le web a cruellement besoin en l’an 2000 : REST.
Lire la suite
Design patterns impact on software quality : Where are the theories ? 🔗
🧩 Design (Anti-)Patterns
⁉️ Les Design Patterns ont-ils une influence positive sur la qualité des logiciels ? Si quelqu’un vous affirme que les patterns sont obsolètes ou au contraire, qu’ils sont indispensables, il manque clairement de prudence. La recherche n’avait pas tranché en 2018 et de nombreuses questions restent aujourd’hui sans réponse.
🌫️ Nous connaissons beaucoup de propriétés des patterns. Des centaines d’études de cas, positives et négatives, s’accumulent depuis 30 ans dans les tiroirs des chercheurs. De ce brouillard, rien de clair n’est encore sorti, sinon des recommandations limitées, sans aucun caractère général et universel.
💎Que faut-il donc faire ? En attendant que la recherche tranche, ce qui peut prendre des décennies, le plus prudent est de se fier à l’expérience des maîtres. Elle n’est pas unifiée, elle se contredit, mais elle est encore ce qui fonctionne le mieux.
🏺Cette complémentarité, je la nomme Evidence Based Software Craftmanship. La tradition, que chaque génération trie en fonction de ce que la science éclaire.
SOURCE
Khomh, Foutse & Guéhéneuc, Yann-Gaël. (2018). Design patterns impact on software quality: Where are the theories?. 15-25. 10.1109/SANER.2018.8330193.
DOIs:
10.1109/SANER.2018.8330193
Toward a Catalogue of Architectural Bad Smells 🔗
🦨 Code Smells
·
📐 Architecture
🦨 Existe-t-il des « odeurs du code » au niveau architectural ? 4 chercheurs californiens proposent une première liste, qui ne sera validée qu’à la condition de les relier à des anti-patterns architecturaux connus.
👉 Connector Envy : Un Composant réalise des opérations normalement propres à un connecteur (Conversion, Coordination, Communication, Facilitation).
👉 Scattered Parasitic Functionality : Plusieurs composants sont chargées de la même fonctionnalité haut-niveau. Il s’agit souvent d’une manifestation d’un Crosscutting Concern.
👉 Ambiguous Interfaces : Les interfaces ne sont pas explicites, c’est à dire qu’un composant communique avec un autre en utilisant des canaux génériques, sans avoir typé les échanges.
👉 Extraneous Adjacent Connector : Il existe plus d’un connecteur reliant deux composants entre eux. Par exemple un appel direct et un bus.
SOURCE
Garcia, J., Popescu, D., Edwards, G., Medvidovic, N. (2009). Toward a Catalogue of Architectural Bad Smells. In: Mirandola, R., Gorton, I., Hofmeister, C. (eds) Architectures for Adaptive Software Systems. QoSA 2009. Lecture Notes in Computer Science, vol 5581. Springer, Berlin, Heidelberg. DOI:10.1007/978-3-642-02351-4_10
DOIs:
10.1007/978-3-642-02351-4\_10
Improving evolvability through refactoring 🔗
♻️ Refactoring
·
🦨 Code Smells
🦨 Les odeurs du code sont passées dans la jargon courant des développeurs. A tel point qu’elles ont eu des déclinaisons. Les change smells par exemple, sont des odeurs que l’on ne remarque qu’en analysant l’historique des commits.
🕵️ Les chercheurs nous proposent le « Man In The Middle », où une même classe est modifiée sur la majorité des commits, même s’ils n’ont rien à voir fonctionnellement.
🗃️ On retrouve également le « Data Container », qui se remarque paire la présence d’un binôme de classes toujours modifiées ensembles, l’une portant des données, l’autre des comportements.
🔧 Les chercheurs n’ont pas établi un protocole vraiment solide pour vérifier la solidité de leur proposition, mais l’idée mérite d’être méditée par les développeurs et les éditeurs d’outils.
SOURCE
Jacek Ratzinger, Michael Fischer, and Harald Gall. 2005. Improving evolvability through refactoring. SIGSOFT Softw. Eng. Notes 30, 4 (July 2005), 1–5. DOI:10.1145/1082983.1083155
DOIs:
10.1145/1082983.1083155
An empirical study about the effectiveness of debugging when random test cases are used 🔗
🧪 Tests
🔢 La génération semi-aléatoire de tests unitaires plaît beaucoup aux managers. S’il était possible de détecter les bugs sans que les développeurs n’aient à tester, on pourrait livrer plus ! Une équipe italienne a voulu le vérifier.
🐛 L’aléatoire obtient de bons résultats pour identifier des bugs qui seraient passés hors des mailles des tests classiques. Le débug est légèrement plus difficile que sur des tests manuels, ce qui est compensé par la facilité de créer de tels cas de tests.
🐱💻 Ces résultats ne remettent certainement pas en cause l’intérêt des tests fonctionnels ! Ils restent nécessaires dans tous les cas. Cependant, l’aléatoire est un bon moyen d’éviter les raisonnements ad-hoc et de véritablement « hacker » son code à la recherche de bugs.
🧑🎓 Seul bémol du papier : toutes les expériences ont été faites avec des étudiants.
SOURCE
Ceccato, Mariano, Alessandro Marchetto, Leonardo Mariani, Duy Cu Nguyen and Paolo Tonella. “An empirical study about the effectiveness of debugging when random test cases are used.” 2012 34th International Conference on Software Engineering (ICSE) (2012): 452-462. DOI: 10.5555/2337223.2337277
DOIs:
10.5555/2337223.2337277
L'informatique de Claude Pair 🔗
💾 Histoire de l'informatique
👴 « Une découverte scientifique ne porte jamais le nom de son auteur ». Ainsi s’énonce la Loi de Stigler, qui n’a d’ailleurs probablement pas été inventée par Stigler. Cette loi s’applique parfaitement à l’informaticien Claude Pair. Ce précurseur de la science des langages de programmation est largement oublié aujourd’hui malgré une carrière riche en inventions capitales.
🧮 Si je vous parle de pile, de récursivité, de types, de structures de données ou d’analyse syntaxique, première étape de toute compilation ? Ou encore de compilateurs de compilateurs, yacc étant le plus célèbre ?
⚖️ Tous ces outils omniprésents dans nos langages modernes sont des inventions de Claude Pair, bien qu’elles lui soient rarement attribuées. Ses anciens étudiants, feu Marion Créhange (première doctorante en informatique) en tête veulent lui rendre justice depuis vingt ans.
📝 Je vous invite à lire l’article qui a servi de source à ce post, il est très accessible.
SOURCE
L’informatique de Claude Pair Marion Créhange, Pierre Lescanne et Alain Quéré: N°18, Novembre 2021, pages 91-116 DOI:10.48556/SIF.1024.18.91
DOIs:
10.48556/SIF.1024.18.91
Flavors : A non-hierarchical approach to object-oriented programming 🔗
💾 Histoire de l'informatique
·
🔣 Science des Langages
🍨 Parmi les tentatives pour remédier aux défauts de l’héritage, les mixins figurent en bonne place. Ce concept, créé entre 1979 et 1982 a survécu de nos jours, mais inspira aussi d’autres mécanismes comme les traits, les méthodes d’extension ou les méthodes d’interface.
🔷 Les mixins se présentent comme une solution au problème du diamant, casse-tête à la fois sémantique et pratique courant en POO.
🪟 Dans une interface graphique, vous avez des fenêtres. Certaines ont des labels, d’autres non. Certaines ont des bords, d’autres non. De qui hérite une fenêtre à bords avec label ?
❌ Les deux solutions instinctives sont l’héritage multiple et l’usage de patterns. Les deux apportent de la complexité et ne sont pas satisfaisantes sémantiquement. Une fenêtre n’est pas une fenêtre à bords et une fenêtre à label. C’est une fenêtre, avec des bords et un label.
🎨 Les mixins permettent cela. Sémantiquement, ils expriment une inclusion, non un héritage. Un même objet peut inclure plusieurs flavors, dont le mélange créé le mixin. Ces flavors peuvent hériter d’autres flavors, mais en aucun cas être instanciés seuls.
🤯 L’inconvénient de ce système est de laisser une grande place aux conventions, ce qui augmente la charge mentale qui pèse sur les développeurs et les équipes. En outre, ils ne protègent aucunement des paradoxes logiques comme le Diamant de Nixon.
SOURCE
Cannon, Howard I.. “Flavors : A non-hierarchical approach to object-oriented programming.” (2007).
The Economics of Software Development by Pair Programmers 🔗
🤝 Pair Programming
💰 Un des arguments les plus employés contre le pair-programming est son coût. L’idée est simple : mettre deux développeurs sur un même PC double le coût, sans doubler la vitesse d’exécution. L’entreprise perd de l’argent !
❌ Rien de plus faux, déjà en 1975, Brooks dénonçait ce fameux mythe du mois/homme.
📊 30 ans après Brooks, 2 chercheurs ont rassemblé les chiffres issus de la littérature sur le pair programming. Ils ont effectué une simulation économique comparée. D’un côté deux développeurs seuls, de l’autre une paire. Dans tous les cas, la paire produisait plus de valeur.
📈 Les chercheurs ne sont pas allés plus loin, leur seul objectif était de débunker le faux-argument économique contre le pair programming. Ils ont en revanche noté que seul ou en paire, le développeur produit plus de valeur s’il travaille de manière incrémentale.
SOURCE
Erdogmus, Hakan and Laurie Ann Williams. “The Economics of Software Development by Pair Programmers.” The Engineering Economist 48 (2003): 283 – 319.
Ariane 5: Who Dunnit ? 🔗
💩 Cas d'échecs
🚀 4 juin 1996. Ariane 5 décolle de la base de Kourou. 37 secondes plus tard, le lanceur explose avec à son bord des expériences scientifiques. Aucun humain n’était à bord, fort heureusement. A qui la faute ? A la gestion du logiciel dans le programme.
🐛 Une exception non rattrapée a provoqué une conversion incorrecte, puis un arrêt des systèmes du gyroscope. Ce logiciel avait été porté d’Ariane 4 vers Ariane 5 sans avoir été retesté. La faute à qui ? Comme dirait Jacques Ellul, à personne car le processus était trop complexe pour désigner un coupable. Nous pouvons cependant désigner des suspects.
💥 Les développeurs ont fait une erreur. Elle était dormante sur Ariane 4 et ne s’est déclenchée qu’une fois le logiciel porté sur Ariane 5. Ils ne pouvaient pas l’anticiper, les tests étant incapables de prouver l’absence de bugs. Elle aurait pu être évitée par l’usage d’un langage plus fortement typé, mais ils n’ont probablement pas eu le choix.
🧪 Les testeurs pourraient être coupables, mais ont-ils eu le budget et le temps de revérifier tous les systèmes portés d’Ariane 4 à Ariane 5 ? Le rapport indique qu’il n’y a pas eu de tests de cette partie, sans en indiquer la cause.
🪄 Comme d’habitude c’est la faute au process, donc à personne, sauf à la responsabilité individuelle, éventuellement.
SOURCE
Bashar Nuseibeh. 1997. Ariane 5: Who Dunnit? IEEE Softw. 14, 3 (May 1997), 15–16. DOI:10.1109/MS.1997.589224
DOIs:
10.1109/MS.1997.589224
Higher Order Mutation Testing 🔗
🧪 Tests
👾 Les tests de mutation sont incapables de détecter plus que des bugs triviaux. Pour aller plus loin, il faudrait combiner plusieurs mutations par test. Cette technique se nomme HOMT, Higher Order Mutation Testing en Anglais. Le loup ? Le nombre de tests à générer est exponentiel. Comment surmonter cela ?
🧬Deux chercheurs britanniques expliquent que peu de combinaisons correspondent à des bugs potentiels. Tout le défi est de savoir lesquelles. Ils ont essayé plusieurs méthodes pour y parvenir et il semble que les algorithmes génétiques offrent les meilleurs résultats.
🤖 Tenons-nous enfin une application de l’IA au développement qui ne soit pas du marketing ? Pas si vite. Les résultats montrent aussi qu’un modèle entraîné sur un programme ne fonctionne pas sur un autre. La recherche est encore balbutiante, ces outils ne seront pas dans les mains des devs avant longtemps.
SOURCE
Jia, Yue and Mark Harman. “Higher Order Mutation Testing.” Inf. Softw. Technol. 51 (2009): 1379-1393.
An empirical study of the impact of modern code review practices on software quality 🔗
🧮 Méthodes de développement
👓 Nous savons qu’une mauvaise code review baisse la qualité du code. Mais qu’est-ce qu’une bonne review ? Est-ce seulement atteignable ? Les revues formelles des années 70 ont été abandonnées au profit des analyseurs statiques et autres compilateurs avancés. Seules ont survécu les revues modernes, « légères », ritualisées, mais à l’efficacité discutée.
3️⃣ Pour une bonne revue, il faut 3 ingrédients. Si l’un vient à manquer, ça n’est pas la peine de poursuivre.
👉 Une bonne couverture. La revue doit couvrir une bonne partie des modifications. C’est souvent le seul critère retenu pour les revues modernes, d’où leur échec.
👉 Une participation élevée. Si personne ne s’intéresse vraiment au code, autant ne pas organiser de revues.
👉 Un bon niveau d’expertise. Les participants doivent être adaptés au code revu, inviter tout l’open-space n’a aucun intérêt.
🤝 Vous savez quoi ? Le pair programming garantit automatiquement et en direct la satisfaction de tous ces critères. Une revue n’a pas à être forcément asynchrone, contrairement à un mythe bien ancré*.
*Ce paragraphe est un avis personnel
SOURCE
McIntosh, S., Kamei, Y., Adams, B. et al. An empirical study of the impact of modern code review practices on software quality. Empir Software Eng21, 2146–2189 (2016). DOI:10.1007/s10664-015-9381-9
DOIs:
10.1007/s10664-015-9381-9
Who needs software engineering ? 🔗
📜 Lois du développement
👉 Qu’est-ce que le logiciel ? C’est la question que Steve McConnell a posée à plusieurs experts collaborant à l’IEEE Software en 2001. Parmi les réponses, celle de Robert Cochran a particulièrement retenu mon attention. Elle synthétise les propriétés de ce matériau que nous façonnons.
1. Le logiciel est intangible.
2. Il possède un haut contenu intellectuel.
3. Il n’est pas reconnu comme un actif par les comptables et n’est donc pas dans le compte de résultat.
4. Son développement nécessite beaucoup de main d’œuvre, organisée en équipe autour d’un projet. Les développeurs oublient souvent que peu de métiers dans le monde travaillent ainsi.
5. Il ne possède aucune distinction entre R&D et production.
6. En principe, un logiciel peut changer indéfiniment.
💡 Ces principes peuvent paraître évidents, mais je ne les ai jamais retrouvés aussi clairement listés ailleurs.
SOURCE
Mcconnell, Steve. (2001). Who Needs Software Engineering?. Software, IEEE. 18. 5 – 8. 10.1109/MS.2001.903148.
DOIs:
10.1109/MS.2001.903148
The Effects of Layering and Encapsulation on Software Development Cost and Quality 🔗
🔣 Science des Langages
💊 Contrairement à l’héritage, l’encapsulation obtient de bons résultats en matière de qualité logicielle. Deux groupes d’étudiants ont été formés. Le premier avait le code source complet d’une dépendance, le second n’en connaissait que l’interface publique.
⏲️ Le groupe n’ayant que l’interface à disposition a mis moins de temps à développer une même fonctionnalité que celui ayant les sources complètes. Bien entendu, l’interface fournie était claire et sans effets de bord. Une interface trompeuse ou obscure aurait pu largement changer le résultat.
🧑🎓 Hélas, l’étude est peu significative à cause de du faible échantillon (18 personnes) et du fait qu’il s’agisse d’étudiants.
SOURCE : Stuart H. Zweben, Stephen H. Edwards, Bruce W. Weide, and Joseph E. Hollingsworth. 1995. The Effects of Layering and Encapsulation on Software Development Cost and Quality. IEEE Trans. Softw. Eng. 21, 3 (March 1995), 200–208. DOI:10.1109/32.372147
DOIs:
10.1109/32.372147
Experimental assessment of the effect of inheritance on the maintainability of object-oriented systems 🔗
🔣 Science des Langages
↕️ Arrêtez l’héritage ! Il n’est pas nécessaire à l’orienté-objet et serait potentiellement néfaste. Un code avec héritage est plus difficile à modifier que le même code sans héritage.
📝 3 chercheurs on demandé à 4 groupes de 12 étudiants de lire différents codes, utilisant plus ou moins de niveaux d’héritage pour la même fonctionnalité. Ils leur ont ensuite soumis un questionnaire évaluant leur compréhension du code. Le résultat montre une corrélation assez claire.
🗜️ Cependant, les chercheurs notent que la taille du code est encore plus néfaste à la lisibilité. L’héritage pourrait donc être utile s’il amène de la concision. Plus d’études seraient nécessaires.
SOURCE
R. Harrison, S. Counsell, R. Nithi, Experimental assessment of the effect of inheritance on the maintainability of object-oriented systems, Journal of Systems and Software, Volume 52, Issues 2–3, 2000, Pages 173-179, ISSN 0164-1212, DOI:10.1016/S0164-1212(99)00144-2.
DOIs:
10.1016/S0164-1212(99)00144-2
On the Danger of Coverage Directed Test Case Generation 🔗
🧪 Tests
✈️ Générer des tests automatiquement à partir d’une mesure de coverage est toujours une mauvaise idée. Pourtant c’est un standard dans l’aéronautique et le spatial, y compris sur le programme F-35.
🎲 La génération aléatoire avec régression ou la génération dirigée par coverage ne font pas mieux que le pur hasard en matière d’efficacité des tests. Cela signifie que des tests générés parfaitement aléatoirement obtiennent des résultats meilleurs (jusqu’à 2 fois) ou équivalents aux méthodes précédemment citées.
👽 Évidemment, l’étude est légèrement biaisée par l’usage de tests de mutation comme mètre-étalon, mais il est raisonnable de penser que si le coverage est incapable de créer des tests efficaces sur les défauts simples, il ne fera pas mieux que des bugs réels ou complexes.
⚠️ Les chercheurs recommandent de s’en tenir au consensus scientifique : le coverage ne doit être utilisé que comme révélateur des parties du code les moins testées. Pas plus.
SOURCE
Staats M., Gay G., Whalen M., Heimdahl M. (2012) On the Danger of Coverage Directed Test Case Generation. In: de Lara J., Zisman A. (eds) Fundamental Approaches to Software Engineering. FASE 2012. Lecture Notes in Computer Science, vol 7212. Springer, Berlin, Heidelberg. DOI:10.1007/978-3-642-28872-2_28
DOIs:
10.1007/978-3-642-28872-2\_28
Code coverage for suite evaluation by developers 🔗
🧪 Tests
👾 Les tests de mutation sont utiles, mais coûteux à exécuter. Mieux vaut les réserver à l’environnement d’intégration continue. 3 chercheurs américains nous montrent que le statement coverage constitue une bonne approximation aux tests de mutation, suffisante en tout cas pour indiquer aux développeurs les parties sous-testées du code.
🎯 En effet, rappelez-vous : le coverage ne doit JAMAIS être un objectif.
SOURCES
Rahul Gopinath, Carlos Jensen, and Alex Groce. 2014. Code coverage for suite evaluation by developers. In Proceedings of the 36th International Conference on Software Engineering (ICSE 2014). Association for Computing Machinery, New York, NY, USA, 72–82. DOI:10.1145/2568225.2568278
DOIs:
10.1145/2568225.2568278
On the effectiveness of unit tests in test-driven development 🔗
🧪 Tests
🔥 J’ai trouvé la perle rare : une étude sur TDD qui compare cette méthode à Test-Last ! La plupart ont le biais de comparer TDD vs Pas de tests. Malgré son faible échantillon, elle obtient des résultats positifs : TDD serait plus efficace pour obtenir une couverture acceptable que Test-Last.
👾 Cependant l’étude a un biais : la mesure servant à comparer les deux méthodes est le score de mutation. Or, on sait que celui-ci n’est pas totalement corrélé aux fautes réelles.
🏢 Cette étude va dans le bon sens, mais notre profession manque cruellement d’études de cas sur le long-terme, faute de dialogue entre chercheurs et entreprises. Si vous êtes manager, aidez-les ! Contactez l’université la plus proche pour leur proposer de vous étudier.
SOURCES
René Just, Darioush Jalali, Laura Inozemtseva, Michael D. Ernst, Reid Holmes, and Gordon Fraser. 2014. Are mutants a valid substitute for real faults in software testing? In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE 2014). Association for Computing Machinery, New York, NY, USA, 654–665.
Tosun, A., Ahmed, M., Turhan, B., & Juristo, N. (2018). On the effectiveness of unit tests in test-driven development. In M. Kuhrmann, R. V. O’Connor, D. Houston, & R. Hebig (Eds.), ICSSP 2018 – May 26-27 – Gothenburg, Sweden: Proceedings of the 2018 International Conference on Software and System Process (pp. 113-122). Association for Computing Machinery (ACM). DOI:10.1145/3202710.3203153
DOIs:
10.1145/3202710.3203153
Exploring the relationships between design measures and software quality 🔗
👌 Qualité logicielle
📏 Les années 90 ont laissé derrière elles pléthore de mesures quantitatives du code : CBO, RFC, MPC, DAC, ICP, etc. Elles sont passées de mode dès la décennie suivante, faute de preuves de leur efficacité contre les bugs. On leur doit tout de même l’abandon progressif de l’héritage en orienté-objet, plus avantageusement remplacé par la composition dans la plupart de ses usages.
🔎 Le papier du jour analyse l’efficacité de différentes mesures et leur corrélation avec la probabilité de découvrir des défauts. Si les mesures d’héritage ou de couplage s’en sortent bien, les mesures de cohésion ne semblent pas donner de résultats.
🐛 Autrement formulé, si les mesures de cohésion et d’héritage sont bien corrélées à la probabilité qu’il existe un défaut dans un classe, il n’y a aucune garantie que ces défauts quantitatifs soient corrélés à de vrais bugs, qualitativement ressentis comme tel. La plupart des études des années 2000 ont confondu ces notions, ce qui les rend caduques avec le recul.
SOURCE
Briand, Lionel Claude, Jürgen Wüst, John W. Daly and D. Victor Porter. “Exploring the relationships between design measures and software quality in object-oriented systems.” J. Syst. Softw. 51 (2000): 245-273. DOI : 10.1016/S0164-1212(99)00102-8
DOIs:
10.1016/S0164-1212(99)00102-8
Non-software examples of software design patterns 🔗
🧩 Design (Anti-)Patterns
👨🏫 Certains design patterns peuvent être illustrés par des exemples réels, qui aident à les enseigner. Ainsi le commercial agit comme un Proxy pour les questions techniques, le contrôleur aérien est un Médiateur, le médecin un Visiteur, et la chaîne de commandement à l’armée est une Chaîne de Responsabilité.
💭 D’autres, sans doute trop abstraits ou liés aux propriétés particulières du logiciel (personne n’a jamais vu un maçon réaliser une toiture avant les fondations, alors que c’est le quotidien d’un développeur), manquent de tels exemples. Leur enseignement reste, encore aujourd’hui un défi.
🧠 Les exemples, bien qu’utiles, doivent cependant être utilisés avec prudence : ils illustrent bien, mais décrivent mal. Une fois initié à l’aide d’exemples, le développeur doit s’en détacher pour progresser.
SOURCES
Duell, Michael, John Goodsen and Linda Rising. “Non-software examples of software design patterns.” OOPSLA ’97 (1997).
DOIs:
10.1145/274567.274592
Realizing quality improvement through test driven development : results and experiences of four industrial teams 🔗
🧪 Tests
🧪 TDD fonctionne et ses effets positifs s’accumulent dans le temps à condition de ne pas baisser la garde et de correctement respecter la méthode. La papier n’a rien d’original, il est une étude de plus sur le sujet. Son originalité est d’indiquer une corrélation entre la compétence des praticiens et le rapport bénéfices/coûts de TDD.
🧠 Plus les développeurs sont formés, moins le temps supplémentaire passé à écrire les tests se ressent et plus les bugs sont rares. Hélas, les résultats sont statistiquement peu significatifs, à cause de la faiblesse de l’échantillon.
✅ Les papiers s’accumulent sur TDD et aucun n’est encore venu infirmer l’hypothèse que cela fonctionne très bien, avec un peu de formation et beaucoup de sérieux.
SOURCES
Nagappan, Nachiappan, E. Michael Maximilien, Thirumalesh Bhat and Laurie A. Williams. “Realizing quality improvement through test driven development: results and experiences of four industrial teams.” Empirical Software Engineering 13 (2008): 289-302.
DOIs:
10.1007/s10664-008-9062-z
The effects of development team skill on software product quality 🔗
👌 Qualité logicielle
·
🧠 Psychologie
🤯 Les Juniors ont tendance à produire des logiciels de moins bonne qualité que des Novices, remarquent deux chercheurs américains. Comment est-ce possible ? Deux explications :
🎖️ Les chercheurs émettent l’hypothèse que les Junior sont considérés comme des développeurs « comme les autres » par le management, ils se voient attribuer les mêmes tâches que leurs collègues Senior, sans en avoir l’expertise.
⛰️ Je postule que l’effet Dunning-Kruger n’est pas étranger à ce phénomène. Alors que le Novice tâtonne avec prudence, le Junior prend la confiance sans avoir le niveau de ses aînés, il se situe donc sur la « Montagne de la Stupidité », le pire alignement possible. En mûrissant, il comprendra qu’il ne sait rien.
SOURCES
Beaver, Justin & Schiavone, Guy. (2006). The effects of development team skill on software product quality. ACM SIGSOFT Software Engineering Notes. 31. 1-5. 10.1145/1127878.1127882.
DOIs:
10.1145/1127878.1127882
On the Composition of Well-Structured Programs 🔗
👌 Qualité logicielle
🤬 Aucun gain de performance n’a de valeur si un programme n’est pas fiable ! Le vrai défi ne consiste pas à gratter le moindre bit ou la moindre microseconde. La priorité est d’organiser des programmes de plus en plus gros et complexes, grâce à une rigueur et des méthodes prenant en compte les limitations fondamentales de nos cerveaux. Les développeurs doivent être humbles et s’interdire de déployer des programmes qu’ils ne maîtrisent pas complètement.
💰 Économiquement, le salaire des développeurs est plusieurs ordres de grandeur plus cher que le temps de calcul. En gâcher 90% en maintenance est inexcusable.
🤦♂️ Ce propos n’a rien d’innovant ? C’est bien le problème, il a été écrit en 1974 par Niklaus Wirth. Rien n’a changé.
SOURCES
Niklaus Wirth. 1974. On the Composition of Well-Structured Programs. ACM Comput. Surv. 6, 4 (Dec. 1974), 247–259. DOI:10.1145/356635.356639
DOIs:
10.1145/356635.356639
Enough About Process : What We Need are Heroes 🔗
🧠 Psychologie
·
✊ Corporatisme
·
🏺 Artisanat
🧠 Début février, je postais un article sur l’opposition entre artisanat et ingénierie. Une différence dont je n’ai pas parlé, pour ne pas alourdir mon propos, est le lien entre process et compétences.
🤖 L’industrie, que ce soit voulu ou non, remplace la compétence par le process, qui est sa version encapsulée et simplifiée pour être comprise par une machine.
🦾 L’artisanat assiste la compétence par le process, qui n’en est que l’auxiliaire.
🦸 Cette distinction fait écho à la notion d’héroïsme, telle que la souhaite Roger Pressman, dans un papier resté célèbre. Il peste contre le tout-process, qui consiste à jeter le héros dans le même sac que le hacker ou le cowboy, deux figures mal-vues, souvent à raison, dans notre métier.
✨ Notre métier n’accumule les réussites que lorsqu’une mentalité artisanale permet aux héros de prendre le leadership sur les projets, même si Pressman n’utilise pas ce terme.
SOURCE
Bach, James. “Enough About Process: What We Need are Heroes.” IEEE Softw. 12 (1995): 96-98. DOI : 10.1109/52.368273
DOIs:
10.1109/52.368273
Science and substance : a challenge to software engineers 🔗
🥼 Épistémologie
🛑 Le travail que je réalise ici est probablement trompeur. Il y a presque 30 ans, Fenton, Pfleeger et Glass nous alertaient contre un ennemi subtil : la mauvaise science. La situation n’a probablement pas changé et ça n’est que maintenant que je découvre cet article édifiant.
🧠 Mon but avec cette veille est de privilégier l’empirisme à l’intuition. Un raisonnement même brillant ne suffit pas : il faut des chiffres, solides de préférence.
🥼 Je n’ai pas de formation scientifique et les écoles ne sensibilisent pas les étudiants à la recherche. Il me manque des bases solides et ça n’est que par intérêt pour l’empirisme (organisateur de bien des aspects de ma vie), que je me suis lancé dans ce travail d’intérêt général. J’y amène mes limites.
👁️ C’est ce « mieux que rien » qui me fait continuer. Toutefois, après la lecture de cet article, je vais veiller à améliorer progressivement ma manière d’interpréter la recherche.
🔝 Quels seraient ces axes d’amélioration selon les auteurs ?
👉 Vérifier l’adéquation entre l’expérience et l’hypothèse testée.
👉 Ne pas automatiquement croire les données issues de recherches sur des étudiants ou sur des projets conçus pour l’occasion. Il faut recueillir des données de vrais praticiens sur de vrais projets.
👉 Vérifier que les mesures effectuées sont légitimes sur les données recueillies.
👉 Vérifier la temporalité, un résultat peut être différent à court et long-terme.
👉 Vérifier la représentativité, certaines expériences sont trop courtes ou avec un échantillon trop restreint, ou biaisé.
🤑 Ce n’est que comme cela que notre profession sortira de l’immaturité et des promesses des vendeurs de solutions-miracle.
SOURCE
N. Fenton, S. L. Pfleeger and R. L. Glass, « Science and substance: a challenge to software engineers, » in IEEE Software, vol. 11, no. 4, pp. 86-95, July 1994, doi: 10.1109/52.300094.
DOIs:
10.1109/52.300094
Critical success factors for software projects : A comparative study 🔗
🧑💼 Management
🔝 Tel un Youtubeur en manque d’inspiration, je vais résumer le papier du jour par un TOP 5 (le dernier va vous étonner, pouce bleu, abonnement). Quels sont les facteurs de succès les plus critiques dans un projet logiciel, selon 43 publications étudiées ?
5️⃣ Avec 22 papiers le mentionnant, le soutien du top management, incluant la confiance envers l’équipe de développement, n’est pas à négliger.
🥉 Les compétences du management et la pertinence de la méthode utilisée sont cités par 23 papiers. Si vous me suivez, j’ai déjà donné quelques pistes sur ce que la recherche en pense.
🥉 Ex-aequo, l’adoption d’un planning réaliste. Si vos devs acceptent mollement VOS estimations ou alertent qu’elles sont irréalistes, écoutez-les. Imposer une deadline relève souvent du caprice si les devs vous disent que c’est impossible.
🥈 Des objectifs clairs sont cités par 24 papiers. Trop souvent cette évidence manque. Le projet ne peut pas réussir, faute d’avoir une définition de la réussite connue de tous.
🥇 Avec 26 citations, la clarté des exigences&spécifications mérite sa place en tête. Là encore, si vous me suivez, vous savez que c’est un serpent de mer et que seule une démarche itérative et pilotée par les tests (EATDD) produit des effects significatifs.
🔧 Vous noterez qu’il n’y a AUCUN facteur technique. Les développeurs ne sont pas le facteur limitant dans le marais de sous-qualité contemporain. Le gâchis logiciel est dans les méthodes.
SOURCES
Nasir, Mohd Hairul Nizam Bin Md and Shamsul Sahibuddin. “Critical success factors for software projects: A comparative study.” Scientific Research and Essays 6 (2011): 2174-2186. DOI:10.5897/SRE10.1171
DOIs:
10.5897/SRE10.1171
Iterative enhancement : A practical technique for software development 🔗
💾 Histoire de l'informatique
·
🧮 Méthodes de développement
🔁 Le développement itératif et incrémental (IID), souvent rebrandé « Agilité », n’est certainement pas une technique nouvelle sur laquelle nous n’aurions pas de recul. Avant que l’OTAN ne créé l’ingénierie du logiciel en 1968, les développeurs ont accumulé de beaux succès avec une méthode que Basili et Turner ont synthétisée en 1975.
🦴 Tout commence avec « une implémentation initiale d’un squelette de sous-problème », autrement dit peu de choses. Les développeurs viennent ensuite dépiler des tâches présentes sur une liste, pour bâtir itérativement le logiciel.
8️⃣ A tout moment, 8 règles doivent être respectées :
👉 S’il y a une difficulté, le refactoring doit faciliter sa résolution
👉 Si les modifications ne sont pas circonscrites à un module, il faut redesigner.
👉 Même chose pour les tables
👉 Plus une itération progresse, plus la modification doit être simple à achever. Sinon il faut refacto.
👉 La durée de vie d’un patch ne doit jamais dépasser 2 itérations
👉 Le code doit être relu fréquemment à la lumière des objectifs
👉 Les outils d’aide au développement doivent être utilisés le plus fréquemment possible, pas seulement à la fin d’une itération
👉 Il faut en permanence collecter les retours utilisateurs et améliorer l’implémentation.
🗑️ Cette méthode n’a jamais cessé d’être appliquée, même si les années 80 ont préféré recourir massivement aux méthodes Waterfall, gonflant les taux d’échec et ruinant la réputation de notre profession.
SOURCES
Basili, Victor R. and Albert J. Turner. “Iterative enhancement: A practical technique for software development.” IEEE Transactions on Software Engineering SE-1 (1975): 390-396. DOI : 10.1109/TSE.1975.6312870
DOIs:
10.1109/TSE.1975.6312870
Object-oriented programming with flavors 🔗
💾 Histoire de l'informatique
·
🔣 Science des Langages
🍦L’orienté-objet n’est pas né d’une traite. Son histoire est jalonnée de prototypes, qui ont pavé la voie à ce qu’il est aujourd’hui. Les flavors en font partie. Ancêtre direct des mixins/traits modernes, ils n’ont jamais été implémentés hors de LISP.
🧑🔬 Outre l’intérêt historique du papier, il me permet d’évoquer le creuset de ce paradigme : OOPSLA. Il s’agit d’une conférence annuelle de chercheurs en langages de programmation. Aujourd’hui fondue dans SPLASH, elle était autrefois indépendante.
🧠 En sont sortis une grande partie des papiers présentés ici et beaucoup de grands noms de la profession y ont développé leurs idées : Barbara Liskov, John Vlissides, Kent Beck, David Parnas et j’en passe.
💮 C’est à l’OOPSLA 1986 que David Moon et Howard Cannon ont proposé l’idée des Flavors. Il s’agit d’une manière de faire partager des méthodes et attributs communs entre deux classes, sans qu’elles ne dépendent d’un parent commun.
🧩 L’héritage simple est débattu depuis longtemps. L’abandon de l’héritage multiple, expérience malheureuse de C++, et l’insuffisance de la composition, jugée lourde par certains praticiens, ont abouti à l’idée de « traits » partagés par plusieurs classes sans lien hiérarchique. On les retrouve aujourd’hui en Kotlin, PHP, Ruby, Rust, Scala, pour ne citer que les principaux.
💣 Plus suprenant, C# et Java implémentent un système de traits sans l’assumer, en permettant la définition de méthodes dans les interfaces. L’idée aura mis 20 ans à percer, nul doute qu’elle ne sera pas correctement utilisée avant encore 20 ans. Tout ce qui rend passionnant ce métier en somme.
SOURCE
David A. Moon. 1986. Object-oriented programming with flavors. SIGPLAN Not. 21, 11 (Nov. 1986), 1–8. DOI:10.1145/960112.28698
DOIs:
10.1145/960112.28698
Coverage and Its Discontents 🔗
🧪 Tests
Pour bien enfoncer des portes ouvertes, encore un papier sur le lien entre coverage et qualité des tests :
❌ Attacher une prime ou un objectif quelconque au coverage est la pire des idées. Elle poussera les développeurs à faire de mauvais tests.
❌ Branch-coverage, statement-coverage, etc. Aucun ne sort du lot en matière de bugs découverts.
❌ Les tests de mutation semble posséder les mêmes biais que le coverage. D’autres recherches sont nécessaires.
✔️ Le Coverage restera toujours un meilleur indicateur que le nombre de tests ou leur temps d’exécution.
✔️ Le Coverage permet de repérer les parties du code sous-testées, c’est son principal (seul ?) avantage.
💡 En résumé, utilisez le coverage pour repérer les oublis de votre politique de tests, pas comme indicateur d’absence de bugs !
SOURCES
Groce, Alex & Alipour, Mohammad & Gopinath, Rahul. (2014). Coverage and Its Discontents. 10.1145/2661136.2661157.
DOIs:
10.1145/2661136.2661157
The Impacts of Low/No-Code Development on Digital Transformation 🔗
🧮 Méthodes de développement
·
🦥 Low/No Code
💸 Je lis parfois des propos rageurs, souhaitant le chômage à ces incompétents de développeurs, enfin rendus inutiles par le Low/No Code (LNC). Outre le manque de charité flagrant, la recherche n’est pas du même avis : LNC et développeurs sont complémentaires, et ce pour longtemps.
🇨🇦 Le chercheur Zhaohang Yan, de l’université de Toronto, synthétise une vingtaine d’articles présentant les avantages et inconvénients des outils LNC.
✔️ Une application LNC est bien plus agile qu’un développement classique, avec un temps de développement divisé par 5 ou 10.
✔️ L’utilisation de LNC permet de libérer les développeurs des tâches à faible valeur, auxquelles peuvent se consacrer les utilisateurs, directement.
✔️ LNC offre un exutoire aux utilisateurs, moins tentés d’utiliser des outils non-conformes aux politiques de sécurité, dits « Shadow IT »
➖ Les applications LNC semblent plus maintenables que les projets classiques, mais les données sont peu significatives.
❌ Une application LNC n’est ni scalable, ni customisable. Si les briques logiques offertes par une plateforme ne permettent pas d’exprimer un besoin, développer un logiciel sera moins coûteux que de créer une chimère, infecte à maintenir.
❌ Adopter LNC c’est faire une confiance totale à une plateforme. Confiance en matière de sécurité (gros acteurs = gros intérêt des assaillants), de confidentialité (les GAFAM vivent de vos données) et de durabilité (la plateforme sera-t-elle là dans 10 ans ?). Totale, car il est très compliqué de migrer une application LNC.
SOURCES
Yan, Zhaohang. (2021). The Impacts of Low/No-Code Development on Digital Transformation and Software Development.
DOIs:
2112.14073v1
« Cloning Considered Harmful », Considered Harmful 🔗
#️⃣ Façonnage de code
🍸 DRY : Don’t Repeat Yourself. Un slogan rabâché aux étudiants du monde entier, souvent comme un dogme. Largement sorti de son sens original (ne pas dupliquer de connaissance), il devient souvent une chasse aux sorcières anti-duplication du code, créant des monstres.
🇨🇦 Deux chercheurs canadiens ont décortiqué ce problème en distinguant plusieurs buts à la duplication, chacun présentant un bilan plus ou moins positif en faveur de la duplication.
🍴 Le forking, où le clone vit indépendamment de sa source, pose très peu de problèmes, tant que les deux codebases sont régulièrement nettoyées et qu’elles n’ont pas d’interactions entre elles.
🗋 Le templating, simple copier-coller d’un snippet pour en reproduire les effets présente deux grands dangers : multiplier les coûts de maintenance et dupliquer un code buggé. Il est déconseillé sauf si les avantages contrebalancent ce choix.
🪄 La customisation est une simple inspiration, avec ou sans copier-coller, d’un code qui sera remanié ensuite pour résoudre le problème. Elle est un bon moyen de gagner du temps à court-terme, mais créé une dette technique qui devra être tracée et résorbée.
🧪 Les auteurs ne parlent pas de duplication dans les tests, qui sont un 4ème cas à ajouter au papier : on sait qu’il vaut mieux un test dupliqué qu’un test obscur, la clarté primant sur tout le reste.
📝 Chacune de ces catégories est subdivisée plus finement, je vous encourage à lire le papier pour avoir une vision plus fine du sujet que LinkedIn ne le permet !
SOURCES
Hunt, Thomas, Pragmatic Programmer, The: From Journeyman to Master. Pearson. 2000.
Kasper, C. and Godfrey, M.W. (2008) Cloning Considered Harmful, Considered Harmful: Pattern of Cloning in Software. Empirical Software Engineering, 13, 645-692 DOI:10.1007/s10664-008-9076-6
DOIs:
10.1007/s10664-008-9076-6
Does code decay ? Assessing the evidence from change management data 🔗
📜 Lois du développement
·
♻️ Refactoring
☠️ Le code se décompose-t-il ? Pas au sens biologique, car il est une pure information, immuable. Cependant, tout développeur le sait, un code qui prend de l’âge devient plus difficile à éditer, coûte plus cher et se constelle de bugs. Ce phénomène est inévitable autant bien le connaître !
🩺Ses symptômes sont connus :
👉 Le code devient bouffi et complexe, les développeurs s’engluent dans des modifications interminables.
👉 Les bugs se multiplient et la satisfaction des utilisateurs baisse.
👉Les commits n’ont plus de cohérence (shotgun surgery)
👉 Les développeurs ne vont plus droit au but, ils beurdassent* le code pour espérer arriver à leurs fins.
🕳️ La décomposition du code doit alerter les développeurs : ignorer cette odeur est extrêmement dangereux et se soldera inévitablement par la mort du projet à moyen ou long terme. Si rien n’est fait, une part de plus en plus grande de la productivité de l’équipe ira dans le trou noir des intérêts de la dette, jusqu’à la paralysie complète.
♻️ Une lueur d’espoir persiste cependant : il existe une cure de jouvence facile d’accès qui se nomme refactoring.
* Traduction libre de « code churn » via ce verbe saintongeais. Amitiés aux québécois qui en ont hérité.
SOURCES
S. G. Eick, T. L. Graves, A. F. Karr, J. S. Marron and A. Mockus, « Does code decay? Assessing the evidence from change management data, » in IEEE Transactions on Software Engineering, vol. 27, no. 1, pp. 1-12, Jan. 2001, doi: 10.1109/32.895984.
DOIs:
10.1109/32.895984
The magical number seven: still magic after all these years ? 🔗
🧠 Psychologie
🪄 Pourquoi le chiffre 7 est-il si magique ? Selon le psychologue Miller, il est une bonne approximation de la capacité de la mémoire immédiate humaine sur des tâches génériques (auxquelles le sujet n’a pas été entraîné). Mais en quelle unité s’exprime cette capacité ? En éléments ? Non ! En chunks.
🧠 Un chunk est une « case » dans notre mémoire. Pour Miller et la psychologie cognitive, lorsque nous devons accomplir une tâche, notre cerveau doit charger des éléments en mémoire, afin de les manipuler pour obtenir un résultat. Pour un développeur, ce sont des arguments d’une méthode, des classes ou tout autre artefact du code.
📦 Chez un novice, chaque chunk correspond en général à un élément. L’intérêt du concept apparaît avec l’entraînement : un individu apprend rapidement à « compresser » les informations pour augmenter la densité d’éléments par chunk. Le cerveau possède un grand nombre d’outils pour cela, comme l’abstraction, le mapping avec des éléments stockés dans la mémoire à long terme ou encore l’utilisation de représentations visuelles ou sonores.
📊 En réalité 7 (6.5 précisément) est une moyenne, mais en réalité la capacité de nos cerveaux s’échelonne entre 3 et 15 éléments, suivant une courbe en cloche.
🤝 Ces travaux nous aident à comprendre nos cerveaux et ceux des utilisateurs qui consomment nos produits, afin de tirer le meilleur parti des limites biologiques de notre condition.
SOURCES
Baddeley, Adrian J.. “The magical number seven: still magic after all these years?” Psychological review 101 2 (1994): 353-6 DOI:10.1037/0033-295x.101.2.353
DOIs:
10.1037/0033-295x.101.2.353
Can testedness be effectively measured ? 🔗
🧪 Tests
🔨 C’est dans les vieilles controverses que l’on trouve les meilleurs papiers. 5 chercheurs démontrent que le score de mutation ne fait pas mieux que le coverage pour éviter des bugs futurs. Leur résultat va à l’encontre du consensus établi. Artefact statistique ? Non, nouvelle méthode de calcul et critique rigoureuse des précédents travaux.
🐛 La méthode de calcul précédemment admise, consistait à introduire des bugs dans un programme, puis à vérifier le pourcentage de ces bugs couverts par la méthode testée (branch coverage, statement coverage, mutation score, etc.).
🪲 Pour les auteurs, il n’y a qu’une très faible corrélation avec les bugs réels. Ils ont préféré miner les sources de logiciels Open Source et vérifier, pour chaque bug résolu, si le code fautif était couvert par la méthode testée.
🏆 Le résultat renvoie le score de mutation au niveau des autres méthodes : utile pour repérer les parties sous-testées, pas plus. Le champion tombe de son piédestal.
📝 Évidemment, une étude ne changera pas le consensus, elle devra être répliquée, mais il s’agit d’une belle avancée de la recherche.
SOURCES
Ahmed, Iftekhar, Rahul Gopinath, Caius Brindescu, Alex Groce and Carlos Jensen. “Can testedness be effectively measured?” Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering (2016): n. pag.
DOIs:
10.1145/2950290.2950324
On the relation of refactorings and software defect prediction 🔗
♻️ Refactoring
🔄 Le refactoring est craint par les managers, qui pensent que les développeurs le pratiquent par pur perfectionnisme, sans preuve de son efficacité. Et pourtant, cela fait plus de 10 ans que la recherche a tranché : après un refactoring, plus de bugs sont corrigés et le temps moyen pour les résoudre diminue !
⚠️ Attention cependant aux faux-refactorings. Le refactoring modifie la structure du code, sans modifier son comportement. C’est cette technique qui a été validée par la recherche. Pas le remaniement à la fourche de larges morceaux de code. Deux moyens sont possibles :
-Refactoring assisté, où l’IDE sécurise les changements, le développeur ne touche pas au code à la main.
-Refactoring libre, sur un code piloté par les tests. Les tests garantissent que le code n’a pas été altéré dans le service rendu.
🪲 Tout autre style de remaniement n’est pas du refactoring, juste du rework. Ce dernier ne bénéficie d’aucune validation par la recherche et pourrait même engendrer plus de bugs que ceux qu’il corrige !
SOURCES :
Jacek Ratzinger, Thomas Sigmund, and Harald C. Gall. 2008. On the relation of refactorings and software defect prediction. In Proceedings of the 2008 international working conference on Mining software repositories (MSR ’08). Association for Computing Machinery, New York, NY, USA, 35–38. DOI:10.1145/1370750.1370759
Miryung Kim, Dongxiang Cai, and Sunghun Kim. 2011. An empirical investigation into the role of API-level refactorings during software evolution. In Proceedings of the 33rd International Conference on Software Engineering (ICSE ’11). Association for Computing Machinery, New York, NY, USA, 151–160. DOI:10.1145/1985793.1985815
1999. Refactoring: improving the design of existing code. Addison-Wesley Longman Publishing Co., Inc., USA.
DOIs:
10.1145/1370750.1370759
·
10.1145/1985793.1985815
Realizing quality improvement through test driven development 🔗
🧪 Tests
🧪 Le papier du jour est peu original : encore un étude sur TDD ! Celle-ci vient confirmer des résultats précédents, tout en démontrant que TDD réduit aussi les défauts des commits suivants, même s’ils ne sont pas réalisés avec TDD.
🐂 Les chercheurs nous avertissent toutefois : TDD cesse d’être efficace quand l’arrêt de cette démarche pousse à ne plus maintenir ou à supprimer des tests. Pour que le cercle vertueux se poursuive tout le long d’un projet, il faut de la persévérance.
⏱️ L’effort n’est pas immense : environ 15% de temps de développement en plus par rapport au même code sans tests. Entre 40% et 80% de défauts en moins selon les projets étudiés. Aucun discipline d’ingénierie ne possède de levier aussi important d’amélioration.
SOURCE
Nagappan, N., Maximilien, E.M., Bhat, T. et al. Realizing quality improvement through test driven development: results and experiences of four industrial teams. Empir Software Eng13, 289–302 (2008). DOI:10.1007/s10664-008-9062-z
DOIs:
10.1007/s10664-008-9062-z
Cohesion and reuse in an object-oriented system 🔗
#️⃣ Façonnage de code
💥Les classes les plus réutilisées dans un même système sont celles ayant le moins de cohésion. C’est la trouvaille de deux chercheurs du Colorado. Corrélation n’est pas causalité, mais ce résultat pourrait signifier :
Hypothèse 🅰️ : Qu’il existe une causalité encore à démontrer entre faible cohésion et réutilisation. Cela paraît assez peu probable.
Hypothèse 🅱️ : que les classes réutilisées partout sont souvent aussi atteintes d’une faible cohésion et inversement. Les God Classes qui polluent la plupart des codebases correspondent à ces deux définitions.
🥼 D’autres expériences seront nécessaires pour valider ou invalider ces hypothèses. Mon instinct penche vers la seconde, mais sait-on jamais.
SOURCE
James M. Bieman and Byung-Kyoo Kang. 1995. Cohesion and reuse in an object-oriented system. SIGSOFT Softw. Eng. Notes 20, SI (Aug. 1995), 259–262. DOI:10.1145/223427.211856
DOIs:
10.1145/223427.211856
J. B. Rainsberger : florilège 🔗
🧪 Tests
·
🧑💼 Management
·
♻️ Refactoring
🏅J’ai parcouru l’ensemble des articles de l’excellent J. B. Rainsberger depuis 2006. J’en ai sélectionné trois que je vous livre comme un florilège et que j’archive pour leur grande valeur.
https://blog.jbrains.ca/permalink/how-test-driven-development-works-and-more
https://blog.jbrains.ca/permalink/refactoring-where-do-i-start
https://blog.jbrains.ca/permalink/the-importance-of-aligning-authority-with-responsibility
Test-driven development with mutation testing – an experimental study 🔗
🧪 Tests
🇵🇱 TDD n’a plus rien à prouver. Une fois les développeurs formés, son usage ne présente presque que des avantages. Bien que moins connus, le mutation testing est tout aussi robuste. Deux chercheurs polonais ont monté une expérience démontrant l’efficacité de l’alliance TDD+Mutation et les synergies entre les 2 méthodes.
🕸️ Ce n’est qu’une première expérience, mais les résultats sont concluants. La mutation permet au développeur de combler les trous laissés par le développeur, pour un coût minime en temps, donc en moyens.
🧑🎓 Un premier papier intéressant qui mériterait d’être reproduit chez des développeurs confirmés, l’étude ne portait que sur des étudiants, qui sont un public posant de nombreux problèmes quand il est recruté pour des études sur TDD.
SOURCES
Roman, Adam & Mnich, Michał. (2021). Test-driven development with mutation testing – an experimental study. Software Quality Journal. 29. 1-38. DOI:10.1007/s11219-020-09534-x.
DOIs:
10.1007/s11219-020-09534-x
Influence of Human Factors in Software Quality and Productivity 🔗
🧑💼 Management
·
🧪 Tests
🧪 Les tests automatisés sont le seule manière abordable de contrôler la qualité d’un logiciel. Le manque de sérieux des managers et des développeurs à ce sujet sont la principale source de sous-performance des équipes de développement.
🧟 Cette conclusion audacieuse nous vient de deux chercheurs qui ont analysé les facteurs humains régissant la productivité et la qualité dans une équipe de développement.
⏰ Du côté des managers, le manque de sérieux est le principal frein à la mise en place de stratégies de test solides. La plupart ont bien été sensibilisés à l’intérêt théorique des tests, mais les passent au second plan lorsqu’une deadline est en vue.
🏫 Les développeurs, eux, manquent de formation. L’école ne leur apprend pas à tester efficacement et aucun employeur n’investit dans ces compétences qui sont chères sur le marché des formations. Ils testent sans méthodes reconnues, s’épuisent à la tâche et finissent par détester les tests.
SOURCE
Sanz, Luis Fernández and Sanjay Misra. “ Influence of Human Factors in Software Quality and Productivity. ” ICCSA (2011). DOI: 10.1007/978-3-642-21934-4_22
DOIs:
10.1007/978-3-642-21934-4_22
Subjective Evaluation of Software Evolvability Using Code Smells 🔗
🦨 Code Smells
🇫🇮 Les odeurs du code sont très peu connues des développeurs, bien moins que les patterns. Pour y remédier, le finlandais Mika Mäntylä propose en 2006 une classification des odeurs du code qui est passée à la postérité. Son but : simplifier pour mieux enseigner.
🗜️De 22 odeurs « classiques » chez Fowler, Mäntylä passe à 7 familles, plus faciles à retenir et à comprendre. L’auteur a résumé sa taxonomie sur GitHub : https://mmantyla.github.io/BadCodeSmellsTaxonomy
👨🏫 C’est un outil précieux pour les formateurs, qui n’ont pas besoin d’entrer dans le détail des odeurs du code pour enseigner la notion.
SOURCES
Mäntylä, M. V. and Lassenius, C. « Subjective Evaluation of Software Evolvability Using Code Smells: An Empirical Study ». Journal of Empirical Software Engineering, vol. 11, no. 3, 2006, pp. 395-431.
M. Fowler and K. Beck, « Bad Smells in Code, » in Refactoring: Improving the Design of Existing Code, Addison-Wesley, 2000, pp. 75-88. DOI: 10.1007/s10664-006-9002-8
DOIs:
10.1007/s10664-006-9002-8
Do Crosscutting Concerns Cause Defects ? 🔗
#️⃣ Façonnage de code
·
👌 Qualité logicielle
💥 Plus une fonctionnalité est éparpillée dans le code, plus elle a de chances d’être défectueuse. Cela vaut aussi pour les Crosscutting Concerns (logs, sécurité, exceptions, etc.). Plus ils sont nombreux et moins ils sont modularisés, plus le code spaghetti guette !
💣 Ce résultat, indépendant du nombre de lignes de code, a été obtenu en 2008 par plusieurs membres de l’organisation IEEE. Ils répondaient à la question « Les Crosscutting Concerns sont-ils source de défauts ? ». La réponse est bien oui, car ils sont difficiles à modulariser, difficiles à tester et sont donc très souvent implémentés avec insouciance par les développeurs, au motif que « ça n’est pas du code métier ».
⚠️ Les Crosscutting Concerns sont partout et ne doivent pas être pris à la légère. Contrairement à la croyance courante, ils sont à confier aux plus expérimentés, pas aux juniors que l’on refuse de mettre sur le code métier.
SOURCE
Marc Eaddy, Thomas Zimmermann, Kaitlin D. Sherwood, Vibhav Garg, Gail C. Murphy, Nachiappan Nagappan, and Alfred V. Aho. 2008. Do Crosscutting Concerns Cause Defects? IEEE Trans. Softw. Eng. 34, 4 (July 2008), 497–515.
DOIs:
10.1109/TSE.2008.36
Deux classifications d'intérêt général 🔗
♻️ Refactoring
·
🦨 Code Smells
🇳🇱 Dans la tradition aristotélicienne, on dit que le propre de l’intelligence et de mettre de l’ordre. C’est bien ce que font Arie van Deursen et Leon Moonen, deux chercheurs néerlandais. Ils nous livrent deux classifications, une sur les odeurs de test, l’autre sur les types de refactorings.
📝 Je vous les livre en l’état, les deux papiers sont courts et clairs.
🦨 Le premier liste 11 odeurs du code courantes et 6 refactorings permettant de les éliminer.
🔙 Le second classe les refactorings de Fowler en 5 groupes selon la rétrocompatibilité entre le code après et avant refactoring.
🗣️ Ces classifications s’ajoutent à notre jargon professionnel, c’est là leur principal intérêt. Un langage commun permet à une profession une plus grande efficience, par l’économie de périphrases hésitantes.
SOURCES
Deursen, Arie & Moonen, Leon & Bergh, Alex & Kok, Gerard. (2001). Refactoring Test Code. DOI:10.5555/869201
Deursen, Arie & Moonen, Leon. (2002). The Video Store Revisited – Thoughts on Refactoring and Testing.
DOIs:
10.5555/869201
Evaluating software degradation through entropy 🔗
📜 Lois du développement
·
👌 Qualité logicielle
🚮 L’entropie est aujourd’hui devenu un terme poli pour désigner la pourriture logicielle. Comme l’entropie thermodynamique, l’entropie du logiciel est une notion ayant une base théorique solide, négligée lors de son passage dans le langage courant. Aujourd’hui, un papier italien de 2001, offrant la première définition rigoureuse connue de ce phénomène.
🕸️ Les 4 chercheurs définissent l’entropie d’un logiciel comme la somme des couplages entre les modules. Ces couplages peuvent être directs ou indirects, structurels (dépendances de compilation) ou cognitifs (charge mentale de devoir penser à A en éditant B).
💣 Plus un code possède d’entropie, plus la portée d’une modification est grande. Nous en avons tous fait l’expérience : modifiez un détail sur un code endetté, vous obtenez des effets de bord imprévus et tout est à revoir.
🏚️ Dans la seconde partie du papier, les chercheurs apportent les premières preuves permettant d’affirmer qu’il s’agit d’une mesure pertinente pour évaluer le vieillissement d’un logiciel, donc la nécessité d’un rajeunissement par le refactoring.
SOURCE
A. Bianchi, D. Caivano, F. Lanubile and G. Visaggio, « Evaluating software degradation through entropy, » Proceedings Seventh International Software Metrics Symposium, 2001, pp. 210-219, doi: 10.1109/METRIC.2001.915530.
DOIs:
10.1109/METRIC.2001.915530
Des limites à l'usage des design patterns 🔗
🧩 Design (Anti-)Patterns
🪄 Après l’enthousiasme des années 1990, les années 2000 furent une période d’intense remise en question des design patterns. Loin d’être la panacée ils se révélaient un boulet pour certains usages et la plupart des bénéfices que l’on en espérait étaient absents. Quoi de plus normal, dans une discipline ayant « No Silver Bullet » pour première loi.
🇳🇴 En 2004, le norvégien Marek Vokac énonce que les patterns seuls n’ont aucun pouvoir face à la complexité intrinsèque de certaines parties du code.
🇮🇹 En 2009, 3 italiens découvrent que la combinaison de certains patterns avec la présence de crosscutting concerns (logs, sécurité, cache, etc.) augmente le nombre de défauts, car ces patterns ont tendance à éparpiller la responsabilité.
➕ Aucun de ces chercheurs n’a remis en question le bénéfice net de l’usage de patterns. Tous appellent en revanche à la prudence : ils ne conviennent simplement pas à toutes les situations. Ce serait trop facile, sinon. Notre métier est immensément complexe. C’est une bonne nouvelle pour son avenir.
SOURCES
M. Vokac, « Defect frequency and design patterns: an empirical study of industrial code, » in IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 904-917, Dec. 2004, doi: 10.1109/TSE.2004.99.
Aversano, L. & Cerulo, Luigi & Di Penta, Massimiliano. (2009). Relationship between design patterns defects and crosscutting concern scattering degree: An empirical study. Software, IET. 3. 395 – 409. 10.1049/iet-sen.2008.0105.
Brooks, Frederick P. (1986). « No Silver Bullet—Essence and Accident in Software Engineering ». Proceedings of the IFIP Tenth World Computing Conference: 1069–1076.
DOIs:
10.1109/TSE.2004.99
·
10.1049/iet-sen.2008.0105
Sustainable Software Development through Overlapping Pair Rotation 🔗
🧑💼 Management
·
🤝 Pair Programming
👥 Aujourd’hui, deux papiers, dont l’un est devenu un classique, qui listent les bénéfices, attendus ou plus surprenants, du pair programming. Certains sont peu connus et justifient largement les 15% de surcoût observé par rapport à une équipe classique (et non 100%, comme le pense la croyance managériale).
- Le taux de défauts en production est bien plus bas.
- Le pair programming coût moins cher que les code review à résultat égal.
- Les solutions trouvées sont meilleures et plus simples, donc plus maintenables.
- La vélocité d’une paire est plus élevée que celle d’un développeur seul.
- Les développeurs se sentent mieux à leur poste.
- L’apprentissage est plus rapide, même un expert apprendra au contact d’un novice (et inversement, bien entendu)
📚 Enfin, bien moins connu, le pair programming augmente la résilience de l’équipe sans nécessiter des camions entiers de documentation, très coûteuse à maintenir et empiriquement jamais à jour.
♻️ Sedano, Ralph et Péraire appellent cette propriété « Développement durable du logiciel ». En travaillant par paires a minima tournantes, les développeurs partagent la connaissance du code « naturellement » et l’ensemble de l’équipe finit par obtenir la responsabilité collective de l’ensemble du code au bout de quelques mois.
Pour obtenir cette propriété, la rotation des paires doit être fréquente ! Des paires fixes et affinitaires ne fonctionnent pas et créent des silos. A minima, les paires doivent se chevaucher, mais la meilleure technique consiste à « polliniser » le savoir en s’assurant que toutes les paires possibles ont été pratiquées sur une itération par exemple.
SOURCES
Todd Sedano, Paul Ralph, and Cécile Péraire. 2016. Sustainable Software Development through Overlapping Pair Rotation. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM ’16). Association for Computing Machinery, New York, NY, USA, Article 19, 1–10. DOI: 10.1145/2961111.2962590
Alistair Cockburn and Laurie Williams. 2001. The costs and benefits of pair programming. Extreme programming examined. Addison-Wesley Longman Publishing Co., Inc., USA, 223–243. DOI: 10.5555/377517.377531
DOIs:
10.1145/2961111.2962590
·
10.5555/377517.377531
A design methodology for reliable software systems 🔗
📐 Architecture
·
#️⃣ Façonnage de code
👵 Encore un papier de Barbara Liskov. J’ai déjà parlé d’elle dans un post précédent (lien à la fin). Dans ce papier de 1972 extrêmement actuel, elle nous explique comment produire des logiciels fiables, car testés, donc testables. Le raisonnement est long, mais rémunérateur pour qui le suit jusqu’au bout.
🐛 Elle constate d’abord que le débogage intensif n’a jamais rien résolu. Il faut des tests automatisés couvrant l’ensemble des cas utiles.
🧮 Elle ajoute qu’il serait trop complexe d’obtenir des preuves formelles qu’un logiciel complexe fonctionne, à cause du nombre trop grand d’états. Des preuves informelles peuvent suffire à condition de structurer le programmes correctement, afin qu’ils soient le plus testables et prévisibles possibles.
✔️ La testabilité est donc, pour Barbara Liskov, une question de design.
✂️ L’idée de découper le programme en modules est bonne, mais insuffisante. Un découpage bancal ajoute plus de complexité qu’il n’en masque.
2️⃣ Elle donne deux règles, tirées des travaux de Dijkstra et Parnas, déjà évoqués ici :
👉 S’appuyer sur le principes des machines virtuelles de Parnas, où chaque niveau d’abstraction s’appuie sur celui immédiatement en dessous pour réaliser des oéprations plus complexes et proches du métier.
👉 Faire de la programmation structurée, sans goto donc. L’abolition du goto qui est évidente pour nous en 2021 était encore une bataille rangée en 1972.
🔪 La combinaison de ces deux règles permet une indépendance des modules par le découplage.
✨ On obtient ainsi un programme qu’il est possible de tester comme suit :
👉 Chaque module est individuellement testé par un ensemble de tests X.
👉 Chaque assemblage de modules complet est testé par un ensemble de tests Y.
➕ Grâce au design qu’elle recommande, le nombre de cas de tests nécessaires n’est pas X*Y, mais bien X+Y pour atteindre une couverture satisfaisante, ce qui est à la portée des développeurs.
SOURCE
Liskov, Barbara. “A design methodology for reliable software systems.” AFIPS ’72 (Fall, part I) (1972). DOI: 10.1145/1479992.1480018
DOIs:
10.1145/1479992.1480018
Les standards de code spécifiques sont bénéfiques aux projets 🔗
🧮 Méthodes de développement
🍟 Cathal Boogerd et Leon Moonen nous ont déjà montré que les standards de code ne sont pas efficaces pour diminuer le nombre de bugs et peuvent même l’augmenter. Une équipe de l’INRIA Lille prolonge la réflexion en montrant que les standards du code spécifiques au projet, écrits par les développeurs, sont bien plus efficaces que les règles génériques.
⚠️C’est un outil largement sous-utilisé et même inconnu. Pour la majorité des développeurs, les alertes de leur compilateur ou de leur IDE sont presque une fatalité, ils ignorent qu’il est possible sur la plupart des langages de les augmenter de règles faites maison.
SOURCES
Andre Hora, Nicolas Anquetil, Stéphane Ducasse, Simon Allier. Domain Specific Warnings: Are They Any Better?. IEEE International Conference on Software Maintenance, Sep 2012, Riva del Garda, Italy. pp.441-450. DOI: 10.1109/ICSM.2012.6405305
Boogerd, Cathal & Moonen, Leon. (2008). Assessing the Value of Coding Standards: An Empirical Study. IEEE International Conference on Software Maintenance, ICSM. 277 – 286. 10.1109/ICSM.2008.4658076.
DOIs:
10.1109/ICSM.2008.4658076
·
10.1109/ICSM.2012.6405305
Assessing the Value of Coding Standards: An Empirical Study 🔗
🧮 Méthodes de développement
📜 Quelle équipe n’a pas défini de standards de code ? C’est un lieu commun qu’ils permettent l’harmonie dans l’équipe et la protection contre les bugs. Mais en sommes nous sûrs ? Cathal Boogerd et Leon Moonen mettent un coup de pied dans la fourmilière : ces standards n’empêcheraient pas les bugs et pourraient même en créer !
🪲 Le raisonnement est le suivant : toute modification risque statistiquement d’introduire un bug. Une modification qui n’apporte aucun bénéfice obéit aussi à cette règle, elle est donc contre-productive. Or la majorité des standards de code est inutile (60/72 parmi les règles étudiées par l’équipe) car ne correspondant à rien de plus qu’une vague coutume d’équipe.
🔎 Pour les chercheurs, toute règle qui ne naît pas d’un problème identifié cause plus de bugs qu’elle n’en résout. Ils recommandent donc la plus grande prudence lors de l’adoption de celle-ci.
La révision régulière de ces règles afin de supprimer celles qui sont obsolètes pourrait également présenter un intérêt.
SOURCE
Boogerd, Cathal & Moonen, Leon. (2008). Assessing the Value of Coding Standards: An Empirical Study. IEEE International Conference on Software Maintenance, ICSM. 277 – 286. 10.1109/ICSM.2008.4658076.
DOIs:
10.1109/ICSM.2008.4658076
Test-driven development as a defect-reduction practice 🔗
🧪 Tests
🏁 Il y a des quantités de papiers expérimentaux sur TDD. Ils mériteraient une synthèse, mais en attendant je vous en livre un de plus : chez IBM, une équipe expérimentée travaillant en mode Test-Last a été comparée à une équipe de novices pratiquant TDD. Les résultats sont bluffants.
🐛 40% de nouveaux bugs en moins sur le même projet pour l’équipe TDD. Un impact minimal sur la productivité. Des tests jugés plus maintenables, qualitatifs et réutilisables.
☑️ Contrairement à beaucoup d’études qui comparent assez fallacieusement TDD à l’absence de tests, celle-ci a le mérite de comparer TDD à Test-Last. L’étude ne dit pas comment les développeurs de l’équipe TDD ont été formés, ni leur niveau précédant la formation.
✔️ Sous réserve que l’investissement, que l’on sait conséquent, soit fait, TDD semble apporter des bénéfices démontrés.
SOURCE
L. Williams, E. M. Maximilien and M. Vouk, « Test-driven development as a defect-reduction practice, » 14th International Symposium on Software Reliability Engineering, 2003. ISSRE 2003., 2003, pp. 34-45, doi: 10.1109/ISSRE.2003.1251029.
DOIs:
10.1109/ISSRE.2003.1251029
Effet tiroir et science du logiciel 🔗
🧩 Design (Anti-)Patterns
·
🥼 Épistémologie
🕳️ Aujourd’hui trois papiers sur le même sujet : est-ce que la participation à un design pattern rend une classe plus susceptible de changer ? Aucune réponse claire ne sera donnée, mais je vais rebondir en parlant d’effet tiroir, la plaie de la recherche.
👌 Aucun de ces trois papiers n’a de résultats significatifs dans un sens ou dans l’autre. Bref, on ne sait pas et les facteurs de confusion sont sans doute trop grands pour conclure. Pourtant les chercheurs à l’origine de ces papiers ont décidé de les publier et nous devons les y encourager.
🚮 On désigne sous le nom d’effet tiroir un biais connu dans la recherche : il est plus gratifiant de publier des résultats que de publier une absence de résultats. Les papiers présentant peu ou pas de résultats ont donc plus tendance à rester au fond d’un tiroir, alors qu’ils sont nécessaires à l’avancée de la recherche.
✔️ Ils indiquent aux autres chercheurs ce qui a déjà été tenté, afin qu’ils essaient différemment de trouver la réponse.
✔️ Ils indiquent aux praticiens que sur une question donnée, rien n’est tranché et qu’il vaut mieux adopter une posture prudente.
✔️ Ils permettent aux auteurs de méta-analyses de tempérer les résultats positifs et négatifs éventuels avec la part de papiers n’ayant rien trouvé, fiabilisant largement les résultats.
🏅 L’effet tiroir est une vrai problème en recherche, surtout par le manque de chiffres pour le caractériser. Nous avons déjà les IgNobel, il manquerait un prix pour récompenser les chercheurs qui ont déployé le plus d’efforts pour ne rien trouver.
SOURCES
Aversano, L. & Canfora, Gerardo & Cerulo, Luigi & Grosso, Concettina & Di Penta, Massimiliano. (2007). An empirical study on the evolution of design patterns. 385-394. 10.1145/1287624.1287680.
Bieman, James & Straw, Greg & Wang, Huxia & Munger, P. & Alexander, Roger. (2003). Design Patterns and Change Proneness: An Examination of Five Evolving Systems.. IEEE METRICS. 40-49. 10.1109/METRIC.2003.1232454.
M. Di Penta, L. Cerulo, Y. -G. Gueheneuc and G. Antoniol, « An empirical study of the relationships between design pattern roles and class change proneness, » 2008 IEEE International Conference on Software Maintenance, 2008, pp. 217-226, doi: 10.1109/ICSM.2008.4658070.
DOIs:
10.1145/1287624.1287680
·
10.1109/METRIC.2003.1232454
·
10.1109/ICSM.2008.4658070
Why Don't They Practice What We Preach ? 🔗
🧠 Psychologie
·
🧑💼 Management
🦥 Pourquoi les développeurs n’adoptent pas les bonnes pratiques ? Je crois la question elle est vite répondue, parce qu’ils sont réfractaires au changement ! Justement non, et Watts Humphrey, « le père de la qualité », qui a dédié sa vie à améliorer nos pratiques, nous livre son ressenti sur la question.
🐂 Sans dédouaner ces rares professionnels butés qui ne veulent absolument pas changer de pratiques, il désigne plusieurs mécanismes qui empêchent la majorité des développeurs de s’améliorer en continu.
🏫 En haut de la liste, le système éducatif (facs et écoles) qui ne donne pas aux étudiants les bonnes clés. Les développeurs n’apprennent pas à mesurer la qualité de leur code, étant notés sur les résultats de leurs projets, non sur la qualité de leur design.
🔥Ensuite, l’entreprise, trop focalisée sur les urgence quotidiennes pour investir dans des formations longues qui cassent le rythme de production. Humphrey note qu’un développeur sous pression tend à privilégier ce qu’il sait faire au détriment des urgences. Pour la majorité peu formée, cela signifie la production en masse de code médiocre. Il faut les épaules d’un maître pour garder un cap sous pression. C’est donc un investissement payant, mais coûteux.
⏳ Enfin, la résistance au changement n’est pas négligeable. Plus un développeur a d’expérience avec une pratique donnée, fut elle mauvaise, plus le niveau de preuve nécessaire pour le convaincre de changer est grand, surtout s’il ne possède aucun exemple autour de lui. L’atteindre nécessite un accompagnement pratique, donc de le retirer de la production. C’est sans issue.
✔️ Humphrey propose 2 leviers de changement.
👉 Former dès le berceau est le plus facile. Les étudiants sont des tabula rasa qu’il suffit de former correctement. Encore faut-il vaincre les résistances au changement de leurs professeurs.
👉 Adopter une stratégie du temps long en entreprise. La qualité d’aujourd’hui est la maintenabilité, donc la rentabilité de demain. Former ses développeurs réduit le turnover et augmente la qualité du code. Hélas c’est un gros investissement qu’une entreprise déjà sous l’eau ne peut se permettre. Le recrutement d’un lead dev charismatique, au moins le temps d’insuffler les bonnes pratiques aux autres développeurs, est une option sans doute intéressante.
SOURCES
Watts S. Humphrey, Why Don’t They Practice What We Preach? 2009, Software Engineering Institute. DOI: 10.1023/A:1018997029222
DOIs:
10.1023/A:1018997029222
When Does a Refactoring Induce Bugs ? An Empirical Study 🔗
♻️ Refactoring
🛠️ Contrairement à un mythe tenace, le refactoring, même automatisé par l’IDE, présente des risques d’introduire des bugs ! La seule parade est un jeu de tests de qualité.
🤌 6 chercheurs italiens ont sorti en 2012 un papier à ce sujet. Tous les refactoring ne sont pas égaux. Renommer est souvent anodin. Manipuler les hiérarchie est le plus glissant, jusqu’à 40% des actions de type Pull Up Method et Extract Subclass introduisent des bugs, contre 15% pour le refactoring en général.
✔️ On ne répétera jamais assez l’importance des tests en logiciel, il sont le filet de sécurité qui permet au développeur de remanier son travail jusqu’à le rendre satisfaisant.
SOURCE :
M. Fowler, K. Beck, J. Brant, W. Opdyke, D. Roberts, Refactoring : Improving the Design of Existing Code. Addison Wesley, 1999
G. Bavota, B. De Carluccio, A. De Lucia, M. Di Penta, R. Oliveto and O. Strollo, « When Does a Refactoring Induce Bugs? An Empirical Study, » 2012 IEEE 12th International Working Conference on Source Code Analysis and Manipulation, 2012, pp. 104-113, doi: 10.1109/SCAM.2012.20.
DOIs:
10.1109/SCAM.2012.20
When and Why Your Code Starts to Smell Bad (and Whether the Smells Go Away) 🔗
🧮 Méthodes de développement
·
♻️ Refactoring
·
🦨 Code Smells
🦨 En 2017, plusieurs chercheurs emmenés par Michele Tufano ont fait une découverte : les odeurs du code (code smells) ne sont pas majoritairement introduits lors du refactoring, mais bien présents dès le départ dans un code. La pression mise sur les développeurs en est la cause principale.
📙 Cela va contre l’affirmation de Fowler dans son célèbre Refactoring, qui pensait que la majorité des odeurs apparaissent lors de l’évolution du code.
🔍 Les chercheurs notent toutefois que l’analyse statique du code élimine une grande partie des odeurs. Elle devrait donc être lancée avant chaque commit.
SOURCES
Tufano, Michele et al. “When and Why Your Code Starts to Smell Bad (and Whether the Smells Go Away).” IEEE Transactions on Software Engineering 43 (2017): 1063-1088. DOI: 10.1109/TSE.2017.2653105
DOIs:
10.1109/TSE.2017.2653105
What is DevOps ? A Systematic Mapping Study on Definitions and Practices 🔗
🧮 Méthodes de développement
Qu’est-ce qu’un DevOps et en suis-je ? C’est la question que je me posais régulièrement avant de tomber sur la revue de littérature de Jabbari, bin Ali, Petersen et Tanveer. Ils ont analysé une cinquantaine de papiers pour donner une définition précise du sujet, que je traduis ici.
« DevOps est une méthodologie de développement visant à combler le fossé entre développement et opérations, mettant l’emphase sur la communication et la collaboration, l’intégration continue, l’assurance qualité et la livraison avec déploiement automatisé utilisant un jeu de pratiques de développement »
Si cette phrase définit DevOps, alors j’en suis ! Un bon développeur sait livrer, avec ou sans DevOps.
En revanche, si pour vous DevOps est un moyen d’économiser un administrateur en chargeant le développeur de missions qui ne sont pas les siennes, ce n’est pas DevOps et je ne m’inscris pas dans cette démarche.
SOURCE :
Ramtin Jabbari, Nauman bin Ali, Kai Petersen, and Binish Tanveer. 2016. What is DevOps? A Systematic Mapping Study on Definitions and Practices. In Proceedings of the Scientific Workshop Proceedings of XP2016 (XP ’16 Workshops). Association for Computing Machinery, New York, NY, USA, Article 12, 1–11. DOI: 10.1145/2962695.2962707
DOIs:
10.1145/2962695.2962707
Towards an Anatomy of Software Craftsmanship 🔗
🏺 Artisanat
·
🧑💼 Management
·
🧮 Méthodes de développement
·
✊ Corporatisme
🛠️ Je suis un artisan du logiciel. Mais qu’est-ce que cela signifie ? 4 chercheurs, emmenés par Anders Sundelin, ont publié en septembre dernier un papier tentant de cerner le concept. Le triptyque de Sandro Mancuso pourrait résumer leurs recherches : Professionalisme, pragmatisme, fierté.
3️⃣ Les conclusions du papier peuvent être organisées en 3 parties : les valeurs, les pratiques et les organisations.
🧭 Les valeurs sont le cœur de l’identité des développeurs qui se rattachent à cette école. La responsabilité et le professionnalisme ressortent en premier : pour les artisans eux-mêmes, faire correctement leur métier n’est pas négociable. Chaque développeur doit se sentir responsable de l’état de l’ensemble du code et en tirer une certaine fierté. L’artisan doit transparence et honnêteté à son client quant à l’état du code, via la mise en évidence de la dette technique, par exemple. C’est aussi un refus du découpage industriel des tâches dans le développement. Pour les plus radicaux, l’architecte doit disparaître au profit d’une réflexion collégiale entre équipes, mais la plupart s’accordent sur son implication forte au sein des équipes de développement « les mains dans le cambouis ».
🎛️ Les pratiques forment des règles de l’art. Elles sont composées d’un cœur de techniques anciennes et éprouvées, issues en majorité d’Extreme Programming (XP), auxquelles s’ajoutent des bonnes pratiques tenant lieu de lois du logiciel, comme les principes SOLID. On y retrouve la valorisation de la simplicité, ATDD, la méfiance envers toute documentation qui ne serait pas engendrée par du code et l’accent mis sur la livraison et le feedback.
🕸️ Les organisations procèdent des valeurs et des pratiques. On y retrouve des conférences comme Socrates, SCNA ou NewCrafts, bâties en réaction à ce qu’est devenue l’agilité, buzzword pour managers ayant ses coachs et ses certifications hors de prix, bien éloignées des préoccupations des développeurs. Les coding dojo et les katas sont un marqueur fort, tant en entreprise que dans des tiers-lieux servant de rassemblement à de véritables communautés néo-corporatives*, unies par une culture de l’apprentissage permanent. Les auteurs rejoignent les conclusions de Benjamin Tainturier et Emanuelle Duez, qui ont clairement réalisé leur enquête, à dessein ou non, auprès d’artisans.
* le terme n’est pas dans le papier.
SOURCES
Anders Sundelin, Javier Gonzalez-huerta, Krzysztof Wnuk, and Tony Gorschek. 2021. Towards an Anatomy of Software Craftsmanship. ACM Trans. Softw. Eng. Methodol. 31, 1, Article 6 (January 2022), 49 pages. DOI:10.1145/3468504
Sandro Mancuso, The Software Craftsman : Professionalism, Pragmatism, Pride. 2014. Pearson. ISBN:978-0134052502
Benjamin Tainturier, Emmanuelle Duez, The Boson Project. Décoder les développeurs. Enquête sur une profession à l’avant-garde. 2017. Eyrolles.
DOIs:
10.1145/3468504
Towards a Mapping of Software Technical Debt onto Testware 🔗
🦨 Code Smells
·
🧪 Tests
🦨 Vous pensiez vos tests exempts d’odeurs du code ? Deux chercheurs suédois piétinent vos douces illusions.
Non seulement les tests sont du code, donc sujets à des variantes des odeurs et antipatterns qui affaiblissent les logiciels, mais ils ont en plus leurs odeurs spécifiques.
⛓️ Tout code est une responsabilité (liability). Pas seulement le code de production. Le code le plus robuste est celui qui n’existe pas, ce qui vaut aussi pour les tests. Le meilleur code est toujours celui qui offre le plus grand résultat avec le moins de lignes de codes, tests inclus.
📚 Dijkstra disait qu’un logiciel n’est utile que si la masse de documentation nécessaire à l’opérer est inférieure à la taille de ses sources. Il n’est pas aberrant de penser la même chose pour les tests.
SOURCES
E. Alégroth and J. Gonzalez-Huerta, « Towards a Mapping of Software Technical Debt onto Testware, » 2017 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA), 2017, pp. 404-411, doi: 10.1109/SEAA.2017.65.
Edsger Dijkstra, On the Reliability of Programs
https://wiki.c2.com/?SoftwareAsLiability
DOIs:
10.1109/SEAA.2017.65
The role of knowledge in software development 🔗
🧠 Psychologie
🧠 Comment la psychologie voit le savoir et quel est son rôle dans le développement de logiciels ? Le professeur Robillard le vulgarise avec brio dans un papier qui a plus de 20 ans, mais qui reste une merveille.
Pierre N. Robillard. 1999. The role of knowledge in software development. Commun. ACM 42, 1 (Jan. 1999), 87–92. DOI:10.1145/291469.291476
DOIs:
10.1145/291469.291476
The chaos of software development 🔗
🧮 Méthodes de développement
·
📜 Lois du développement
·
♻️ Refactoring
⚛️ La complexité d’un programme est-elle liée à celle de la méthode utilisée pour le développer ? Oui d’après un papier de deux chercheurs canadiens en 2003. Ils ont utilisé une application de l’entropie de Shannon afin d’évaluer la corrélation entre ces deux variables.
🔊 Plus la méthode de gestion de projet utilisée complique la tâche des développeurs, moins le code sera simple (donc maintenable) à la fin du processus. Cela peut s’expliquer de différentes manières :
❌ Le bruit, à savoir toutes les information confuses ou non-pertinentes que les développeurs doivent trier pour faire leur métier
❌ L’incertitude, qui provoque des redéveloppements évitables.
✔️ Le papier valide deux éléments des Software Wastes de Todd Sedano, qui est ultérieur.
⛏️ Comment inverser la vapeur si c’est déjà trop tard pour votre projet ? Les auteurs donnent toujours la même réponse : le refactoring. C’est un consensus souvent exprimé dans l’ensemble des papiers que j’ai pu lire, décidément.
SOURCES
Hassan, A. and Richard C. Holt. “The chaos of software development.” Sixth International Workshop on Principles of Software Evolution, 2003. Proceedings. (2003): 84-94. DOI: 10.5555/942803.943729
Sedano, Todd & Ralph, Paul & Péraire, Cécile. (2017). Software Development Waste. DOI: 10.1109/ICSE.2017.20
DOIs:
10.5555/942803.943729
Technical decision-making in startups and its impact on growth and technical debt 🔗
🧑💼 Management
·
🧮 Méthodes de développement
On sait peu de choses des facteurs de réussite des startups sur le champ du logiciel, car le domaine est peu étudié. Cependant, Carl Hultberg, étudiant en management industriel nous livre une excellente synthèse du peu que nous savons.
Les généralités sont simples et intuitives : 📈 satisfaire ses utilisateurs et 📉 juguler la dette technique.
Pour cela, deux pratiques sont recommandées.
👉 Créer une équipe produit au profil technico-fonctionnel, très proche des développeurs. La plupart des méthodes agiles recommandent même un Product Owner faisant partie de l’équipe de développement.
👉Toujours ramener les features à l’essentiel. Pas de superflu, moins de code. Moins de code, moins de dette.
Ces conclusions sont à augmenter avec ce que nous savons de la dette technique, que l’auteur n’a pas la formation pour repérer : tester son code pour permettre un refactoring fréquent, seul remède efficace contre la dette.
Source : Hultberg C., Technical decision-making in startups and its impact on growth and technical debt
Rule-based Assessment of Test Quality 🔗
🦨 Code Smells
·
🧪 Tests
·
🧩 Design (Anti-)Patterns
🇫🇷🇨🇭 Comment évaluer la qualité d’un jeu de tests ? Le coverage ne suffit pas. Les tests de mutation n’attrapent que les erreurs triviales. Dans un papier de 2007, une équipe Franco-Suisse démontre que les odeurs des tests (Test Smells) sont un outil pertinent pour repérer les mauvais tests.
🦨 Les Test Smells sont les cousins des Code Smells, qui matérialisent des problèmes de qualité potentiels dans un code. Moins connus, ils n’en ont pas moins été jugés efficaces par la recherche et ce papier l’appuie. La plupart des Test Smells sont attachés à un Antipattern de test. Ainsi les odeurs peuvent aider à découvrir qu’un test est trop long, obscur ou erratique. Les chercheurs ont ainsi identifié 27 odeurs reliés à un ou plusieurs antipatterns.
✔️ Leur recherche visait à créer un outil automatisé de détection des tests. Ce faisant ils nous livrent des conclusions intéressantes en tant que praticiens :
👉 Les Test Smells sont fréquents et nettement reliés aux antipatterns.
👉 Plus un développeur écrit de tests, meilleurs ils sont.
Leur outil mériterait d’être adapté dans nos langages, mais rien ne remplacera jamais l’oeil du praticien entraîné !
SOURCE
Reichhart, Stefan, Tudor Gîrba and Stéphane Ducasse. “Rule-based Assessment of Test Quality.” J. Object Technol. 6 (2007): 231-251. DOI:10.5381/jot.2007.6.9.a12
DOIs:
10.5381/jot.2007.6.9.a12
Recovery, redemption, and extreme programming 🔗
🧮 Méthodes de développement
Extreme Programming peut (aussi) redresser des projets en perdition à condition de ne pas avoir une approche dogmatique et d’accepter des sacrifices. C’est l’essence du témoignage déjà ancien de Peter Schuh.
Le paysage a peu changé, d’après mon expérience en ESN ou en tant que freelance. Ce papier est toujours actuel.
P. Schuh, “Recovery, redemption, and extreme programming,” in IEEE Software, vol. 18, no. 6, pp. 34-41, Nov.-Dec. 2001, doi: 10.1109/52.965800.
DOIs:
10.1109/52.965800
Programming with abstract data types 🔗
💾 Histoire de l'informatique
·
🔣 Science des Langages
·
#️⃣ Façonnage de code
👵 Tout développeur connaît les principes SOLID. Peu connaissent l’auteur du troisième : le Principe de Substitution de Barbara Liskov. Cette grande dame inventa le premier langage de programmation supportant l’abstraction. Autant dire qu’elle a pavé la voie aux langages de haut-niveau modernes.
📦 Son article de 1974 « Programming with abstract data types » est devenu un classique. Elle y détaille un paradigme de programmation, héritier de la programmation structurée de Dijkstra, dans lequel le développeur n’utilise pas directement les types fournis par le système. Ceux-ci sont encapsulés dans des types de plus haut-niveau, ne laissant filtrer que les détails pertinents du niveau précédent.
🎰 Ces types sont définis par les opérations que l’on peut réaliser sur eux (et non pas sur les données qu’ils contiennent !). Elle ne parle pas d’objet ou d’interface, concepts encore balbutiants à l’époque (Alan Kay travaille encore sur Smalltalk), mais l’idée est décidément dans l’air du temps.
3️⃣ Son paradigme présente trois énormes avantages, déjà identifiés dans le papier :
✔️ Protéger le développeur contre les erreurs d’inattention (additionner un int et un char par exemple).
✔️ Réduire la charge mentale* du développeur, qui peut se concentrer sur l’espace du problème sans se soucier des détails d’implémentation. Les types sont semblables aux oeillères des animaux de trait.
✔️ Rendre le programme plus facile à tester* : le jeu de tests* est divisé en deux parties indépendantes, l’une vérifiant l’implémentation, l’autre que l’abstraction est appelée correctement. Cette seconde partie doit ignorer tout de l’implémentation.
📝 Si la manière de concevoir des langages a vieilli (et donc la seconde partie du papier de Liskov), les principes fondamentaux sont toujours d’actualité, je ne peux qu’en conseiller la lecture.
* Ces termes n’existaient pas à l’époque
SOURCE
Liskov, Barbara and Stephen N. Zilles. “Programming with abstract data types.” SIGPLAN Notices 9 (1974): 50-59. DOI: 10.1145/800233.807045
DOIs:
10.1145/800233.807045
Organizing Programs Without Classes 🔗
🔣 Science des Langages
·
💾 Histoire de l'informatique
😱 En 1986 naît la programmation orientée prototype, célèbre grâce à JavaScript. Paradoxalement, ce paradigme est relativement inconnu, voire fui par les développeurs JS qui préfèrent oublier son existence ! Quel échec pour celui qui était vu comme révolutionnaire en 1991, au sens littéral du terme : il visait l’abolition des classes.
🤳 Aujourd’hui un papier historique de 4 chercheurs de Stanford, dont David Ungar, le créateur de Self, premier langage orienté prototype.
🗑️ Les auteurs y défendent une thèse osée : les classes sont inutiles à la programmation orientée objet, voire même gênantes. Tout ce que font les classes peut être fait plus simplement par la copie de prototypes : héritage, composition, encapsulation, polymorphisme. Mieux, les prototypes apportent l’héritage dynamique et la modification du comportement hérité par les enfants.
🕵️ L’intérêt de ce papier est surtout historique, 30 ans après, un bilan s’impose :
❌ Les classes sont bien vivantes et les pratiques actuelles tendent vers des systèmes de typage de plus en plus forts.
❌ JavaScript vit sans assumer son paradigme historique (cocasse pour quelque chose de révolutionnaire), en témoigne le succès des diverses surcouches et frameworks (NodeJS, TypeScript, etc.).
❌ L’héritage dynamique n’a pas trouvé d’usage.
❌ La modification du comportement hérité est vue comme un antipattern en Orienté Objet car il brouille la compréhension.
❌ En dehors de LUA, tous les autres langages orienté prototype sont tombés dans l’oubli.
✔️ Le principal héritage de l’orienté prototype est l’idée de traits, présents dans la plupart des langages OO de nos jours, sous diverses formes.
✔️ La notion de délégué pourrait venir de l’orienté prototype mais son origine est plus floue.
🛑 Bien qu’élégante sur le papier, l’idée des langages a prototypes a souffert de sa courbe d’apprentissage exécrable, totalement incompatible avec la cible de son principal porte-drapeau : JS, le langage des débutants par excellence. Peu sont même au courant du paradigme auquel obéit ce langage. La plupart ont adopté les codes de la programmation fonctionnelle ou impérative lorsqu’ils programment en JS.
SOURCE
Chambers, Craig & Ungar, David & Chang, Bay-Wei & Hölzle, Urs. (1991). Organizing Programs Without Classes.. Lisp and Symbolic Computation. 4. 223-242. 10.1007/BF01806107.
DOIs:
10.1007/BF01806107
On the reliability of programs 🔗
💾 Histoire de l'informatique
·
👌 Qualité logicielle
Notre profession a peu de mémoire, nous avons oublié Lehman, Royce ou Wirth et de Dijkstra, il ne reste que des citations.
« Les tests peuvent être utilisés pour démontrer la présence de bugs, jamais leur absence. »
« Tout morceau de code ou programme complet n’est un outil utile que si la documentation nécessaire à l’utilisateur est plus courte que le code. »
« Notre culture a déjà pour tradition séculaire une discipline intellectuelle dont le but premier est de structurer efficacement une complexité autrement ingérable. Les Mathématiques. »
Ces trois éclairs de génie sont tous issus du même papier (en anglais), que je vous invite à lire : On The Reliability Of Programs.
SOURCE
Dijkstra E., On the Reliability of Programs (EWD303)
On the effects of programming and testing skills on external quality and productivity in a test-driven development context 🔗
🧮 Méthodes de développement
·
🧪 Tests
·
🧑💼 Management
👶 « TDD c’est pour les devs chevronnés, j’ai une plâtrée de juniors, je préfère oublier. »
💪 « Le seul moyen de faire de la qualité c’est d’avoir des vieux devs barbus. »
Si avec une seule étude on débunkait tout ça ?
📐L’introduction est peut-être un peu putaclic, mais d’après les résultats qu’ont obtenu 3 chercheurs finlandais, les compétences seules d’un développeur n’ont pas de lien avec la qualité des logiciels qu’il produit. J’émets l’hypothèse que le contexte et les pratiques sont le facteur principal.
❓ Un junior peut donc produire un code de meilleure qualité qu’un senior, s’il est dans un bon environnement et respecte des pratiques reconnues. Où est le piège ?
👴 L’étude montre également que les compétences sont fortement corrélées avec la productivité d’un développeur. A qualité égale, le senior est plus performant.
📈 Et TDD dans tout ça ? Les chercheurs montrent une hausse de productivité chez tous les développeurs (ce qui vient ajouter un papier à ce débat très vif qui ne sera clos que par une méta-étude solide). Cette hausse est plus importante chez les développeurs ayant déjà de la pratique.
✔️ Cela colle avec mon expérience comme enseignant, TDD est compatible avec des étudiants. Cela ne signifie pas que ce soit simple à apprendre, mais que la hausse de productivité pourrait intervenir plus tôt que l’on ne croît.
Note de fin : l’étude comporte des biais, comme tout ce que je présente. Lisez pour vous faire votre propre idée.
SOURCE
Davide Fucci, Burak Turhan, and Markku Oivo. 2015. On the effects of programming and testing skills on external quality and productivity in a test-driven development context. In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering (EASE ’15). Association for Computing Machinery, New York, NY, USA, Article 25, 1–6. DOI:10.1145/2745802.2745826
DOIs:
10.1145/2745802.2745826
On the Criteria To Be Used in Decomposing Systems into Modules 🔗
📐 Architecture
·
#️⃣ Façonnage de code
🎺 « Si les développeurs chantaient des hymnes, le plus populaire serait l’hymne de la modularité » c’est ainsi que David Parnas commence son article « On the Criteria to be used in Decomposing Systems into Modules » en 1971. Un article que toute personne tentée par les microservices doit lire.
✂️ Après une démonstration, il conclut en priant les développeurs d’arrêter de découper leurs programmes à l’avance sur la base d’un organigramme. Cela ne fonctionne pas mieux en 2021 qu’en 1971. Il encourage plutôt à commencer par un monolithe, qui sera découpé au besoin lorsqu’une décision de design importante sera prise.
🔀 Cette décision sera masquée au programme principal, ce qui permet de n’avoir qu’un module à changer si cette décision s’avérait mauvaise et qu’il fallait prendre une autre voie.
SOURCE :
Parnas, David. (1972). On the Criteria To Be Used in Decomposing Systems into Modules. Communications of the ACM. 15. 1053-. 10.1145/361598.361623.
DOIs:
10.1145/361598.361623
La cybernétique à l’aune des sciences cognitives : une erreur scientifique ? 🔗
🥼 Épistémologie
·
💾 Histoire de l'informatique
🏛️ C’est devenu un lieu commun au sein des sciences cognitives, de critiquer la cybernétique, dont la discipline est pourtant issue.
Marvin Minsky, un des fondateurs de l’IA, comme Hubert Dreyfus, son vieil adversaire s’accordent sur les fruits anecdotiques de la « science des systèmes auto-organisés » et sur son absence totale de résultats.
Pourtant, peut-on parler d’erreur scientifique ?
🇫🇷 Pour Mathieu Triclot, philosophe à l’université Lyon 3, oui et son papier utilise la cybernétique pour illustrer le concept d’erreur scientifique.
❌ La cybernétique n’est pas critiquée pour ses mauvais résultats, un scientifique qui se trompe n’est pas dans l’erreur, il participe à la science ! C’est bien l’absence de résultats malgré l’entêtement des cybernéticiens qui est en cause.
❌ Seconde accusation, que les cybernéticiens en soient conscients ou non, leur discipline s’est largement éloignée de la discipline scientifique jusqu’à se mettre en porte-à-faux avec plusieurs de ses règles.
❌ Dernière accusation : A force d’analogies mal cadrés entre des disciplines dissemblables, la cybernétique a fini par ressembler à une idéologie scientifique (Canguilhem). Elle n’a produit que des visions du monde, pas des des preuves scientifiques quelconques. Le propos ressemble à celui de Sokal et Bricmont dans leur célèbre livre.
✔️ Le papier a un intérêt pour nous : ne créons pas d’autres cybernétiques en montant en épingle un sujet de recherche par la seule force de la « hype ». L’interface homme-machine, l’homme augmenté, l’IA forte, la blockchain sont des sujets à risque.
SOURCES
Mathieu Triclot. La cybernétique à l’aune des sciences cognitives : une erreur scientifique ? . Journée d’études ”qu’est-ce qu’une erreur scientifique ?”, Université Lyon 3 Jean Moulin, May 2004, Lyon, France.
Sokal A., Bricmont J., Impostures Intellectuelles, 1997, Odile Jacob, Paris ISBN 978-2-7381-0503-5
Iterative and Incremental Development: A Brief History 🔗
💾 Histoire de l'informatique
·
🧮 Méthodes de développement
Je pensais avant cet article que la maturité de notre profession avait été atteinte dans les années 70. Il n’en est rien. En 1958, on savait faire de bons logiciels, avec une méthode proche d’eXtrem Programming.
Le programme Mercury en témoigne.
63 ans de perdus, on continue ou on change nos pratiques ?
SOURCE
Craig Larman and Victor R. Basili. 2003. Iterative and Incremental Development: A Brief History. Computer 36, 6 (June 2003), 47–56. DOI:10.1109/MC.2003.1204375
DOIs:
10.1109/MC.2003.1204375
How soon will we learn these software engineering lessons ? 🔗
💩 Cas d'échecs
·
💾 Histoire de l'informatique
Ce papier de 1979 constate que depuis 1961, le secteur du logiciel est incapable de réussir ses produits. En cause : délais déraisonnables, violation de la loi de Brooks, empilement de spécifications, management toxique, gestion de projet monobloc. En 2021 ? Rien n’a changé.
SOURCE
Barry W. Boehm, Software Engineering - As It Is (1979)
How do fixes become bugs ? 🔗
👌 Qualité logicielle
🐞 Certains bugs ne doivent surtout pas être résolus dans la précipitation, même s’ils bloquent une fonction vitale en production. Le risque que le hotfix soit un bug encore plus gros est bien trop grand.
C’est l’alerte levée par le papier, déjà ancien (2011) de Yin et al.
3️⃣ Ces familles de bugs tiennent en 3 lettres : CMS.
-Concurrency (Locks, Tasks, Sync, etc.)
-Memory (Allocation, Overflow, Pointers, etc.)
-Semantic (Application-specific)
Respectivement 40%, 14% et 17% des patchs devant résoudre ces bugs sont eux-mêmes buggés !
🔒 Pire, sur les verrous, sujet très dangereux en développement, les chercheurs ont noté que 14% des patchs venant corriger un bug introduit par un autre patch sont eux-mêmes buggés !
🧠 Testez vos bugs, Defect Testing évite énormément de problèmes sur ces sujets où nos cerveaux sont dépassés par la complexité du code.
SOURCE :
Zuoning Yin, Ding Yuan, Yuanyuan Zhou, Shankar Pasupathy, and Lakshmi Bairavasundaram. 2011. How do fixes become bugs? In Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering (ESEC/FSE ’11). Association for Computing Machinery, New York, NY, USA, 26–36. DOI: 10.1145/2025113.2025121
DOIs:
10.1145/2025113.2025121
Exploring the Influence of Identifier Names on Code Quality: An Empirical Study 🔗
🗣️ Nommage
Un nommage inadapté obscurcit le code, c’est entendu. Mais plus surprenant, un nommage inadapté est également un bon moyen de détecter les morceaux de code les plus buggés. Une équipe anglaise a établi une forte corrélation entre code mal fichu et nommage aux fraises.
🔙 Les chercheurs ne nous disent pas si un lien de cause à effet existe. J’émets pour ma part deux hypothèses :
🕸️ Hypothèse 1 : Dans un code mal nommé, les bugs ont plus d’endroits où se cacher.
🐖 Hypothèse 2 : Il faut chercher une cause commune en la personne du développeur incompétent. Celui qui nomme mal est aussi celui qui teste peu et laisse derrière lui beaucoup de bugs.
🧪 Si des chercheurs avancent sur le sujet, je vous ferai part des résultats !
SOURCE
Butler, Simon & Wermelinger, Michel & Yu, Yijun & Sharp, Helen. (2010). Exploring the Influence of Identifier Names on Code Quality: An Empirical Study. Proceedings of the Euromicro Conference on Software Maintenance and Reengineering, CSMR. 10.1109/CSMR.2010.27.
DOIs:
10.1109/CSMR.2010.27
Effective identifier names for comprehension and memory 🔗
🗣️ Nommage
·
🧠 Psychologie
🔤 On ne répétera jamais assez l’importance du nommage en développement. 70% du code est constitué d’identifiants qui, s’ils sont ésotériques, grèvent la vélocité des développements. Comment ? Deux papiers nous l’expliquent.
🧠 Le premier, rédigé en 2011 par un Italien et un Américain, met en évidence l’effet négatif des odeurs lexicales sur la localisation des concepts. Ce terme désigne le processus par lequel notre cerveau tente de mapper un artefact du code avec un concept (métier ou technique qu’il connaît), afin de comprendre sa place dans la logique globale.
❌ Des odeurs comme les abréviations excessives, les termes vagues, inconsistants, mal orthographiés ou employés brouillent les capacités de localisation des concepts.
📏 Le second, rédigé en 2007 par une équipe Britannique, fait le lien entre longueur des identifiants et mémoire. Il indique que les identifiants trop longs sont aussi néfastes que ceux trop courts. Des abréviations raisonnables sont meilleures que des identifiants complets si ces derniers sont trop longs.
♀️ Un élément surprenant est la plus grande capacité des femmes à retenir des abréviations.
🔎 Ni trop court, ni trop long, mais toujours d’une clarté irréprochable semble une bonne règle pour les identifiants.
SOURCES
Abebe, Surafel Lemma, Sonia Haiduc, Paolo Tonella and Andrian Marcus. “Lexicon Bad Smells in Software.” 2009 16th Working Conference on Reverse Engineering (2009): 95-99. DOI:10.1109/WCRE.2009.26
Lawrie, D., Morrell, C., Feild, H. et al. Effective identifier names for comprehension and memory. Innovations Syst Softw Eng3, 303–318 (2007). DOI:10.1007/s11334-007-0031-2
DOIs:
10.1109/WCRE.2009.26
·
10.1007/s11334-007-0031-2
Don't touch my code ! Examining the effects of ownership on software quality 🔗
🧠 Psychologie
·
🧮 Méthodes de développement
✅ La propriété collective du code (Collective Code Ownership, CCO) est une pratique voulant que chaque développeur se sente légitime pour modifier n’importe quelle partie du projet. C’est un modèle à forte appartenance de groupe. Établir une règle ne suffit pas, il faut lever des barrières psychologiques soulignées par la recherche.
CCO a un effet bénéfique direct sur plusieurs indicateurs :
1️⃣ La résilience, ça n’est pas pour rien que CCO fait partie du Sustainable Software Development. J’en parle ici : Sustainable Software Development through Overlapping Pair Rotation
2️⃣ La simplicité du code. Quand l’équipe n’arrive plus à connaître tout le code collectivement, CCO provoque un malaise facile à ressentir par les développeurs. Il est peut-être temps de faire le tri ou de diviser le projet en morceaux.
3️⃣ La taille de l’équipe. Quand l’équipe devient trop grande, la rotation des paires est mathématiquement impossible. Tant mieux, une équipe de développement semble psychologiquement limitée à 7 personnes.
4️⃣ L’intégration. CCO intègre mieux et plus vite les nouveaux développeurs. Pas besoin de phase d’intégration longue et improductive, le développeur fait son travail dès le premier jour, guidé par un collègue.
5️⃣ Les vitres brisées. C’est un cycle vertueux. Si tout le monde se sent impliqué, personne ne laissera de problèmes non résolus « à d’autres ». La dette technique s’accumulera moins. Le produit sera de meilleure qualité. Les développeurs s’y identifieront plus et en seront fiers. Donc ils seront plus impliqués. Etc.
📅 Je termine la série demain avec la mise en place du CCO et les barrières à lever.
SOURCES
Christian Bird, Nachiappan Nagappan, Brendan Murphy, Harald Gall, and Premkumar Devanbu. 2011. Don’t touch my code! examining the effects of ownership on software quality. In Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering (ESEC/FSE ’11). Association for Computing Machinery, New York, NY, USA, 4–14. DOI:10.1145/2025113.2025119
DOIs:
10.1145/2025113.2025119
Designing Software for Ease of Extension and Contraction 🔗
📜 Lois du développement
·
#️⃣ Façonnage de code
·
📐 Architecture
👴 Je continue de découvrir l’immense David Parnas, au travers d’un second article, sur la manière de concevoir des logiciels afin qu’ils soient facile à étendre et à réduire selon les impératifs client. Il date de 1979, c’est l’information la plus dingue vu l’actualité du papier.
Règles de design
📜 Parnas donne 4 règles permettant de garder une grande souplesse dans le design des logiciels :
1️⃣ Commencer par un monolithe. Créer un module à chaque décision de design importante afin d’encapsuler cette décision et de rendre facile le changement si elle s’avérait peu judicieuse.
2️⃣ Lister les éléments qui sont susceptibles de changer. S’assurer qu’ils sont absents des interfaces des modules que l’on conçoit.
3️⃣ Ne pas subdiviser son programmes en étapes d’un traitement. Privilégier la conception par « machines virtuelles », où chaque module masque la complexité de la couche inférieure en ne laissant filtrer que ce qui est utile à des tâches plus élevées.
4️⃣ Ne créer de dépendances que si elles sont utiles. Parnas entend par là que :
1) A est plus simple parce qu’il utilise B.
2) B n’est pas plus complexe si A l’utilise.
3) Il existe un programme utile incluant B, mais pas A
4) Il n’y a aucun programme utile contenant A, mais pas B.
Coûts de fonctionnement et de changement
💻 Nous connaissons tous la dynamique qui lie mémoire et CPU, de sorte que toute optimisation de l’un coûte de l’autre.
Le même type de relation existe entre coût de fonctionnement et coût du changement. Je reviens sur le papier de Parnas posté il y a une semaine, car il révèle des trésors nouveaux à chaque lecture.
📏 Un logiciel générique diffère d’un logiciel flexible. Le premier répond à plusieurs cas d’usage sans changement, alors que le second ne répond qu’à un cas d’usage mais peut être facilement adapté pour en couvrir d’autres.
👉 La généricité a un surcoût de fonctionnement (le logiciel est forcément plus gros), mais un coût de changement nul.
👉 La flexibilité a n’a aucun surcoût de fonctionnement, mais possède un coût de changement dépendant de la qualité de l’implémentation.
💰 Le choix entre généricité et flexibilité est (normalement) purement stratégique et économique. Ce qu’un logiciel gagne d’un côté il le perd de l’autre. C’est une conséquence probablement indépassable de la VIIIème loi de Lehman : dans ce complexe d’interactions homme-machine, tout est gouverné par des boucles de rétroaction.
SOURCE
Parnas, David. (1979). Designing Software for Ease of Extension and Contraction. Software Engineering, IEEE Transactions on. SE-5. 128- 138. 10.1109/TSE.1979.234169.
DOIs:
10.1109/TSE.1979.234169
Coverage is not strongly correlated with test suite effectiveness 🔗
🧪 Tests
🔬Arrêtez de scruter la couverture de vos tests ! C’est une perte de temps. Laura Inozemtseva et Reid Holmes ont sorti en 2014 un papier qui l’affirme, mais confirme aussi les résultats de nombreux autres chercheurs : une faible couverture prouve que les tests sont mauvais. Une forte couverture ne prouve pas qu’ils sont bons.
🎯 On retrouve ici une situation où la Loi de Goodhart s’applique : plus vous prenez le coverage comme un objectif, plus vous vous plantez.
Comment s’assurer d’avoir de bons tests ? En remettant le coverage à sa place.
✔️ Comparer le coverage actuel et le coverage précédent avant chaque commit permet de voir si le développeur n’a pas oublié de tester son code.
✔️ Sous les 80%, le coverage indique une forte dette de tests.
❌ Au-dessus de 80% la coverage ne signifie rien d’utile et le suivre peut même coûter cher, en augmentant artificiellement la taille du jeu de tests, qu’il faudra ensuite maintenir.
❌ Les méthodes de calcul du coverage longues ou élaborées n’ont pas démontré leur utilité. Allez au plus simple, si vous utilisez correctement le coverage, ça suffira.
SOURCES
Laura Inozemtseva and Reid Holmes. 2014. Coverage is not strongly correlated with test suite effectiveness. In Proceedings of the 36th International Conference on Software Engineering (ICSE 2014). Association for Computing Machinery, New York, NY, USA, 435–445. DOI:10.1145/2568225.2568271
DOIs:
10.1145/2568225.2568271
Concise and consistent naming 🔗
🗣️ Nommage
🇩🇪 Hier, j’ai parlé de nommage, sans définir comment obtenir des noms clairs. Ça tombe bien, j’ai déniché un papier de 2006 écrit par deux Allemands. Fidèles à leur tradition, ils donnent deux lignes de conduite : concision et consistance.
⚠️ Le papier est très dense, je vous en recommande la lecture, ce post ne fera que de le survoler.
⭐ La règle d’or : il doit exister une relation bijective entre les concepts manipulés et les noms utilisés. Pas de polysèmes, pas d’homonymes. Dédicace à mon vieux prof de MERISE Patrice LECUONA.
🥈 Règle n°2 : la consistence. Il faut éviter les homonymes et les synonymes, ainsi que toutes les figures de style qui font un bon poème. Lorsque l’on compose un identifiant en mêlant plusieurs concepts, ces derniers doivent exister dans le vocabulaire du projet et la relation parent-enfant doit être légitime.
🥉 Règle n°3 : la concision. Pas d’ajouts. Un identifiant doit reprendre le nom du concept qu’il contient, sans préfixes et autres rajouts dont les développeurs sont friands. Si l’identifiant désigne un type particulier d’un concept, le nom doit en être le reflet clair.
Le papier ne s’arrête pas à cela, il donne d’autres recommandations et conseils très utiles, ainsi que les ressorts psychologiques à l’oeuvre. Par souci de concision, je ne détaille pas plus et vous invite à le lire.
SOURCE
Deissenboeck, F., Pizka, M. Concise and consistent naming. Software Qual J14, 261–282 (2006). DOI: 10.1007/s11219-006-9219-1
DOIs:
10.1007/s11219-006-9219-1
Characterizing the Relative Significance of a Test Smell 🔗
🧪 Tests
🇧🇪 En travaillant sur un outil de détection des odeurs de test (Test Smells), 3 chercheurs belges ont produit une synthèse rigoureuse et claire de ce qu’est un bon test.
✅ Premier apport : ils ont synthétisé 9 critères depuis la littérature académique : Consistance, Nécessité, Maintenabilité, Répétabilité, Auto-validation, Isolation, Concision, Robustesse, Rapidité, Automatisation et Persistance.
✅ Second apport, ils proposent un méta-modèle décrivant la place des tests dans un système logiciel. Ce méta-modèle compte 8 concepts contraints par 9 définitions, exprimées informellement en langage naturel et formellement en notation mathématique.
🧭 C’est un excellent support de formation, mais également une lecture intéressante pour toute personne cherchant à raffiner ses tests.
SOURCE
Van Rompaey, Bart & Du Bois, Bart & Demeyer, Serge. (2006). Characterizing the Relative Significance of a Test Smell. 391-400. 10.1109/ICSM.2006.18.
DOIs:
10.1109/ICSM.2006.18
Analyses of Regular Expression Usage in Software Development 🔗
🎓 Thèse
·
#️⃣ Façonnage de code
Les expressions régulières (Regex) sont massivement utilisées, mais très peu testées car difficilement testables, donc d’une fiabilité douteuse.
Cette conclusion est celle de la thèse (2021) de Peipei Wang, une doctorante en informatique de Caroline du Nord.
Je conseille aux non-chercheurs la lecture des chapitres 1, 3, 4, 5.
Vous y apprendrez que :
-Dans la réalité, personne ne teste ces $*x% de regex (17% sur les projets open-source étudiés).
-Elles sont une importante source de bugs vicieux.
-Elles sont encore imparfaitement portables à travers les langages.
-Les outils pour correctement les tester sont encore peu diffusés (Rex pour ne citer que lui). Elles sont encore trop testées simplement par branch coverage ou statement coverage, ce qui est erroné.
-Les développeurs en ont peur et y touchent très rarement dans leur code. Lorsqu’ils y sont contraints (bug ou évolution), ile préfèrent les supprimer et les remplacer par un parser (ce qui n’est pas toujours une mauvaise solution d’ailleurs).
https://repository.lib.ncsu.edu/handle/1840.20/39015
Adoption challenges of CI/CD methodology in software development teams 🔗
🧮 Méthodes de développement
🔃L’intégration et le déploiement continus (CI/CD) ont du mal à entrer efficacement dans les pratiques des entreprises. Un professeur Sri Lankais analyse pourquoi et donne des pistes d’amélioration.
👉 En premier, l’équipe. Elle doit maîtriser un ensemble de pratiques comme les tests automatisés ou DevOps. Elle doit communiquer correctement et être capable de livrer régulièrement. Ce n’est souvent pas le cas, surtout si l’équipe est sous pression.
👉En second, de peu, le soutien des parties-prenantes. Un pipeline de CI/CD n’a aucun impact sur la productivité à court-terme et peut même ralentir les développements. C’est donc un investissement, qui doit être compris et accepté comme tel par tout le monde.
👉Sur la dernière marche du podium, le poids de l’existant. Un existant intestable ou compliqué à build changera le parcours d’adoption des outils de CI/CD en véritable enfer.
❗ Le premier comme le troisième point sont très dépendants du second. Si les parties prenantes acceptent d’investir sérieusement dans un démarche de CI/CD, alors elles mettront les moyens pour désendetter le code et former les équipes.
La balle n’est pas dans le camp des développeurs, même avec la meilleure volonté du monde.
SOURCE
Rajasinghe, Maneka (2021): Adoption challenges of CI/CD methodology in software development teams. TechRxiv. Preprint. DOI:10.36227/techrxiv.16681957.v1
DOIs:
10.36227/techrxiv.16681957.v1
A New Family of Software Anti-Patterns: Linguistic Anti-Patterns 🔗
🧩 Design (Anti-)Patterns
·
#️⃣ Façonnage de code
·
🗣️ Nommage
👅Le code n’est pas écrit pour les machines, qui se contentent de signaux électriques, mais pour les humains ! Il est donc normal de retrouver des antipatterns linguistiques et autres dettes de langage dans un code.
4 chercheurs ont tenté de classifier les antipatterns linguistiques dans le code. Ils ont trouvé 6 familles, 3 pour les attributs, 3 pour les méthodes.
1) Les méthodes qui font plus qu’elles ne disent (effets de bord).
2) Les méthodes qui disent plus qu’elles ne font.
3) Les méthodes qui font l’opposé de ce qu’elles disent.
4) Les attributs dont le nom promet plus qu’ils ne contiennent
5) Les attributs qui contiennent plus que ce que promet leur nom
6) Les attributs qui contiennent l’opposé de ce qu’indique leur nom
Ces familles contiennent des antipatterns, comme ces Get impurs qui sont bien plus que des accesseurs, ces ‘IsX’ qui renvoient autre chose qu’un booléen, ces commentaires qui contredisent ce qu’ils illustrent ou encore ces méthodes de transformation qui ne retournent rien.
Bien entendu leur travail n’est qu’un premier pas, il existe de nombreux autres antipatterns, sur les noms des classes par exemple. Mais il a le mérite de lancer le sujet, inexploré avant eux.
SOURCE
Arnaoudova, Venera & Di Penta, Massimiliano & Antoniol, Giuliano & Guéhéneuc, Yann-Gaël. (2013). A New Family of Software Anti-Patterns: Linguistic Anti-Patterns. Proceedings of the European Conference on Software Maintenance and Reengineering, CSMR. 10.1109/CSMR.2013.28.
DOIs:
10.1109/CSMR.2013.28
A Brief History of Software Engineering 🔗
💾 Histoire de l'informatique
👴 Mes lectures de la semaine ont été bien plus historiques et sapientiales que scientifiques. Aujourd’hui, un brève histoire du logiciel de Niklaus Wirth.
🧪 Dans ce papier désabusé et volontiers sarcastique, l’auteur retrace son expérience du développement depuis les années 60. C’est décapant, mais non moins juste.
N. Wirth, “A Brief History of Software Engineering,” in IEEE Annals of the History of Computing, vol. 30, no. 3, pp. 32-39, July-Sept. 2008, doi: 10.1109/MAHC.2008.33.
DOIs:
10.1109/MAHC.2008.33
Factors Limiting Industrial Adoption of Test Driven Development: A Systematic Review 🔗
🧪 Tests
·
🧑💼 Management
🇸🇪 TDD est bénéfique pour la qualité, j’en ai déjà parlé ici. Quels sont donc les facteurs qui limitent son adoption en entreprise ? Il y en a 7 selon 3 chercheurs suédois.
🐌 Sa lenteur en temps de développement initial. A nuancer, car TDD est plus rapide si l’on prend en compte le temps de maintenance dans le calcul.
🧠 Le manque de connaissances sur TDD, renforcé par sa contre-productivité entre les mains de novices.
📐 La légende voulant que TDD ne permette pas de design. Elle n’a jamais été étayée par la recherche ou par l’expérience des praticiens, pourtant elle reste ancrée dans la tête des managers.
🗜️ Le manque de compétences en tests. En effet, TDD requiert des développeurs qui savent déjà (bien) tester. Ce n’est pas souvent le cas en entreprise. La bonne nouvelle, c’est que l’on peut apprendre directement avec TDD.
🧲 De mauvaises implémentations de TDD, alors que l’on sait que TDD doit être correctement appliqué pour présenter des bénéfices clairs.
❌ Des limitations propres au domaine ou aux outils. Il est par exemple très difficile de tester des GUI en TDD.
🗑️ La présence de Code Legacy, que TDD ne sait pas traiter (il faut d’autres techniques pour ça).
💩 En conclusion : apprendre TDD n’améliore pas les performances à court terme et peut même les gréver. Il n’est pas possible de faire du « demi-TDD » sans en perdre tout l’intérêt. TDD est un investissement lourd qui ne paie qu’à long terme. Soit, selon Niklaus Wirth, l’inverse de la tendance de l’industrie depuis les années 70.
👉 Sans courage managérial, il ne faut attendre aucun bénéfice de TDD.
SOURCE
Causevic, Adnan & Sundmark, Daniel & Punnekkat, Sasikumar. (2011). Factors Limiting Industrial Adoption of Test Driven Development: A Systematic Review. Proceedings – 4th IEEE International Conference on Software Testing, Verification, and Validation, ICST 2011. 337-346. 10.1109/ICST.2011.19.
DOIs:
10.1109/ICST.2011.19
TDD est facile à enseigner 🔗
🧪 Tests
·
🧑🏫 Pédagogie
🎓 Enseigner TDD au étudiants dès le premier cours sur les tests donne des résultats encourageants ! C’est même moins difficile que de l’enseigner à des développeurs habitués à une démarche Test-Last.
🇺🇸 L’étude vient des U.S.A et compare deux groupes d’étudiants, l’un suivant la logique TDD, l’autre une démarche Test-Last plus classique. Ces étudiants n’ont jamais testé avant et ont été formés à cela en début d’expérience.
👻 Les chercheurs montrent que chez des novices, pratiquer TDD lève les peurs au sujet de cette méthode. L’apprentissage n’est pas plus difficile que celui d’une démarche Test-Last et les étudiants sont plus productifs. Aucun changement concernant la qualité du code n’est perceptible.
🍼 Cela rejoint mon expérience en formation : il est plus difficile de former à la mentalité TDD des développeurs pratiquant en Test-Last que des cerveaux vierges. L’apprentissage de TDD étant la principale barrière empêchant la pratique de se répandre, former « dès le berceau » semble présenter des avantages nets.
SOURCES
D. S. Janzen and H. Saiedian, « On the Influence of Test-Driven Development on Software Design, » 19th Conference on Software Engineering Education & Training (CSEET’06), 2006, pp. 141-148, doi: 10.1109/CSEET.2006.25.
Causevic, Adnan & Sundmark, Daniel & Punnekkat, Sasikumar. (2011). Factors Limiting Industrial Adoption of Test Driven Development: A Systematic Review. Proceedings – 4th IEEE International Conference on Software Testing, Verification, and Validation, ICST 2011. 337-346. 10.1109/ICST.2011.19.
DOIs:
10.1109/ICST.2011.19
·
10.1109/CSEET.2006.25
Two Meta-Analysises 🔗
🤝 Pair Programming
·
🧪 Tests
🔍 Les Méta-Analyses, plus haut niveau de preuves en science, sont assez rares en qualité logicielle. J’en ai une sur l’efficacité de TDD et l’autre sur le Pair Programming. Analysons-les ensemble.
⚠️ Ces deux analyses se rejoignent sur l’absence de standardisation des concepts étudiés et de la manière de les étudier, ce qui rend compliquée l’isolation des variables. Il est donc compliqué de conclure, sauf à avoir de très nombreuses études source.
❓ Rappel : « non concluant », « ne prouve rien » et autres formules de ce style signifient que rien ne peut être conclu. Ni l’efficacité, ni l’inefficacité.
🤝 Sur Pair Programming, des conclusions surprenantes : il est plus rapide d’être deux sur des tâches simples, mais la qualité va baisser. Sur des tâches complexes, être deux produira un meilleur code, au prix d’une baisse de productivité.
C’est contre-intuitif autant pour les partisans que pour les détracteurs de pair-programming. Cela signifierait que si la qualité compte, il est mieux de laisser les développeurs seuls sur les tâches simples. Si c’est la productivité qui compte, il faut pairer sur les plus triviales !
☑️ Sur TDD, il a un effet positif sur la qualité d’autant plus grand que la tâche est grande, en revanche, il n’a aucun résultat concluant sur la productivité. Ce résultat est plus appuyé dans l’industrie (probablement car les développeurs ont plus de bouteille qu’à l’université) et quand d’autres pratiques d’XP sont utilisées avec TDD.
🕰️ Sur ces deux sujets, les chercheurs déplorent l’absence de papiers sur les effets long-terme de ces deux techniques.
SOURCES
Y. Rafique and V. B. Mišić, « The Effects of Test-Driven Development on External Quality and Productivity: A Meta-Analysis, » in IEEE Transactions on Software Engineering, vol. 39, no. 6, pp. 835-856, June 2013, doi: 10.1109/TSE.2012.28.
Jo E. Hannay, Tore Dybå, Erik Arisholm, Dag I.K. Sjøberg, The effectiveness of pair programming: A meta-analysis, Information and Software Technology, Volume 51, Issue 7, 2009, Pages 1110-1122, ISSN 0950-5849, DOI:10.1016/j.infsof.2009.02.001
DOIs:
10.1109/TSE.2012.28
·
10.1016/j.infsof.2009.02.001
Are mutants a valid substitute for real faults in software testing 🔗
🧪 Tests
👾 Les indicateurs classiques de couverture du code ne sont pas corrélés à l’efficacité des tests*. En revanche, le score de mutation l’est significativement, pour un effort de tests moindre. Pourtant, malgré des outils efficaces, la mutation n’est pas une pratique courante en développement.
🔧 Ils se nomment Stryker en .NET, PIT ou Jumble en Java, mais tous les grands langages possèdent un outil de mutation simple d’utilisation. Les CPU modernes ainsi que les langages intermédiaires (MS IL, Bytecode) rendent ces outils suffisamment rapides pour les faire tourner avant chaque commit en mode partiel, et à chaque intégration en mode complet. Pourtant ils demeurent largement méconnus des développeurs.
🪄 Il ne s’agit pas d’une technique parfaite (No Silver Bullet, rappelez-vous). Ils ne détectent que les bugs issus du code, pas les problèmes d’algorithmique et les effets de bord complexes, mais c’est déjà énorme vu le très faible investissement qu’ils représentent.
💻 Intégrés dans un IDE ou dans une plateforme de CI, ils dévoilent tout leur potentiel et sont le complément parfait de TDD. Essayez, vous serez rapidement conquis !
* Voir le post d’il y a 6 jours : Coverage is not strongly correlated with test suite effectiveness
SOURCES
N. Li, U. Praphamontripong and J. Offutt, « An Experimental Comparison of Four Unit Test Criteria: Mutation, Edge-Pair, All-Uses and Prime Path Coverage, » 2009 International Conference on Software Testing, Verification, and Validation Workshops, 2009, pp. 220-229, doi: 10.1109/ICSTW.2009.30.
René Just, Darioush Jalali, Laura Inozemtseva, Michael D. Ernst, Reid Holmes, and Gordon Fraser. 2014. Are mutants a valid substitute for real faults in software testing? In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE 2014). Association for Computing Machinery, New York, NY, USA, 654–665. DOI:10.1145/2635868.2635929
DOIs:
10.1109/ICSTW.2009.30
·
10.1145/2635868.2635929
Une revue sur les odeurs du code 🔗
🦨 Code Smells
·
🧩 Design (Anti-)Patterns
🦨 Odeur du code ! Antipattern ! Si le capitaine Haddock était développeur, il abuserait sans doute d’un tel vocabulaire. Mais qu’en est-il de la recherche ? Ces notions sont-elles pertinentes, ou juste des caprices de développeurs ?
📝 J’ai récupéré 5 papiers, écrits entre 2009 et 2013, qui en parlent. Pour être d’accord sur la définition, une odeur du code est une indication d’un potentiel problème plus profond, l’antipattern. Fowler, qui a inventé le terme, différencie bien les deux. L’antipattern est une mauvaise solution clairement identifiée. L’odeur est un indice, ne menant pas toujours à un antipattern. Et tous les antipatterns ne « sentent » pas, certains ne sont visibles que via une analyse poussée.
🐛 Dans la littérature, les classes porteuses d’odeurs sont en général plus défectueuses et moins compréhensibles que les autres.
Cependant, les études se contredisent sur leur résistance et leur exposition au changement, qui s’explique au moins partiellement par leur plus grande taille, une variable mieux corrélée que le nombre d’odeurs à ces indicateurs.
💣 Les antipatterns sont moins étudiés, mais semblent corrélés à un plus grand nombre d’erreurs et une plus grande exposition au changement. En d’autres termes, ils changent plus souvent et leurs changements sont plus véreux que la moyenne.
🔄 La recherche montre également que toutes les odeurs ne se valent pas, certaines sont faiblement corrélées à des antipatterns, d’autres très fortement.
✔️ En résumé, les code smells indiquent bien quelque chose sur la qualité du code, mais ils ne peuvent pas se passer d’une analyse des développeurs ! Fowler a vu juste, comme souvent.
SOURCES
D. I. K. Sjøberg, A. Yamashita, B. C. D. Anda, A. Mockus and T. Dybå, “Quantifying the Effect of Code Smells on Maintenance Effort,” in IEEE Transactions on Software Engineering, vol. 39, no. 8, pp. 1144-1156, Aug. 2013, doi: 10.1109/TSE.2012.89.
Steffen M. Olbrich, Daniela S. Cruzes, and Dag I. K. Sjoberg. 2010. Are all code smells harmful? A study of God Classes and Brain Classes in the evolution of three open source systems. In Proceedings of the 2010 IEEE International Conference on Software Maintenance. DOI:10.1109/ICSM.2010.5609564
Bavota, Gabriele & Qusef, Abdallah & Oliveto, Rocco & Lucia, Andrea & Binkley, David. (2012). An empirical analysis of the distribution of unit test smells and their impact on software maintenance. IEEE International Conference on Software Maintenance, ICSM. 56-65. 10.1109/ICSM.2012.6405253
F. Khomh, M. Di Penta and Y. Gueheneuc, « An Exploratory Study of the Impact of Code Smells on Software Change-proneness, » 2009 16th Working Conference on Reverse Engineering, 2009, pp. 75-84, doi: 10.1109/WCRE.2009.28.
Li, Wei and Raed Shatnawi. “An empirical study of the bad smells and class error probability in the post-release object-oriented system evolution.” J. Syst. Softw. 80 (2007): 1120-1128. DOI:10.1016/j.jss.2006.10.018
DOIs:
10.1109/TSE.2012.89
·
10.1109/ICSM.2012.6405253
·
10.1109/WCRE.2009.28
·
10.1109/ICSM.2010.5609564
·
10.1016/j.jss.2006.10.018
Localisation des concepts et langage métier 🔗
🧠 Psychologie
·
🗣️ Nommage
🧠 Connaissez-vous le principe de localisation des concepts (Concept Location) ? Il s’agit d’une notion à la frontière de la psychologie et de l’informatique, qui désigne l’acte de retrouver le code implémentant un concept donné dans un programme. Une localisation efficace augmente grandement la productivité des développeurs.
🗣️ La principale difficulté est l’écart entre le langage naturel utilisé pour exprimer le concept et la terminologie utilisée dans le code. Plus le code est rédigé dans un langage proche du métier, plus la localisation des concepts est aisée.
👓 La connaissance du code par le développeur facilite évidemment la localisation, plus la compréhension du code par les développeurs est étendue, plus la localisation est rapide.
🧪 Enfin, des tests placés au bon niveau d’abstraction aident évidemment à repérer les concepts facilement.
🔥 Je ne peux que recommander le combo DDD+ATDD+Architecture criante pour maximiser la productivité sur des projets où le nombre de concepts est important.
SOURCES
Evans E., Domain-Driven Design: Tackling Complexity in the Heart of Software, Addison-Wesley, ISBN: 0-321-12521-5
Marcus, Andrian & Sergeyev, A. & Rajlich, Vaclav & Maletic, J.I.. (2004). An information retrieval approach to concept location in source code. Proceedings – Working Conference on Reverse Engineering, WCRE. 214 – 223. 10.1109/WCRE.2004.10.
DOIs:
10.1109/WCRE.2004.10
An Exploratory Study of Factors Influencing Change Entropy 🔗
📜 Lois du développement
·
👌 Qualité logicielle
🔀 L’entropie de Shannon, désigne la quantité d’informations qu’une source émet, donc l’incertitude concernant ce qu’elle va émettre. De même, l’entropie d’un logiciel mesure le niveau de complexité d’un code, donc son incertitude.
🔬 L’idée d’appliquer l’entropie de Shannon comme mesure logicielle vient de Warren Harrison, dans un papier de 1992. L’idée a fait du chemin, jusqu’à devenir un Leprechaun, comme à l’accoutumée.
🤌 Aujourd’hui, un papier publié en 2010 par 4 Italiens, qui analyse les facteurs qui influencent l’entropie du logiciel.
➕Le refactoring semble être le seul moyen de juguler l’entropie, voire de la réduire.
➖Plus il y a de développeurs successifs sur un morceau de code, plus l’entropie augmente vite.
〰️L’usage de patterns n’a aucun effet sur la progression de l’entropie.
SOURCES
C. E. Shannon, A Mathematical Theory of Communication, Bell system Technical Journal, 1948, DOI:10.1002/j.1538-7305.1948.tb01338.x
Harrison, Warren. “An Entropy-Based Measure of Software Complexity.” IEEE Trans. Software Eng. 18 (1992): 1025-1034. DOI:10.1109/32.177371
G. Canfora, L. Cerulo, M. Di Penta and F. Pacilio, « An Exploratory Study of Factors Influencing Change Entropy, » 2010 IEEE 18th International Conference on Program Comprehension, 2010, pp. 134-143, doi: 10.1109/ICPC.2010.32.
DOIs:
10.1109/ICPC.2010.32
·
10.1109/32.177371
·
10.1002/j.1538-7305.1948.tb01338.x
Qu'est-ce que l'appartenance du code ? 🔗
🧠 Psychologie
·
🧮 Méthodes de développement
🔏 L’appartenance du code désigne le sentiment de responsabilité d’un développeur ou d’une équipe sur un morceau de code. Une forte appartenance est corrélée avec un plus faible nombre de défauts.
⛓️ La forte appartenance désigne un modèle où un code est presque exclusivement édité par ses contributeurs majeurs, à savoir des développeurs s’identifiant comme experts sur cette partie précise du logiciel.
Elle s’oppose à la faible appartenance, où la part des modifications réalisées par des contributeurs mineurs est grande.
Il existe également un phénomène de non-appartenance, désignant l’abandon de parties entières du code, assimilable au code legacy.
🪲 Dans leur étude de 2011, Bird et al. démontrent qu’un modèle de faible appartenance provoque plus de défauts, principalement à cause du manque de connaissance métier des contributeurs mineurs. La littérature précédente appuie ce point : la productivité d’un développeur dépend bien plus de la connaissance du métier de de son expérience précédente.
🧠 Sedano et al. reprennent ces résultats en prenant en compte les critiques de Brendan Murphy : le lien entre qualité et appartenance n’est pas seulement causé par la connaissance du métier, mais également par la psychologie. Un développeur ayant le sentiment d’être responsable d’un code y prêtera plus d’attention car il s’y identifiera (Quality with a Name).
📐 Délimiter arbitrairement des « parties du code » et nommer des responsables n’a qu’un effet très marginal sur la qualité et augmente le Facteur Bus, donc le risque projet !
✔️ Combattre l’apathie logicielle suppose la compréhension des ressorts psychologiques derrière le sentiment d’appartenance. Ultimement, Sedano et al. défendent la propriété collective du code comme une pratique vertueuse, mais la démonstration est pour demain !
— SOURCES —
Todd Sedano, Paul Ralph, and Cécile Péraire. 2016. Practice and perception of team code ownership. In Proceedings of the 20th International Conference on Evaluation and Assessment in Software Engineering (EASE ’16). Association for Computing Machinery, New York, NY, USA, Article 36, 1–6. DOI:10.1145/2915970.2916002
Christian Bird, Nachiappan Nagappan, Brendan Murphy, Harald Gall, and Premkumar Devanbu. 2011. Don’t touch my code! examining the effects of ownership on software quality. In Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering (ESEC/FSE ’11). Association for Computing Machinery, New York, NY, USA, 4–14. DOI:10.1145/2025113.2025119
B. Murphy Code ownership more complex to understand than research implies. Software, IEEE, 32(6):19, Nov 2015
J. Shore, Quality With a Name, 2006
DOIs:
10.1145/2025113.2025119
·
10.1145/2915970.2916002
A rational design process: How and why to fake it 🔗
🧮 Méthodes de développement
🧮 Errare humanum est, dit la locution. Les auteurs ne croyaient déjà pas à la possibilité d’une méthode formelle de développement logiciel en 1986. Nous ne seront jamais des mathématiciens déduisant un théorème à partir d’axiomes, car si le logiciel est écrit dans un langage strict, son objet est ô combien humain.
📚 Parnas et Clements soutiennent cependant l’utilité de feindre la rationalité, autrement dit de produire au cours du projet la même qualité de documentation que celle qui aurait été nécessaire pour produire un logiciel valide du premier coup. C’est un effort substantiel, mais payant selon eux.
📑 Quelles sont les propriétés d’une bonne documentation ? Elle est organisée hiérarchiquement afin d’optimiser la recherche d’informations, non l’écriture. Elle contient le moins possible de prose, remplacée par des diagrammes, schémas, formules, etc. Elle est complète et ne contient qu’une seule fois chaque information. Elle utilise des espaces de noms pour éviter la confusion de termes équivoques.
✅ Toutes ces propriétés se retrouveront 20 ans plus tard dans les recommandations pour écrire de bons tests d’acceptation : il n’y a pas de mystère, un test d’acceptation n’est pas autre chose qu’une documentation exécutable.
SOURCE
David Lorge Parnas and Paul C. Clements. 2001. A rational design process: how and why to fake it. Software fundamentals: collected papers by David L. Parnas. Addison-Wesley Longman Publishing Co., Inc., USA, 355–368. DOI:10.1109/TSE.1986.6312940
📄 Lien public
DOIs:
10.1109/TSE.1986.6312940